Algo que sempre gera dúvidas para aqueles que estão entrando na área de dados refere-se as áreas de atuação, bem como a relação entre cada uma. Obviamente, Estatística não é o mesmo que Data Analytics, bem como também são diferentes de Data Science. Apesar disto, estão totalmente interligadas. No post de hoje, explicamos brevemente as diferenças das três áreas e aplicamos exemplos de demonstração de suas finalidade.
Para esclarecer toda a confusão que é gerada sobre as áreas, definimos brevemente da seguinte forma:
- Estatística é uma área que está mais preocupada com os métodos de coleta, analise e apresentação dos dados. O objetivo é buscar o relacionamentos de variáveis, descrever suas características e ser cuidadosa na área de inferência e criação de hipóteses.
- Data Analytics é uma área que não está preocupada com os métodos de avaliação das variáveis (sendo menos rigorosos que a estatística), e sim está mais preocupado com os resultados que se encontram com os objetivos do negócios. Deste modo, por mais que certas características são significativas em um estudo estatísticos, para o DA, isto pode ser inútil caso não agregue valor para o negócio.
- Data Science está também interligado com a estatística, porém é focada em resultados, isto é, o Cientista de Dados está preocupado com os objetivos do negócio em mente, de forma a criar produtos sofisticados, com algoritmos que predizem variáveis dentro de um sistema que gera essas previsões instantaneamente. A sua utilização é muito interligada com o uso de Machine Learning.
É possível baixar os dados através do seguinte link.
Vamos investigar a relação entre duas variáveis do dataset: mpg e origin. O quanto a origem do carro pode estar relacionada a variação de mpg? E se confirmada essa relação, além de origin, quais variáveis podemos adicionar para criar um modelo de previsão?
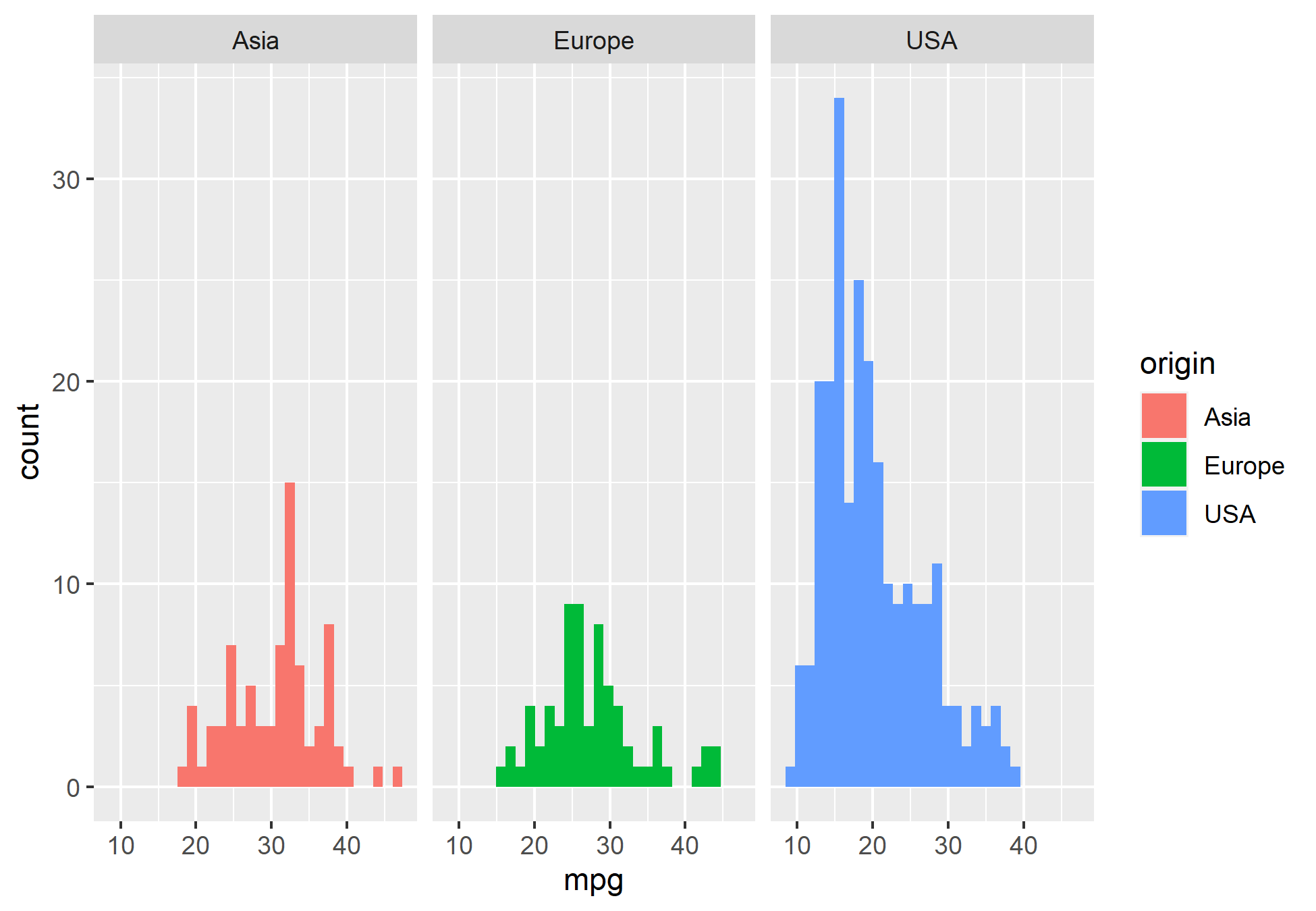
Primeiro, analisamos a distribuição de mpg por origem do carro por meio de um histograma. Observamos que o número de carros construídos no EUA são maiores em relação a Asia e Europa. Além disso, vemos onde os dados estão centralizado, bem como as assimetrias que se formam.
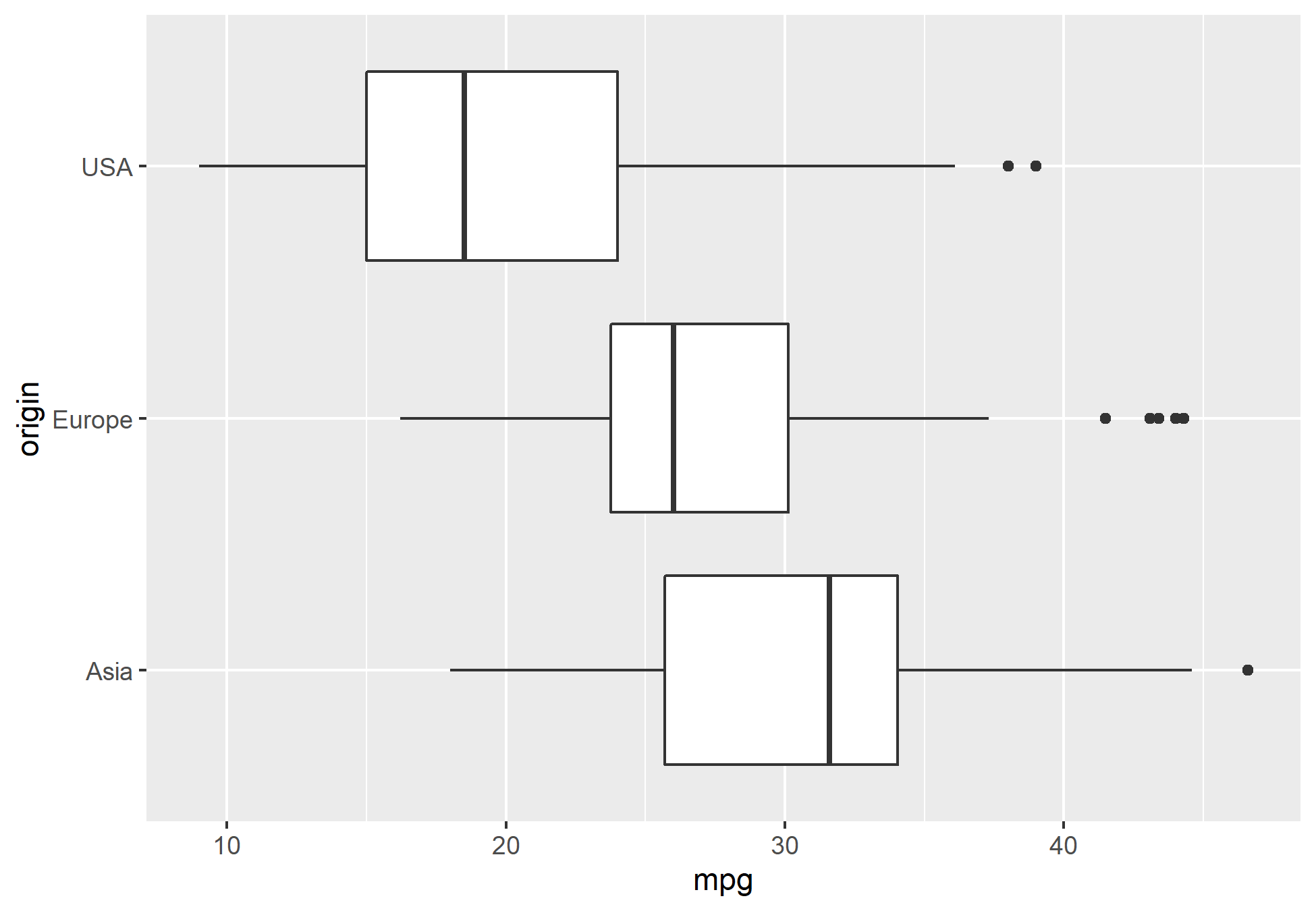
 Com um boxplot, podemos entender melhor os percentis dos valores de mpg por origem. Vemos que Asia possui uma mediana de mpg maior que Europa e EUA.
Com um boxplot, podemos entender melhor os percentis dos valores de mpg por origem. Vemos que Asia possui uma mediana de mpg maior que Europa e EUA.
 Com os insights retirado dos gráficos, podemos descobrir se a variável origin exerce uma influência na variável dependente.
