Ao longo dos últimos dias, tenho publicado nesse espaço alguns posts e exercícios sobre a pandemia do coronavírus. Ontem, a propósito, publiquei o comentário de conjuntura dessa semana com um modelo SIR ajustado aos dados da doença no Brasil. Como é possível observar nesse exercício, o Brasil está no início da transmissão, com um crescimento exponencial dos casos confirmados.
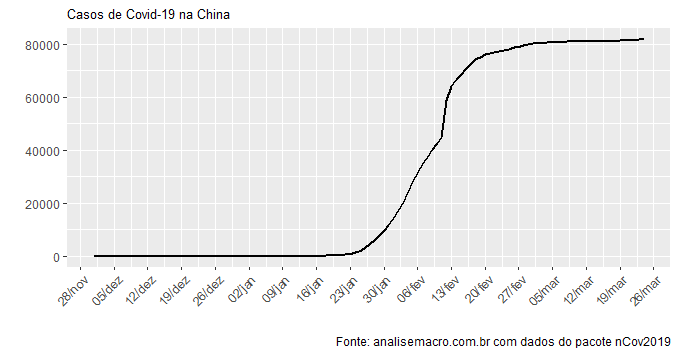 Se olharmos, contudo, para os dados da China, primeiro país exposto à pandemia, a curva de casos confirmados parece seguir um formato logístico. Isso, a propósito, está em linha com a tese de "imunidade de grupo", ou seja, quanto mais pessoas vão sendo expostas ao vírus, mais pessoas ganham imunidade e a contaminação passa a desacelerar.
Se olharmos, contudo, para os dados da China, primeiro país exposto à pandemia, a curva de casos confirmados parece seguir um formato logístico. Isso, a propósito, está em linha com a tese de "imunidade de grupo", ou seja, quanto mais pessoas vão sendo expostas ao vírus, mais pessoas ganham imunidade e a contaminação passa a desacelerar.
As curvas em formato de sino que têm sido divulgadas por aí, nesse aspecto, derivam justamente do modelo SIR, onde as pessoas são "compartimentadas" nos grupos de suscetíveis, infectados e recuperados. Ou seja, as pessoas saem de um para outro grupo, daí o formato da curva.
O formato logístico, por seu turno, não significa que devemos simplesmente abandonar as medidas de distanciamento social. Isso porque, quanto mais pessoas forem expostas ao vírus, mais casos graves serão registrados, o que tende a congestionar o sistema de saúde, como temos visto na Itália.
A pergunta de um trilhão de reais, portanto, é onde é o "limite superior" da curva logística.
(*) Isso e muito mais você aprende no nosso Curso de Microeconometria usando o R.
___________

