No Hackeando o R de hoje, vamos mostrar como fazer a visualização de dados separados em diversos grupos, através de gráficos UpSet. Quando temos dados pertencentes a múltiplos grupos, a visualização do tamanho e propriedades de cada interseção cresce rapidamente com o número de grupos. Ferramentas mais comuns de visualização de interseções, como diagramas de Venn, podem criar representações bonitas com múltiplos grupos, porém extrair informações deles acaba sendo complicado. Abaixo, um exemplo de um diagrama de Venn complicado:
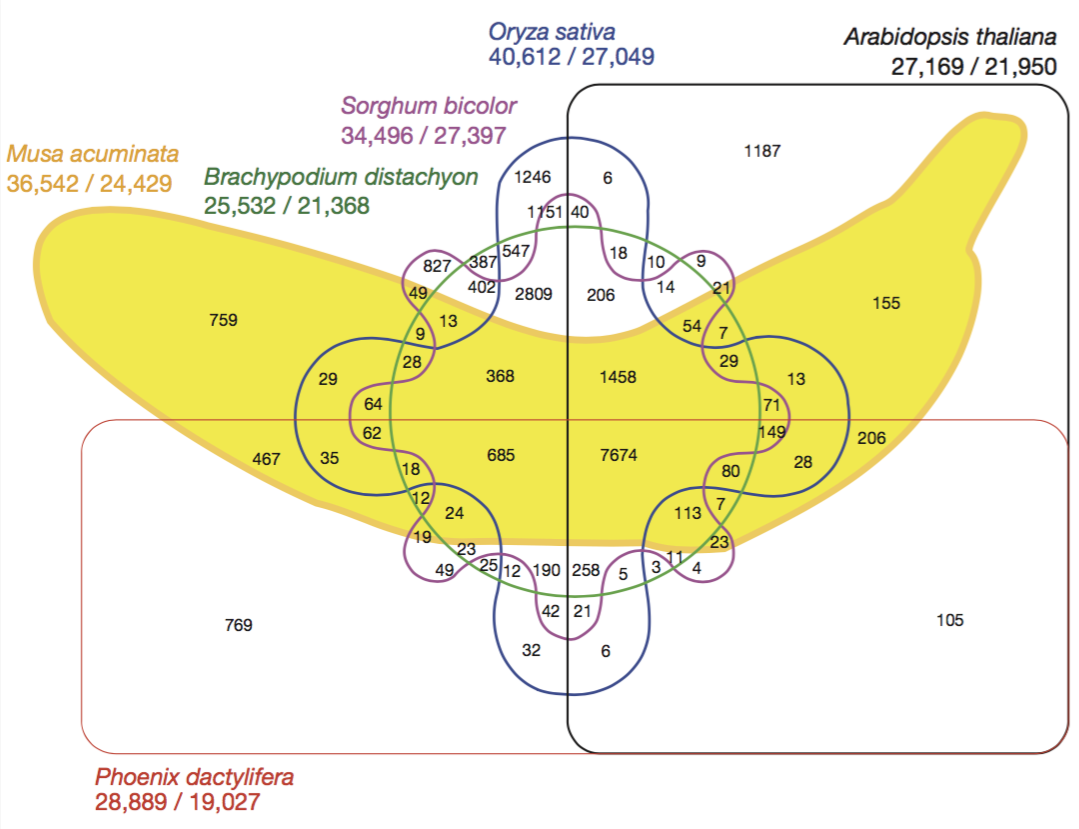
Com isso, vamos introduzir a visualização de UpSet. O conceito é definido pela transformação de interseções em uma matriz que representa cada combinação dos conjuntos originais. Além das interseções, a ferramenta também permite a definição de outras agregações, gerando visualizações mais complexas dos dados, conforme a necessidade do pesquisador. Vamos então mostrar aqui como utilizar o pacote ComplexUpset, disponível no CRAN.
library(ggplot2) library(ComplexUpset)
Iremos utilizar como exemplo os dados de filmes disponíveis no pacote ggplot2movies.
filmes = as.data.frame(ggplot2movies::movies) filmes = na.omit(filmes)
Para gerar a versão básica de uma visualização UpSet, precisamos dos dados, e de um vetor que indica quais são as categorias. Então, basta utilizar a função upset():
generos = colnames(filmes)[18:24] upset(filmes, generos, name='gênero', width_ratio=0.1, min_size = 10, set_sizes = FALSE)

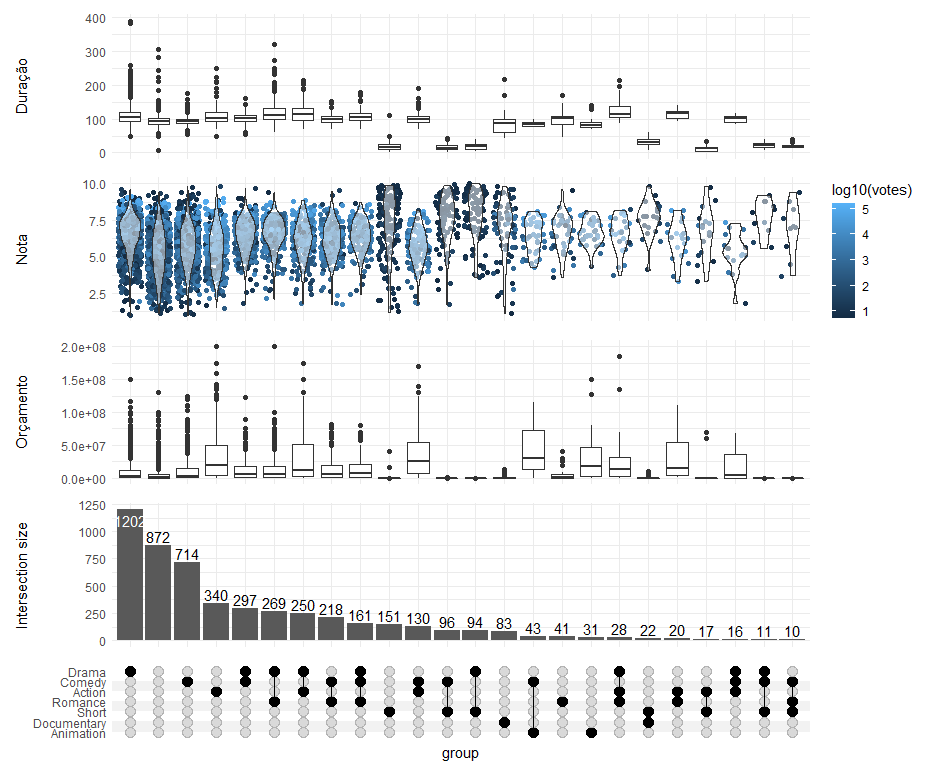
Além das contagens, podemos também utilizar o ggplot para apresentar propriedades de cada um dos subgrupos:
upset(
filmes,
generos,
annotations = list(
'Duração'=list(
aes=aes(x=intersection, y=length),
geom=geom_boxplot(na.rm=TRUE)
),
'Nota'=(
ggplot(mapping=aes(y=rating))
+ geom_jitter(aes(color=log10(votes)), na.rm=TRUE)
+ geom_violin(alpha=0.5, na.rm=TRUE)
+ scale_alpha_continuous(label = 'a')
),
'Orçamento'=upset_annotate('budget', geom_boxplot(na.rm=TRUE))
),
min_size=10,
width_ratio=0.1,
set_sizes = FALSE
)

________________________
(*) Para entender mais sobre a linguagem R e suas ferramentas, confira nosso Curso de Introdução ao R para análise de dados.


{kind=link}