Com os insights retirado dos gráficos, podemos descobrir se a variável origin exerce uma influência na variável dependente.
Obviamente, a análise estatística é mais robusta e preciosista, com a formulação de um objetivo de estudo e criação de testes de hipóteses. Aqui, fizemos um simples passeio sobre o conteúdo que a área trata.
A partir daqui, iremos estar concentrados em prever o mpg do carro utilizando a regressão linear. A questão, é que o nosso objetivo aqui não será buscar de fato buscar relacionamentos estatísticos, e sim entregar uma previsão de mpg dos carros (e aqui apenas lidaremos com o workflow do {tidymodels}, e não trataremos de toda a infraestrutura criada por um time de Data Science). O objetivo de ensino aqui será somente diferenciar os objetivos de uma área para a outra.
Com as considerações feitas, podemos prosseguir com o nosso modelo. Além de origin, vamos adicionar outra variável, que será weight.
Podemos ver a relação através de um gráfico de dispersão.

Ao especificar e rodar o modelo, construímos as previsões com a fução predict() e comparamos os resultados com os dados de teste.
Quer saber mais?
Veja nossos cursos de R e Python aplicados para a Análise de Dados e Economia
- R para Análise de Dados
- Python para Análise de Dados
- Gráficos com ggplot2
- Estatística usando R e Python
- Machine Learning usando o R
_____________________________________________

