Nunca saberemos o que dizem os dados se nunca os analisarmos, este é o princípio da Análise Exploratória de Dados. A AED potencializa a pesquisa com dados, permitindo que analistas consigam entender o que de fato o conjunto de dados descreve. No post de hoje, introduzimos o conceito de AED e demonstramos um exemplo com o R.
O que é AED?
Como dito, a AED é um conjunto de métodos que o analista utiliza para descrever um determinado conjunto de dados, permitindo compreender o comportamento de diversas variáveis. Permite também solidificar uma base para criar hipóteses e modelos preditivos/causais.
Apesar de crucial, a AED causa dificuldades naqueles que querem entrar no mundo dos dados, e o motivo é simples: cada conjunto de dados se comporta de uma forma, portanto, apesar de uma metodologia, cada "ferramenta" da metodologia se encaixa melhor em determinado dataset, enquanto em outros não, portanto, saber diferenciar quais "ferramentas" devem ser utilizadas é parte de um conhecimento analítico e crítico.
Mas afinal, qual metodologia é essa ? De quais formas podemos "entrevistar" nossos dados e retirar insights? Os meios mais importantes são:
- Classificar as variáveis em categóricas ou quantitativas;
- Sumarizar os dados utilizando estatísticas descritivas;
- Visualizar os dados utilizando gráficos.
Como dito, cada um desse processo pode haver inúmeras ferramentas, cada qual se encaixa melhor para um conjunto de dados em específico. Iremos realizar um exercício tomando como base o dataset peguins do pacote {palmerpenguins}, que possui dados de medidas dos corpos de pinguins, por espécies, por sexo e por ilha em Palmer Station na Antárctica. Explicaremos como podemos ler o dataset, bem como cada qual ferramenta podemos utilizar inserido no contexto de cada processo acima.
Antes de começar a AED, precisamos olhar nosso conjunto de dados e assegurar que eles devem ter os seguintes requisitos: deve seguir uma forma retangular/tabular de colunas e linhas; cada linha deve representar uma observação; cada coluna representa uma variável. Abaixo, carregamos o pacote e vemos como é o dataset penguins.
Veja que o dataset segue uma forma retangular com colunas e linhas, o que facilita o uso da linguagem e de outro softwares para realizar uma análise dos dados. Como dito, chamamos a colunas de variáveis e linhas de observações, e qual o significado disto?
Observações remetem uma única observação do dataset e suas características, desde indivíduos, tempo, país e no caso do dataset acima, uma amostra sobre as informações de pinguins em Palmer Station, com um total de 334 linhas.
As características destes pinguins são representadas pelas colunas, chamadas de variáveis. Ocorre uma variação de cada observação ao longo das linhas, portanto, as variáveis provêm informações preciosas sobre algo. Há 8 variáveis no dataset penguins.
Cada variável possui um tipo diferente, e que para cada tipo existe uma ferramenta adequada para a análise. A classificação destas variáveis é realizada de forma relativamente arbitrária, com um certo padrão na escolha destes tipos. Elas podem ser:
- Categóricas: Assume valores que dizem respeito sobre a qualidade ou característica de cada observação. Os valores são não numéricos, como strings (caracteres) ou lógicos. É subdividido em binário, nominal e ordinal.
- Binário: Assume apenas dois valores, normalmente como sim ou não; True ou False; 0 ou 1 ou qualquer outra característica de dois valores;
- Nominal: Valores qualitativos que assumem mais de dois valores, como país, nome, espécie do pinguim, etc.
- Ordinal: Valores qualitativos que assumem mais de dois valores e também possuem uma ordem intrínseca, como pequeno, médio, grande, dias da semana e etc.
- Quantitativas: variáveis quantitativas são valores numéricos que dizem respeito a grandeza de uma variável. Assumem valores contínuos ou discretos.
- Contínuo: em teoria, assumem uma distância não padrão entre uma observação e outra, bem como essa distância pode ser um número infinito de possíveis valores.
