Com o avanço da pandemia do coronavírus, muitas consultorias e departamentos de research têm avançado na busca de dados de "alta frequência" para quantificar os seus efeitos sobre a economia. Os dados do google como o Google Trends e de geolocalização têm sido cada vez mais utilizados de forma a quantificar os efeitos da peste sobre o nível de atividade.
Como já tratei várias vezes nesse espaço, os dados do google podem ser inclusive utilizados para forecasting de variáveis econômicas. Um exemplo dessa abordagem é visto na edição 68 do Clube do Código, que busca replicar o paper The predictive power of google search in forecasting US unemployment, publicado no International Journal of Forecasting, para o Brasil.
Nesse paper e no exercício, utilizamos a pesquisa pela palavra "emprego" como uma das variáveis que explicariam o avanço da taxa de desemprego ao longo do tempo.
Na situação atual, contudo, talvez seja interessante pesquisar por outros termos, como, por exemplo, "seguro desemprego". Podemos para isso utilizar o pacote gtrendsR para fazer a pesquisa e os pacotes tidyverse para tratar e visualizar os dados.
Uma dica aqui é que a versão disponível no CRAN não rodou para mim. Tive que instalar a versão disponível no github. Para isso, você pode rodar a linha de comando abaixo.
if (!require("devtools")) install.packages("devtools")
devtools::install_github("PMassicotte/gtrendsR")
Uma vez instalado o pacote, podemos pegar tanto as buscas por "emprego" quanto "seguro desemprego", como no código abaixo.
data_gtrends = gtrends(keyword = c("seguro desemprego", 'emprego'),
geo = "BR", time='all', onlyInterest=TRUE)
De posse dos dados, nós selecionamos e mensalizamos as buscas por "seguro desemprego".
seguro_desemprego = data_gtrends$interest_over_time %>% filter(keyword == 'seguro desemprego') %>% mutate(mes = floor_date(date, "month")) %>% group_by(mes) %>% summarize(interesse = mean(hits)) %>% mutate(date = as.Date(mes)) %>% select(date, interesse)
Por fim, podemos gerar um gráfico com o ggplot2 como abaixo.
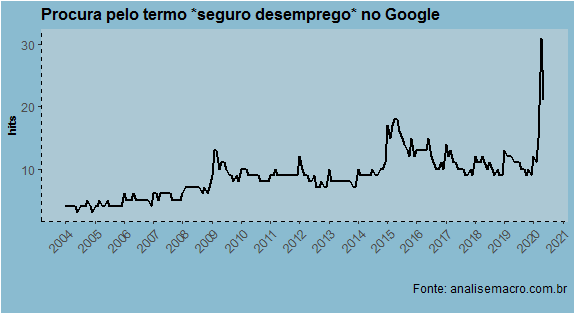
Como esperado, há um forte aumento em abril nas pesquisas por "seguro desemprego".
__________________
(*) Aprenda R em nosso Curso de Introdução ao R para Análise de Dados.


