Para aqueles que desejam realizar o processo de análise de dados, o Excel pode ser útil, porém, é possível melhorar ainda mais esse processo utilizando o R e Python. Neste post de hoje, mostraremos para os usuários do Excel como é fácil realizar uma análise exploratória de dados, seguindo o procedimento de avaliar as estatísticas descritivas e a visualização de dados, obtendo resultados que podem ser adquiridos dentro do Excel, porém, de forma simplificada e rápida utilizando as linguagens R e Python.
R e Python são linguagens que se tornaram famosas pelo seu uso no processo de Análise de Dados, simplificando todo o processo de coleta, limpeza, visualização, modelagem e comunicação. De fato, as duas linguagens são diferentes, principalmente em seus propósitos, porém, se encaixaram muito bem na área. O interessante do R e do Python é que ambos são open source, ou seja, qualquer usuário pode criar pacotes e realizar sua divulgação, o que permite as soluções de diversos problemas possam ser compartilhados mundo afora.
Através deste mecanismo de criação de pacotes, tanto R e Python tiveram aqueles que mais se destacaram e que auxiliam no processo de análise exploratória de dados. Enquanto o R possui o Tidyverse (que na realidade é uma junção de diversos pacotes). O Python possui o numpy, o pandas e o matplotlib/seaborn para realizar o processo.
Nos exemplos abaixo, utilizaremos os pacotes citados, além de outros, para mostrar aos usuários do Excel como é fácil utilizar o R e o Python. O dataset utilizado como exemplo será o mpg, que traz informações sobre carros produzido no EUA, Asia e Europa na década de 70 e 80 e suas respectivas características. Você pode baixar o arquivo em .xlsx do mpg por aqui para poder reproduzir o código abaixo.
Análise Exploratória no R
Para realizar a análise exploratória no R utilizaremos três pacotes importante para realizar a manipulação, obter as estatísticas descritivas e auxiliar no processo de visualização de dados.
O primeiro passo para realizar a análise é importar a planilha do dataset no R utilizando a função read_excel(). Em seguida, devemos investigar a estrutura dos dados e suas variáveis, vasculhando as colunas e as observações do mesmo. Ao termos uma ideia de como é o Data Frame, selecionamos as colunas de interesse que iremos utilizar.
O resto do processo é analisar através das estatísticas descritivas e sumarização a configuração dos dados. Esse processo deve ser necessário para tirar insights e responder dúvidas: Em média, qual o peso dos carros? Os pesos dos carros variam muito? Há valores discrepantes nesta variável? Se separarmos por origem dos carros, o padrão de cada variável mudará? Esse formato de perguntas são necessários em qualquer análise exploratória, e auxilia também no processo de modelagem.
Nos códigos acima calculamos valores preciosos sobre as estatísticas descritivas do dataset. Primeiro realizando este cálculo para todas as variáveis como um todo, e depois, separando-as por categorias da origem dos carros. Veja que no processo utilizamos tanto o {dplyr} e o {skimr} (e os dois juntos) para obter os resultados.
Abaixo, o processo de análise também seguirá com as mesmas perguntas, porém, utilizaremos de métodos gráficos para obter a distribuição e o relacionamento das variáveis com o pacote {ggplot2}.