- Discreto: assumem apenas valores fixos entre duas observações.
Classificação de variáveis
Vemos no dataset qual variável se encaixa melhor em cada classificação, remetemos novamente ao quadro anterior, e utilizamos a função glimpse() para entender como o R reconhece as variáveis. Veja que não é difícil tirar conclusões sobre.
- species (fct) - categóricos - nominal: Espécie do pinguim
- island (fct) - categórico - nominal: Ilha do pinguim
- bill_length_mm (double) - quantitativo - continuo: comprimento do cúlmen
- bill_depth_mm (double) - quantitativo - continuo: profundidade do cúlmen
- flipper_length_mm - (integer) - quantitativo - contínuo: comprimento da nadadeira
- body_mass_g (integer) - quantitativo - contínuo: massa corporal
- sex (fct) - categórico - binário: Sexo do Pinguim
- year (integer) - categórico - ordinal: Ano
Explorando: variáveis categóricas
Antes de explorar os dados, devemos primeiro realizar uma pergunta a nós mesmos: o que eu quero analisar? De fato, podemos simplesmente realizar visualizações e construir estatísticas descritivas com todas as variáveis, mas antes, realizar a definição de uma pergunta sobre o que analisar facilita a direção do trabalho.
Com isso, podemos realizar a pergunta: Qual a distribuição de pinguins por espécies em cada ilha? E o sexo? Podemos explorar as variáveis categóricas a fim de obter as respostas.
As variáveis categóricas devem ser exploradas em formato de contagem, afinal, como não são numéricas não podemos utilizar de medidas estatísticas diretamente. Utilizamos a função count() do pacote {dplyr} para realizar o cálculo.
Em poucas linhas obtivemos os resultado das perguntas criadas acima. O interessante do count() é que é também útil para alegar um problema constante na AED: valores faltantes no dataset. Não iremos lidar diretamente com este problema aqui, porém, tomaremos cuidado com eles na análise.
Outro método mais amigável para investigar variáveis categóricas é através da visualização. Utilizaremos o pacote ggplot2 para gerar um gráfico de barras, que é uma das melhores ferramentas para averiguar a distribuição dos dados categóricos.
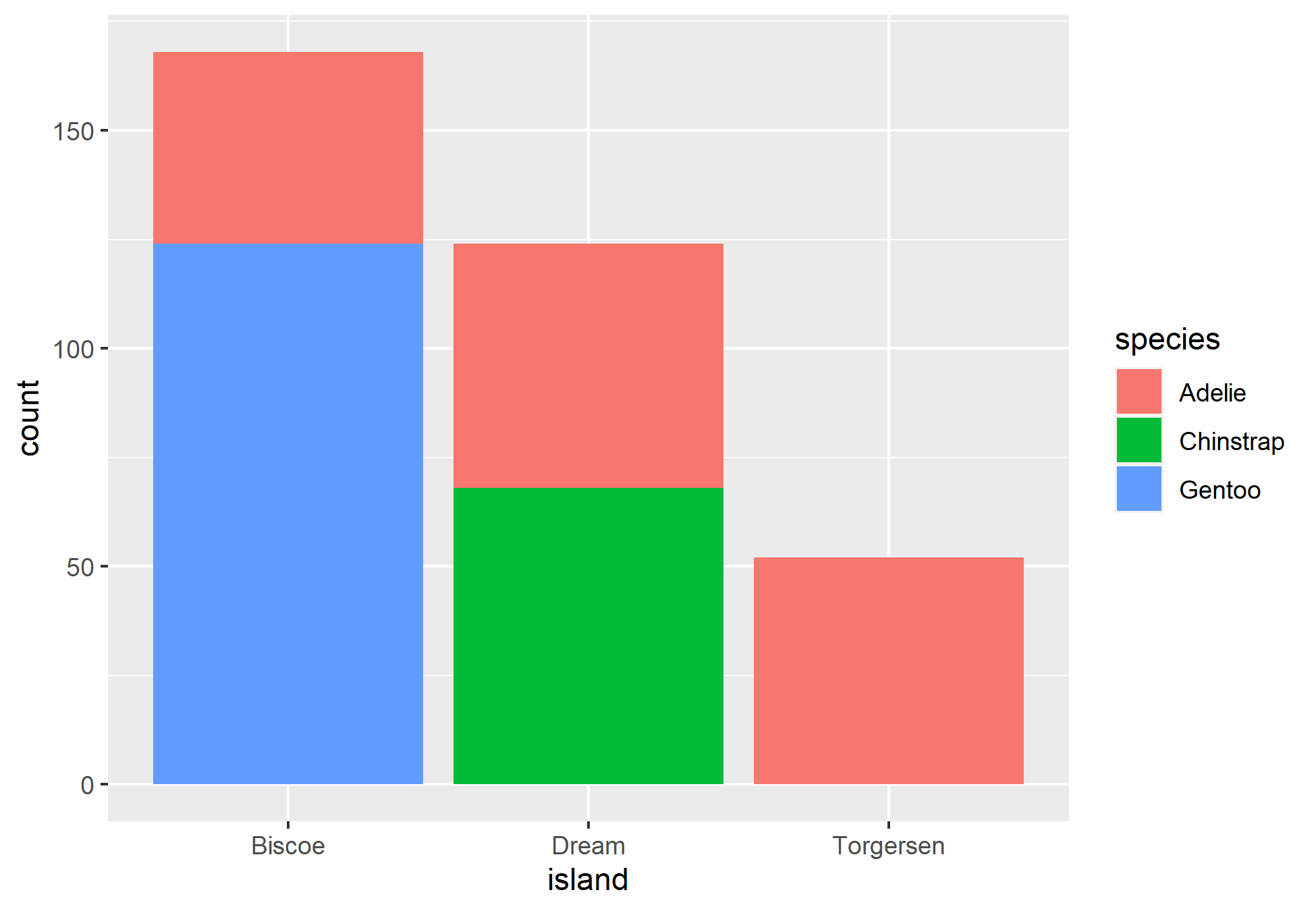
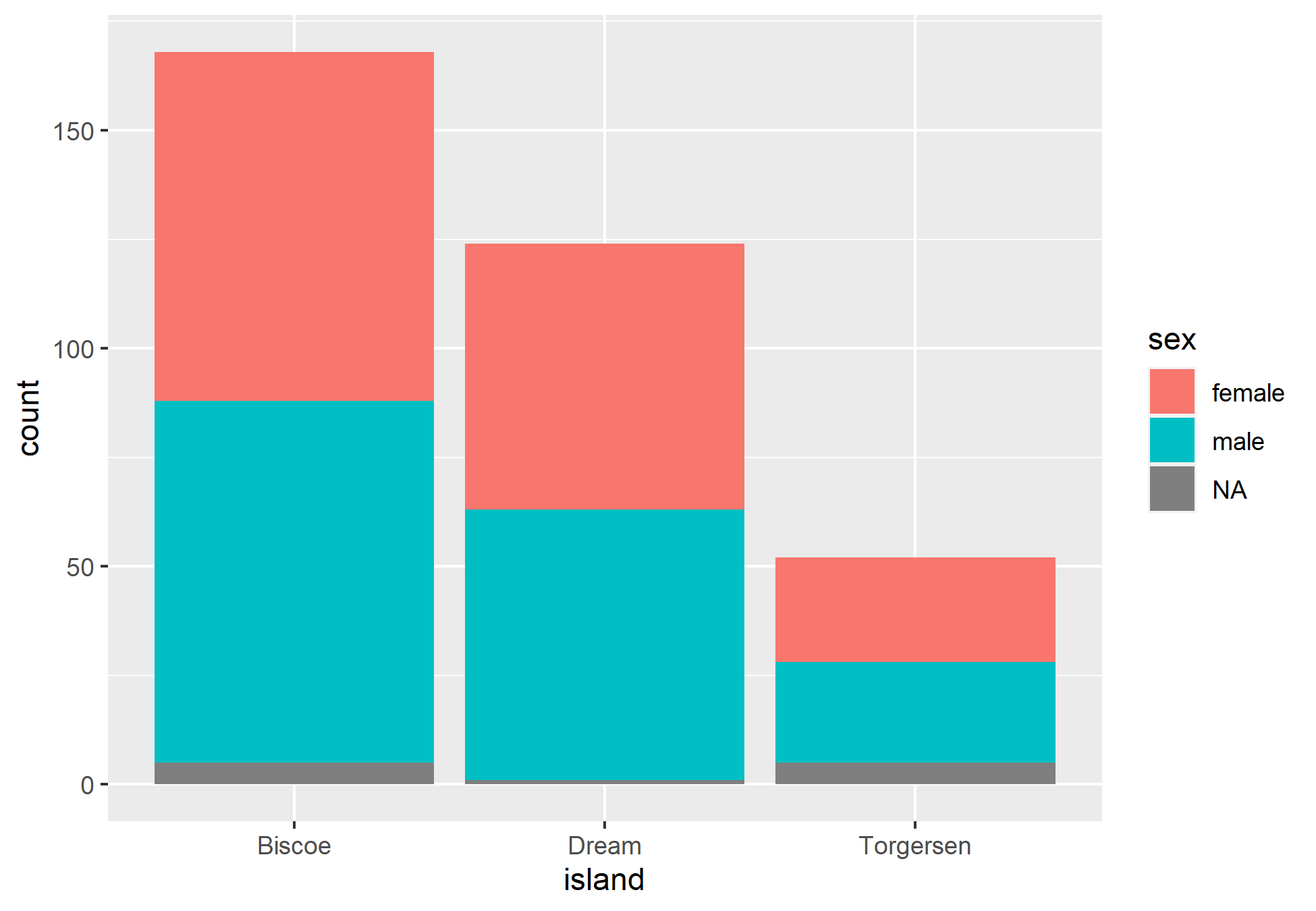
Interessante, não? Podemos partir para como lidar com as variáveis quantitativas.
Explorando variáveis quantitativas
Será que pinguins de diferentes ilhas possuem tamanhos de bicos muito diferentes? Qual espécie possui, em média, uma massa corporal maior? Aqui podemos utilizar diretamente de medidas estatísticas. Para as perguntas, podemos realizar uma combinação da função group_by() para agrupar por categóricas, e em seguida utilizar a função summarise() para aplicar o cálculo de uma medida estatística para cada grupo.
Veja que ambas as perguntas foram respondidas, uma por meio do desvio padrão e outro por meio da média. Com cada resposta seria possível realizar ainda mais perguntas sobre os dados, como: A variação do comprimento do bico em cada ilha ocorre devido as distribuição de espécies por ilha? Além da espécie, é necessário levar em conta a distribuição do sexo de penguim por espécie para tirar conclusões sobre o peso? De fato, poderíamos criar cada vez mais perguntas e seguir uma caminho para Análise, por isso, é sempre necessário escolher um direcionamento antes de começar um AED.
Como seria exaustivo responder todas as perguntas aqui, continuaremos a utilizar diferentes ferramentas para entender as perguntas feitas anteriormente. Os gráficos podem ser nossos aliados.
