No Hackeando o R de hoje, iremos dar uma olhada em um pacote que facilita a obtenção de dados das eleições brasileiras, importando dados direto do TSE com variáveis interessantes para a análise de dados. O pacote {electionsBR} oferece diversas funções que facilitam a obtenção desses dados. No post de hoje, iremos investigar as funções do pacote.
O pacote oferece uma sintaxe simples para o uso de suas funções. Como argumento, necessitam somente do ano de interessante, e se houver, a sigla do estado de interesse.
# install.packages("electionsBR)
library(electionsBR)
library(tidyverse)
Para saber como as funções utilizam as siglas das unidades federativas, pode utilizar a seguinte função.
# Retorna um vetor de siglas dos estados uf_br()
As funções party_mun_zone_fed e party_mun_zone_local, coleta os dados eleitorais por partidos, desagregados por eleitores. A primeira função coleta dados das eleições federais, enquanto a segunda, importa dados das eleições locais.
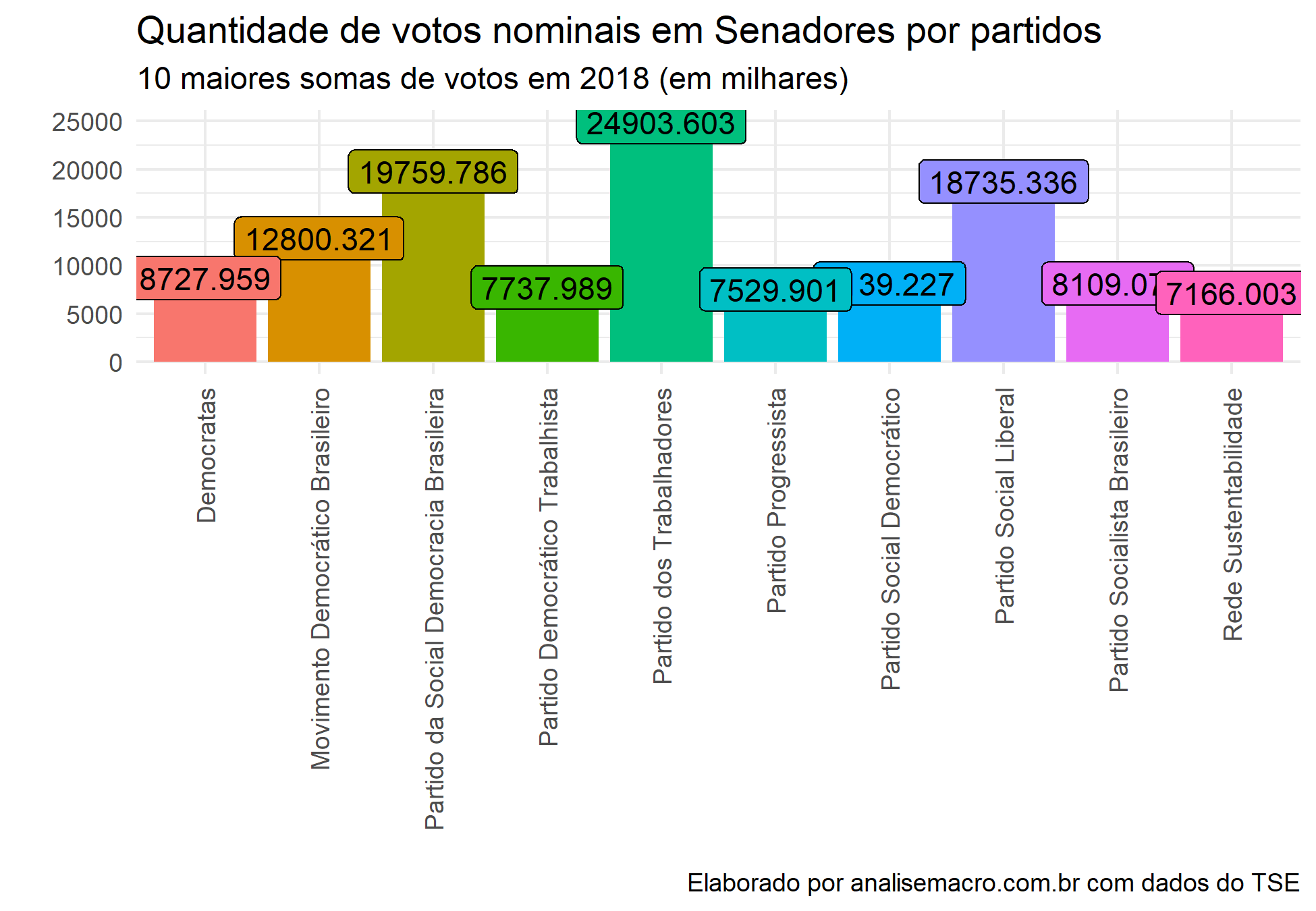
# coleta os dados das eleições federais election_fed <- party_mun_zone_fed(2018) election_fed %>% select(DESCRICAO_ELEICAO, DESCRICAO_CARGO, NOME_PARTIDO, QTDE_VOTOS_NOMINAIS) %>% filter(DESCRICAO_CARGO == "Senador") %>% group_by(NOME_PARTIDO) %>% summarise(soma_votos = sum(QTDE_VOTOS_NOMINAIS)) %>% arrange(desc(soma_votos)) %>% slice(1:10) %>% ggplot(aes(x = NOME_PARTIDO, y = soma_votos, fill = NOME_PARTIDO, label = soma_votos))+ geom_bar(stat = "identity")+ geom_label(color = "black")+ labs(title = "Quantidade de votos nominais em Senadores por partidos", subtitle = "10 maiores somas de votos em 2018", x = "", y = "", caption = "Elaborado por analisemacro.com.br com dados do TSE")+ theme_minimal()+ theme(legend.position = "none", axis.text.x = element_text(angle = 90, vjust = 0.5, hjust=1))
 # Coleta os dados das eleições municipais election_mun <- party_mun_zone_local(2020) election_mun %>% select(DESCRICAO_CARGO, NOME_PARTIDO, QTDE_VOTOS_NOMINAIS) %>% filter(DESCRICAO_CARGO == "Prefeito") %>% group_by(NOME_PARTIDO) %>% summarise(soma_votos = sum(QTDE_VOTOS_NOMINAIS)) %>% arrange(desc(soma_votos)) %>% slice(1:10) %>% ggplot(aes(x = NOME_PARTIDO, y = soma_votos, fill = NOME_PARTIDO, label = soma_votos))+ geom_bar(stat = "identity")+ geom_label(color = "black")+ labs(title = "Quantidade de votos nominais em Prefeitos por partidos", subtitle = "10 maiores somas de votos em 2020", x = "", y = "", caption = "Elaborado por analisemacro.com.br com dados do TSE")+ theme_minimal()+ theme(legend.position = "none", axis.text.x = element_text(angle = 90, vjust = 0.5, hjust=1))
# Coleta os dados das eleições municipais election_mun <- party_mun_zone_local(2020) election_mun %>% select(DESCRICAO_CARGO, NOME_PARTIDO, QTDE_VOTOS_NOMINAIS) %>% filter(DESCRICAO_CARGO == "Prefeito") %>% group_by(NOME_PARTIDO) %>% summarise(soma_votos = sum(QTDE_VOTOS_NOMINAIS)) %>% arrange(desc(soma_votos)) %>% slice(1:10) %>% ggplot(aes(x = NOME_PARTIDO, y = soma_votos, fill = NOME_PARTIDO, label = soma_votos))+ geom_bar(stat = "identity")+ geom_label(color = "black")+ labs(title = "Quantidade de votos nominais em Prefeitos por partidos", subtitle = "10 maiores somas de votos em 2020", x = "", y = "", caption = "Elaborado por analisemacro.com.br com dados do TSE")+ theme_minimal()+ theme(legend.position = "none", axis.text.x = element_text(angle = 90, vjust = 0.5, hjust=1))
A função voter_profile, importa um data frame do dados do perfil dos eleitores agregados por estado, cidade e zona eleitoralOutra função como vote_mun_zone_fed, oferece dados das eleições federais desagregadas por cidades e zonas eleitorais
Para detalhes sobre os votos, utiliza-se a função details_mun_zone_local.
# Coleta os dados do perfil dos eleitores voters <- voter_profile(2018) # Coleta os dados das eleições locais por partidos vote_zone <- vote_mun_zone_fed(2018, uf = "MG") # Coleta os detalhes dos votos das eleiçoes locais details <- details_mun_zone_local(2020, uf = "MG")* Ao utilizar o pacote, se certifique da configuração de sua máquina, algumas funções do pacote podem importar grande quantidade de dados.
________________________
(*) Quer aprender mais sobre a linguagem R e como construir gráficos? confira nosso Curso de Introdução ao R para análise de dados.
________________________