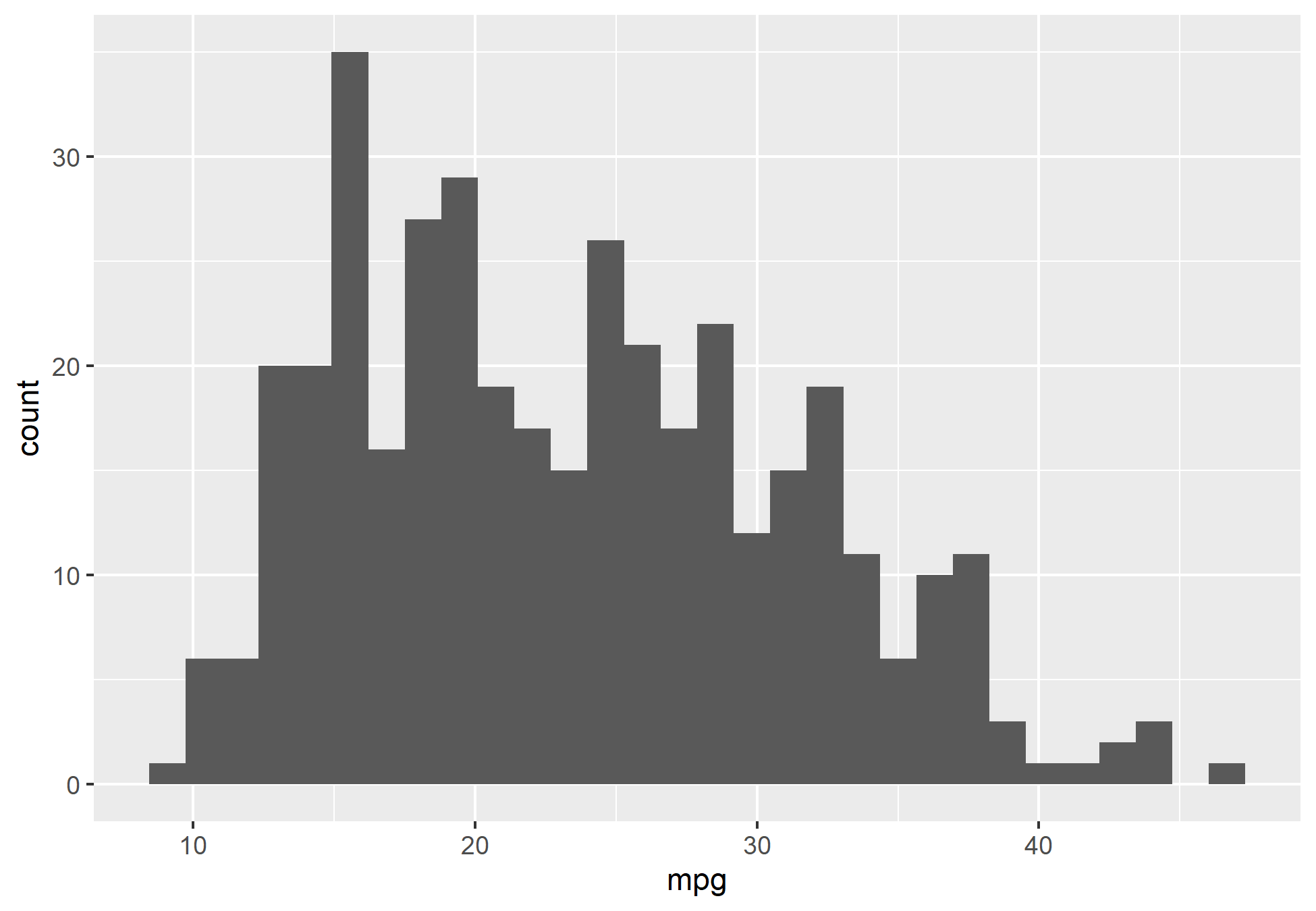
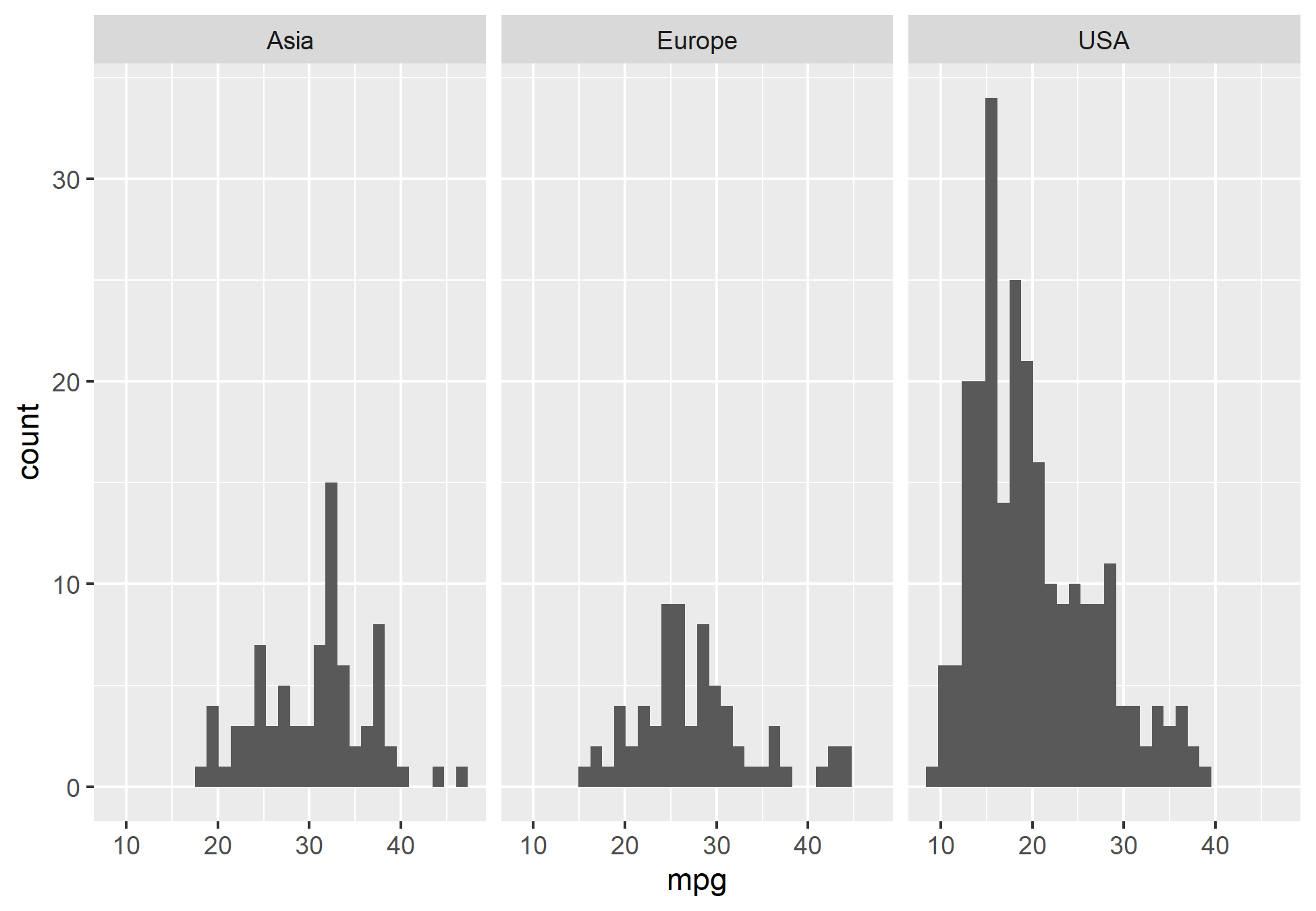

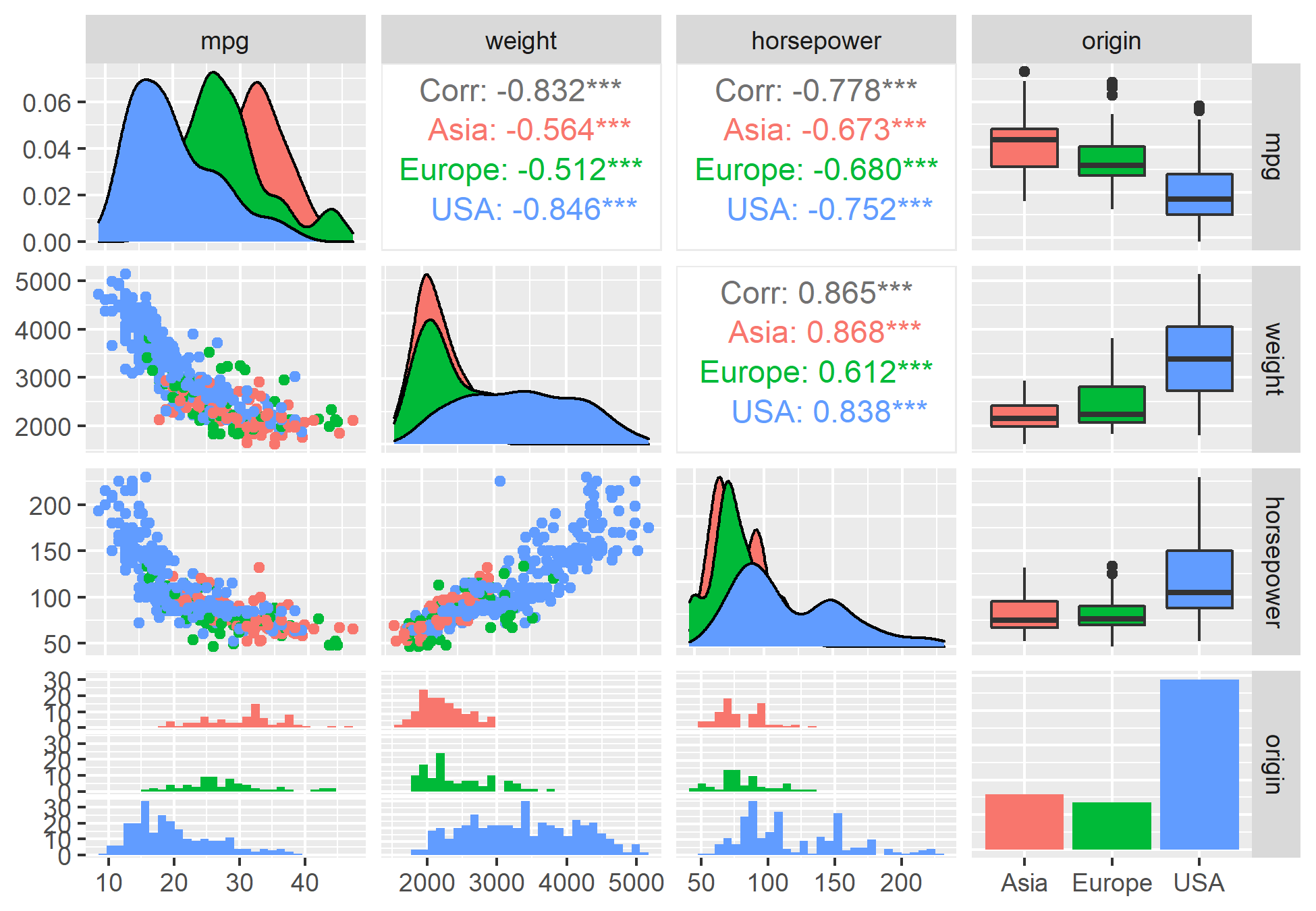
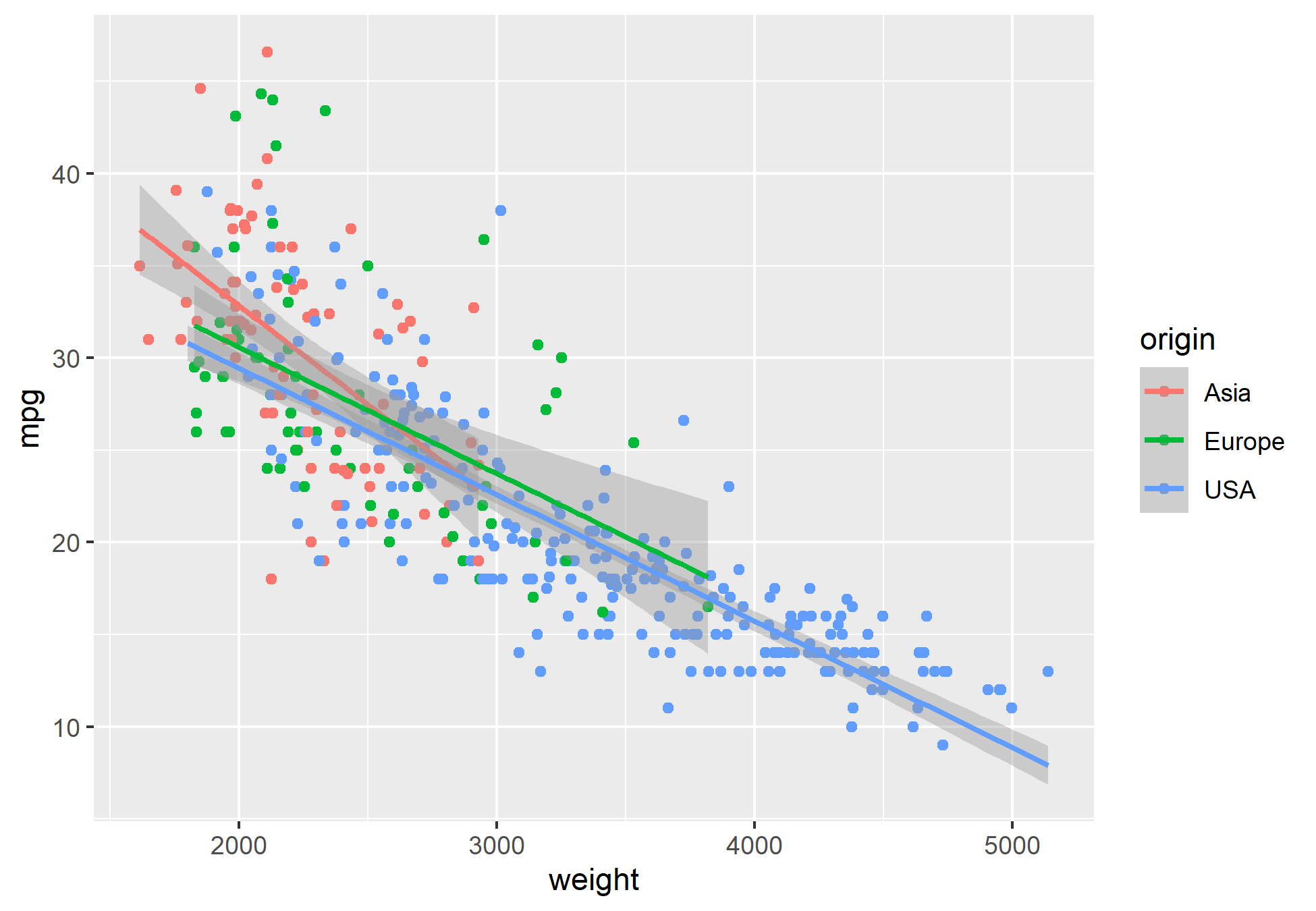
Análise Exploratória no Python