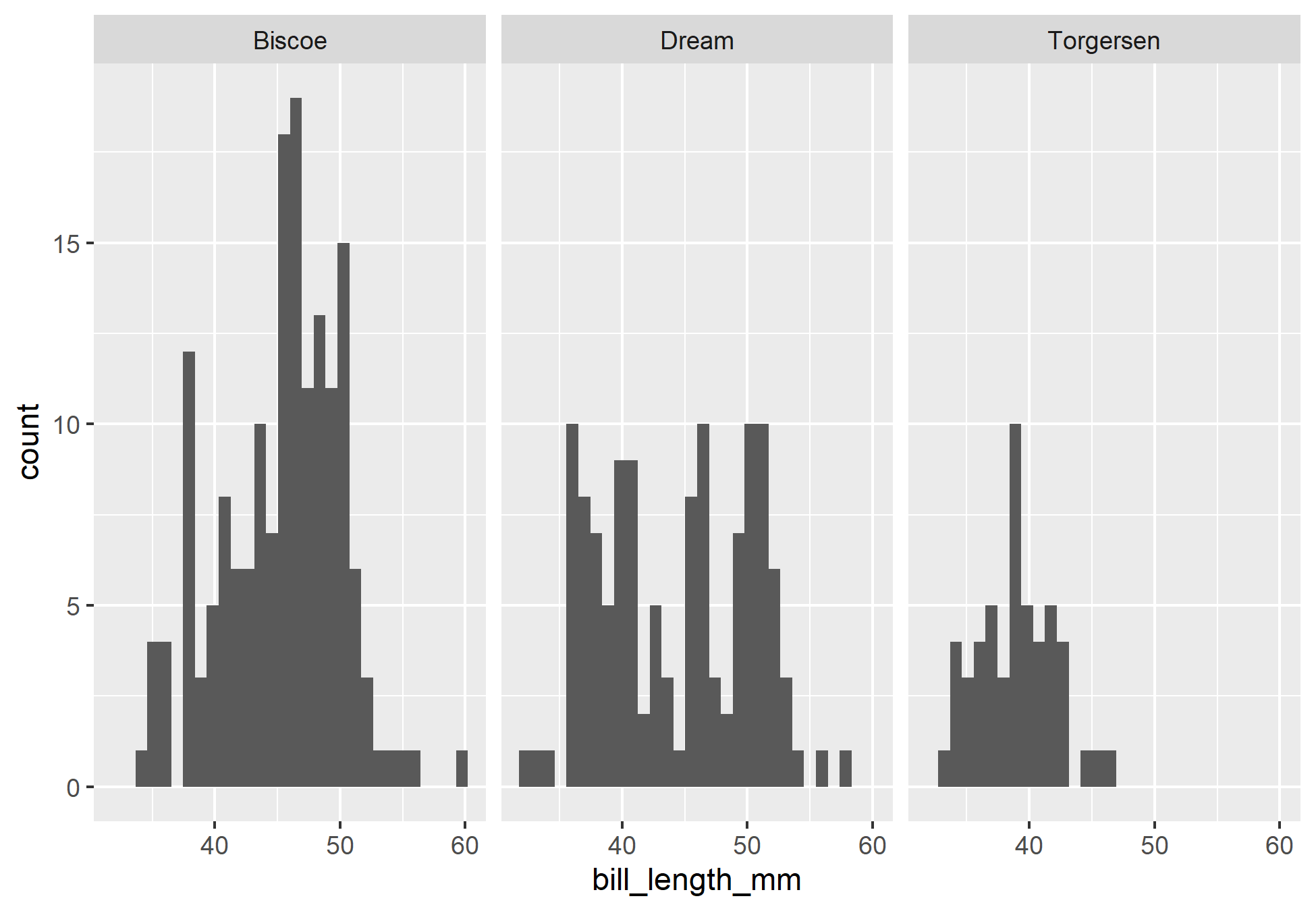
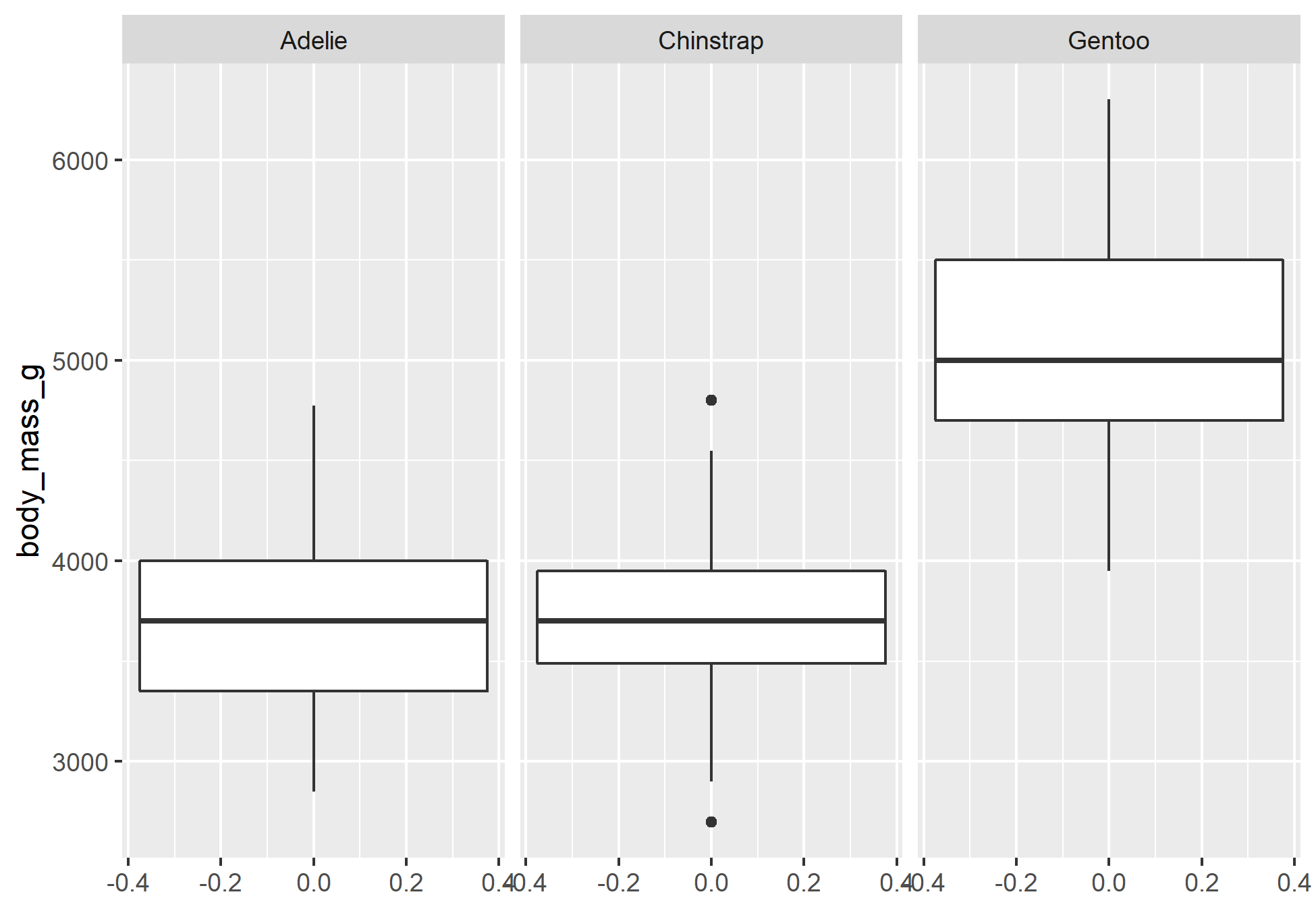
____________________________________________
Essas são algumas das ferramentas que podemos utilizar para que possamos realizar uma Análise Exploratória de Dados. Existem inúmeras outras técnicas e que você pode aprender com nossos cursos de R e Python aplicados para a Análise de Dados e Economia. Confira:

