Dentro do universo do R, cada vez mais tem sido facilitado o acesso a diversos tipos de dados. Para tanto, O pacote {microdatasus} tem como principal propósito a importação dos microdados do DATASUS, este sendo um sistema do estado brasileiro de apoio a conexão e suporte de informações sobre a saúde com os entes federativos. No Hackeando o R de hoje, iremos dar uma olhada sobre o pacote.
Antes de tudo é necessário realizar o download do pacote, que se encontra no repositório do autor no github.
# remotes::install_github("rfsaldanha/microdatasus")
library(microdatasus)
library(tidyverse)
O pacote se separa em dois tipos de funções, a primeira sendo fetch_datasus(), que consiste na função que realiza o download dos dados. E o segundo tipo, que se refere ao pré-processamento dos dados, sendo eles: process_sim(), process_sinac() e process_sih().
Para importar os dados mostraremos exemplos da função fetch_datasus().
(obs: antes de replicar o código, certifique que sua máquina pode lidar com grandes quantidades de dados. O processo pode demorar um pouco).
# Sistema de Informação sobre Mortalidade de Minas Gerais de 2019 data_sim_mg <- fetch_datasus(year_start = 2019, year_end = 2019, uf = "MG", information_system = "SIM-DO") # Sistema de informação Hospital Descentralizada de Minas Gerais de 2019 data_sih_mg <- fetch_datasus(year_start = 2019, year_end = 2019, month_start = 1, month_end = 12, uf = "MG", information_system = "SIH-RD") # Sistema de informações sobre Nascidos Vivos de Minas Gerais de 2019 data_sinasc_mg <- fetch_datasus(year_start = 2019, year_end = 2019, uf = "MG", information_system = "SINASC")
Trataremos de pegar somente dados de um único ano, já que são grandes quantidade de dados. Dependendo da máquina, pode demorar um pouco o tempo de download.