No Python, o processo seguirá o mesmo, com as mesmas perguntas, porém, obviamente, utilizaremos formas diferentes para calcular as estatísticas descritivas e a visualização. A intuição é a mesma, o que muda aqui é somente a sintaxe.
Importaremos os dataset com a função read_excel do pandas e inspecionaremos os dados para em seguida selecionar as variáveis de interersse.
Realizamos o processo de análise de dados sumarizando as estatísticas descritivas e separando os valores por categorias de origem do carros.
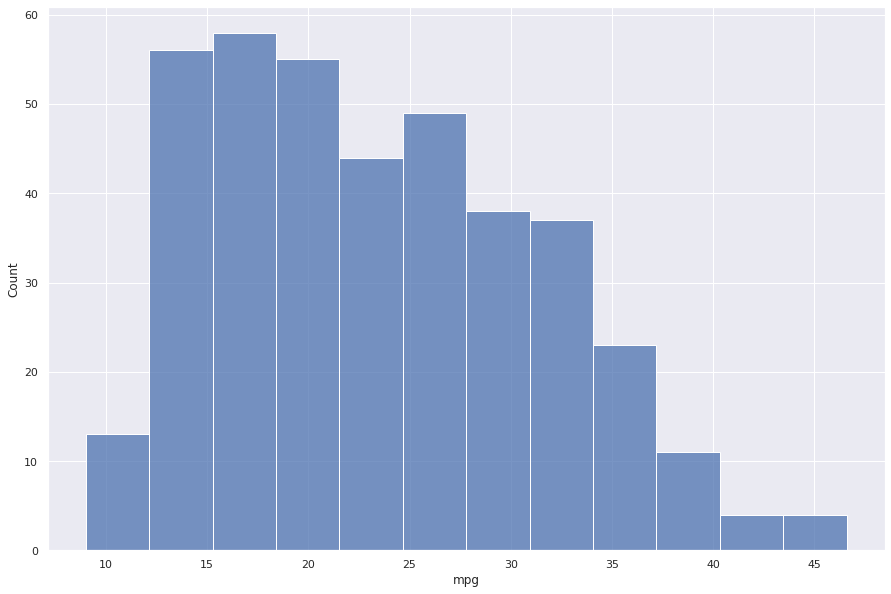
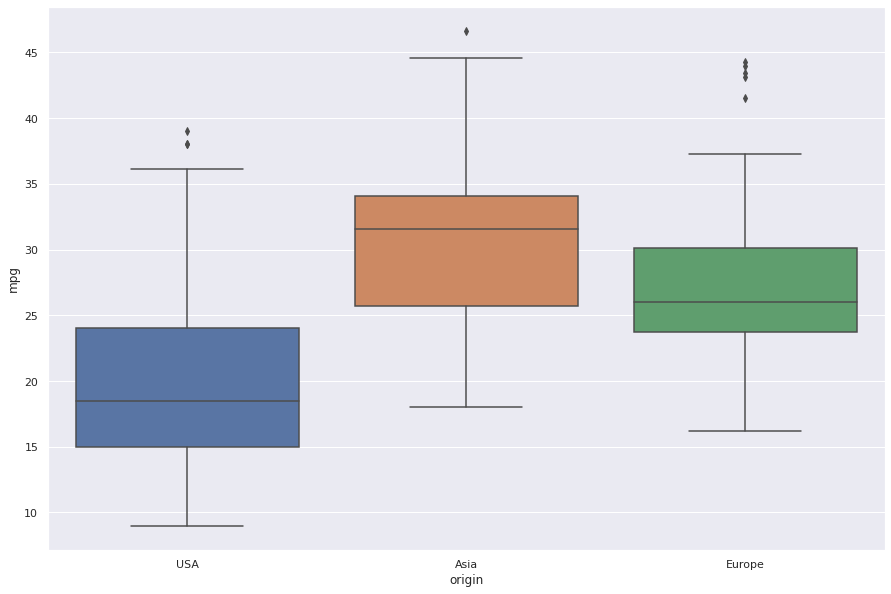
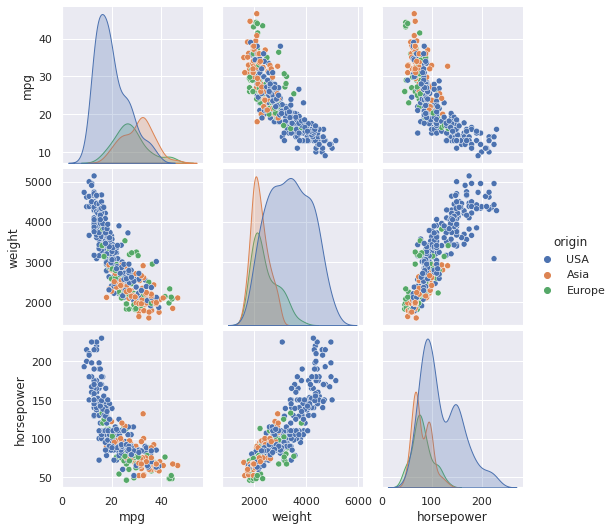
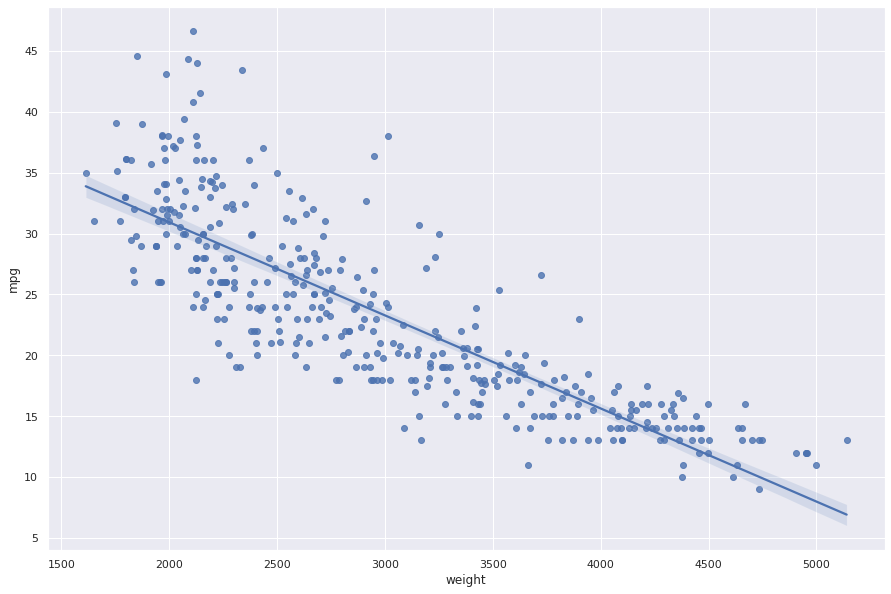
Por fim, visualizamos a distribuição e o relacionamento entre as variáveis do dataset.

Quer saber mais?
Veja nossos cursos de R e Python para Análise de dados. Também veja nossa trilha de Ciência de dados.

