Todo ano os cientistas de dados do Spotify criam uma retrospectiva musical dos seus usuários. Essa apresentação é compartilhada por muitas pessoas nas redes sociais, que debatem acerca das suas preferências. A plataforma permite o acesso a alguns destes dados por meio de uma API. Para acessa-la com facilidade, podemos utilizar o pacote {spotifyr}.
Primeiramente, deve ser feito um cadastro no site do Spotify (https://developer.spotify.com/). Assim, podemos obter a chave pessoal para acessar a API. Basta colocar o ID e essa chave da seguinte maneira:
library(tidyverse) library(spotifyr) library(ggridges) Sys.setenv(SPOTIFY_CLIENT_ID = 'xxxxxxxx') Sys.setenv(SPOTIFY_CLIENT_SECRET = 'xxxxxxx') access_token <- get_spotify_access_token()
Existem várias funções diferentes que podemos fazer neste pacote. Podemos obter características sonoras, datas de lançamento, popularidade, entre outras coisas. É possível também obter seus próprios dados de consumo. Por exemplo, a função "get_my_saved_albuns", retorna todos os álbuns das músicas que você curtiu. Esta função possui um limite de 50 álbuns, assim como outras semelhantes. Assim é preciso utilizar um loop para obter todos os seus álbuns.
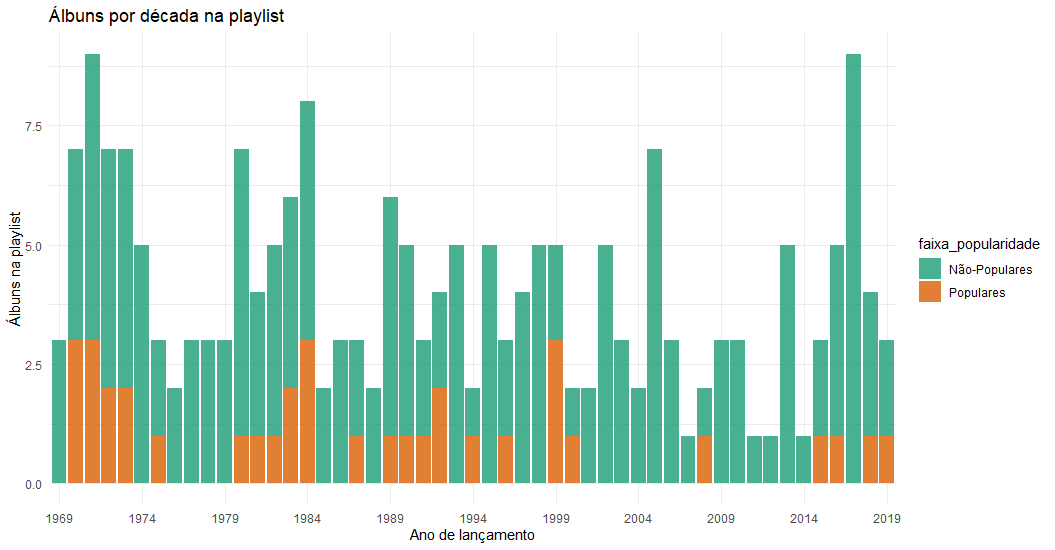
No caso, selecionei os meus álbuns com as variáveis de data de lançamento e popularidade. Com esta categoria, criei uma variável binária para separar os álbuns entre populares e não-populares, utilizando um limite de 50 na escala do aplicativo.
lista = list()
for (i in seq(0,10)){
x = i*50
lista[[i+1]] <- get_my_saved_albums(limit = 50, offset = x)
if (nrow(lista[[i+1]]) < 50){
break
}
}
meus_albuns <- bind_rows(lista, .id = "column_label") %>%
select(album.artists, album.name, album.popularity, album.release_date) %>%
mutate(album.release_date = stringr::str_extract(album.release_date, "^.{4}")) %>%
mutate(faixa_popularidade = ifelse(album.popularity > 50,"Populares", "Não-Populares"))
Assim, é possível criar um gráfico para observar o seu gosto em relação aos anos de lançamento.
ggplot(meus_albuns) +
geom_histogram(aes(x = album.release_date, fill = faixa_popularidade),stat="count", alpha = 0.8) +
theme_minimal() +
scale_x_discrete(breaks=seq(1969, 2020, 5)) +
scale_fill_brewer(palette = "Dark2") +
ylab("Álbuns na playlist") +
xlab("Ano de lançamento")
Outra possibilidade interessante é extrair informações de bandas ou gêneros específicos. Podemos, por exemplo, selecionar a banda Pearl Jam para analisar alguma característica sonora do conjunto. Um dado interessante é observar a chamada "valência" das músicas. Basicamente, a valência descreve a positividade musical de uma canção. Músicas com valência mais altas soam mais positivas.
Assim, selecionamos os álbuns de estúdio da banda para acompanhar a distribuição das músicas pela valência, que parece aumentar ao longo dos anos.
PJ <- get_artist_audio_features('Pearl Jam') %>%
mutate(ano_album = paste0(album_release_year, " - ", album_name)) %>%
filter(album_name %in% c("Ten", "Vs.", "Vitalogy", "No Code",
"Yield", "Binaural", "Riot Act",
"Pearl Jam", "Backspacer", "Lightning Bolt",
"Gigaton"))
ggplot(PJ, aes(x = valence, y = ano_album, fill = ano_album)) +
geom_density_ridges(alpha = 0.5, jittered_points = TRUE) +
theme_ridges() +
guides(fill=FALSE,color=FALSE) +
ggtitle("Valência dos álbuns do Pearl Jam")


________________________
(*) Para entender mais sobre a linguagem R e suas ferramentas, confira nosso Curso de Introdução ao R para análise de dados.