Ao seguir a etapa, agora é preciso tratar os dados com as respectivas funções de cada sistema.
# Trata os dados do SIM sim_mg <- process_sim(data_sim_mg) # Trata os dados do SIH sih_mg <- process_sih(data_sih_mg) # Trata os dados do SIA sinasc_mg <- process_sinasc(data_sinasc_mg)
As variáveis dos dados de cada sistema possuem uma forma especial de lidar, além de seus nomes serem processados em abreviações. Para obter a informações de todas as variáveis e suas convenções, é recomendável checar o repositório do github do pacote.
# Seleciona os dados de interesse: Estado civil da mãe e Sexo do bebê sinasc <- sinasc_mg %>% select(ESTCIVMAE, SEXO) %>% na.omit() # Visualiza os número de Mães por Estado Civil sinasc %>% count(ESTCIVMAE) %>% ggplot(aes(x = ESTCIVMAE, y = n, fill = ESTCIVMAE, color = ESTCIVMAE, label = n))+ geom_bar(stat = "identity")+ geom_label(color = "black")+ labs(title = "Estado Civil das Mães de Nascidos em Minas Gerais", subtitle = "ano de 2019", x = "", y = "", caption = "Elaborado por analisemacro.com.br com dados do DATASUS")+ theme_minimal()+ theme(legend.position = "none")
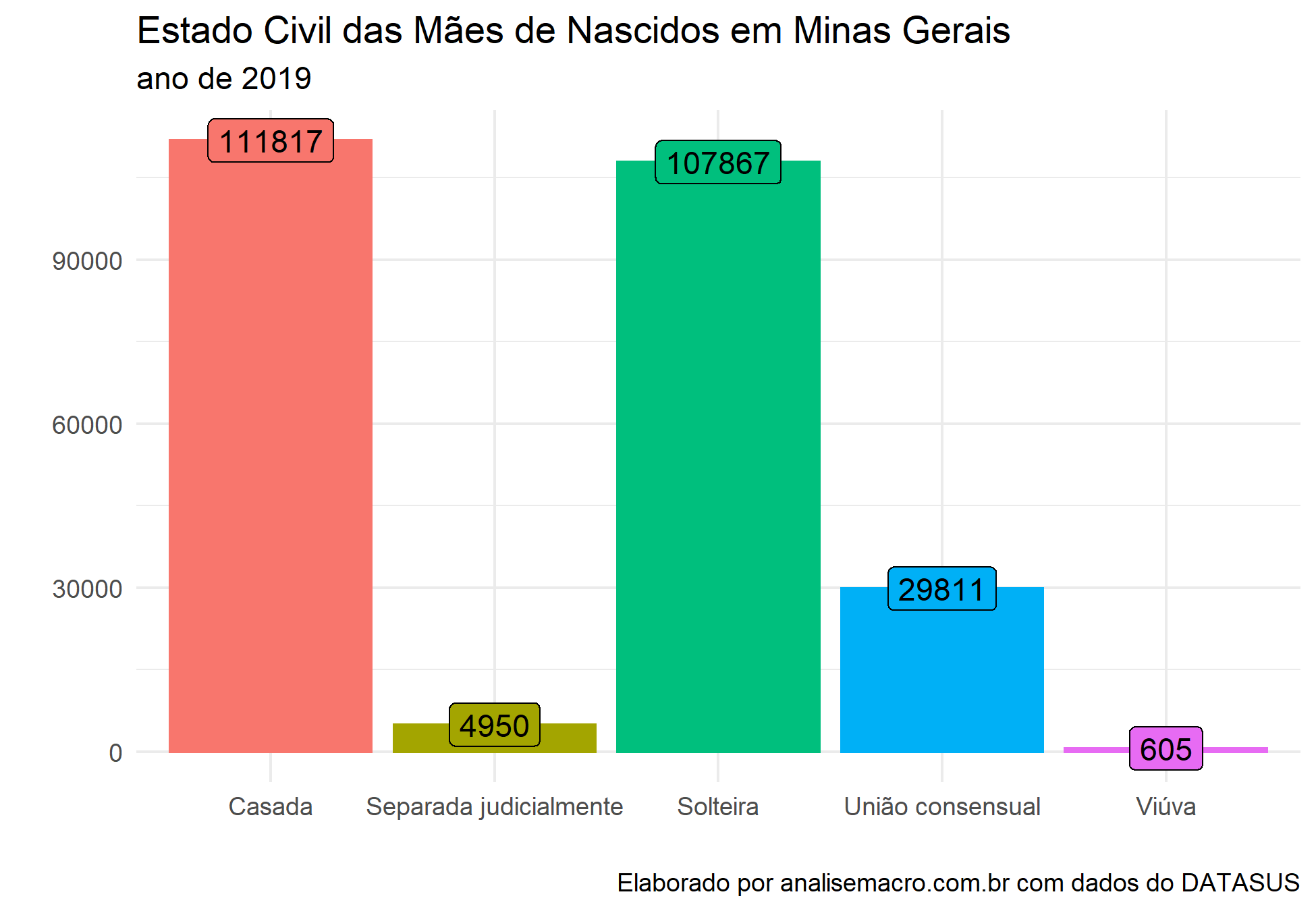
# Visualiza o número de bebês por sexo sinasc %>% count(SEXO) %>% ggplot(aes(x = SEXO, y = n, fill = SEXO, color = "SEXO", label = n))+ geom_bar(stat = "identity")+ geom_label(color = "black")+ labs(title = "Sexo dos bebês nascidos em Minas Gerais", subtitle = "ano de 2019", x = "", y = "", caption = "Elaborado por analisemacro.com.br com dados do DATASUS")+ theme_minimal()+ theme(legend.position = "none")

________________________________
Na Análise macro oferecemos cursos que ensinam você a como lidar com o micro dados e análise de dados. Veja nossa trilha de Micro dados e nosso curso de R para análise de dados.
________________________________


