A previsão de indicadores econômicos é uma tarefa crucial para governos, empresas e investidores. No Brasil, a Pesquisa Mensal de Comércio (PMC) do IBGE, que mede a variação percentual do volume de vendas no varejo, é um dos termômetros mais importantes da atividade econômica. Diante da crescente disponibilidade de ferramentas e técnicas, surge a pergunta: qual a melhor abordagem para prever a PMC? A econometria tradicional, o machine learning (ML) ou a inteligência artificial (IA) generativa?
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Para responder a essa questão, foi desenvolvido um sistema robusto de previsão que compara diretamente essas três frentes. Utilizando dados históricos da PMC, extraídos diretamente da API do SIDRA/IBGE, foi criada uma série temporal que vai de fevereiro de 2003 a julho de 2025, permitindo uma análise aprofundada e a construção de modelos preditivos. O projeto foi implementado em Python, com o auxílio de bibliotecas consagradas como pandas para manipulação de dados, pmdarima e statsmodels para a econometria, xgboost e scikit-learn para o machine learning, e nixtla para a inteligência artificial.
A análise comparativa colocou três modelos para competir:
- ARIMA (Autoregressive Integrated Moving Average): Um representante da econometria clássica, amplamente utilizado em análise de séries temporais. Este modelo busca capturar autocorrelações nos dados, ou seja, como valores passados da série influenciam seus valores futuros.
- XGBoost (Extreme Gradient Boosting): Um poderoso algoritmo de machine learning que se destacou em competições pela sua alta performance. Ele aprende de forma incremental com os erros de previsões anteriores, sendo capaz de modelar relações complexas e não-lineares nos dados.
- TimeGPT: Um modelo de fundação para previsão de séries temporais desenvolvido pela Nixtla. Representando a vanguarda da IA, o TimeGPT foi pré-treinado em um vasto conjunto de dados de séries temporais, permitindo-lhe "aprender" padrões sazonais e de tendência complexos e aplicá-los a novos dados sem a necessidade de um treinamento extensivo.
Para garantir uma comparação justa e robusta, os modelos foram submetidos a um rigoroso processo de avaliação. Além de uma simples divisão entre dados de treino e teste, foi aplicada a validação cruzada para séries temporais, uma técnica que avalia o desempenho dos modelos em diferentes janelas de tempo do histórico. As métricas utilizadas para medir a acurácia foram o RMSE e o MAE.
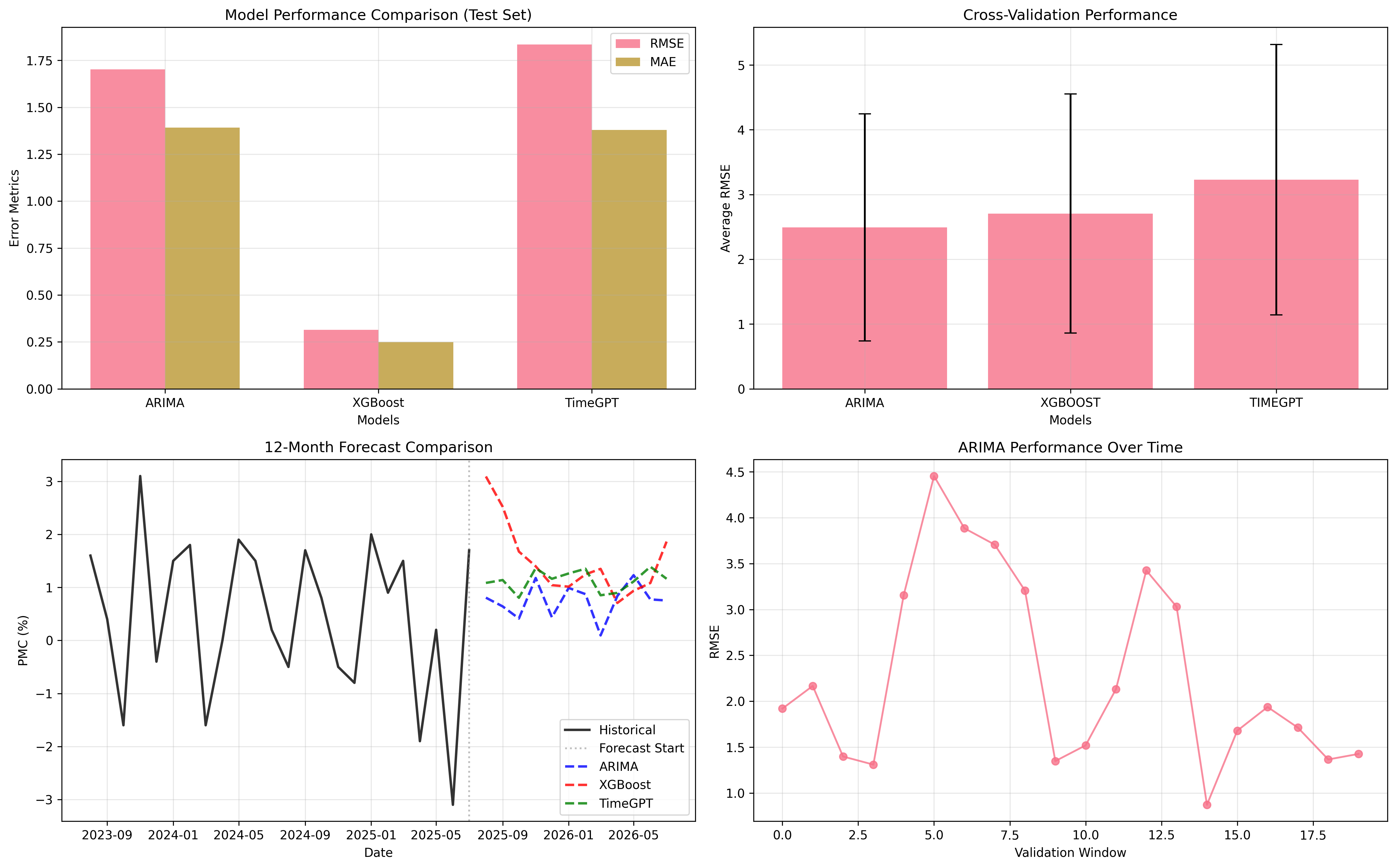
Os resultados revelaram nuances interessantes. No teste com os dados mais recentes, o XGBoost demonstrou uma performance superior, com o menor erro de previsão. Isso sugere que o modelo de machine learning foi mais eficaz em capturar as dinâmicas recentes e de curto prazo da série. Por outro lado, a análise de validação cruzada mostrou que o ARIMA, apesar de mais simples, apresentou o desempenho mais consistente ao longo das diversas janelas históricas (valiação cruadda), indicando maior estabilidade.
A imagem acima ilustra as projeções geradas pelos diferentes modelos para os próximos 12 meses. É possível observar como cada abordagem captura a tendência e a sazonalidade da série de maneiras distintas. Diante da performance variada, a solução mais robusta foi a criação de um modelo ensemble, que combina as previsões do ARIMA, XGBoost e TimeGPT. Essa abordagem busca mitigar os pontos fracos de cada modelo individualmente, resultando em uma previsão mais equilibrada e, potencialmente, mais precisa.
Afinal, qual é o melhor? A análise demonstra que não há uma resposta única. A escolha da ferramenta ideal depende do objetivo. Para capturar padrões mais recentes e complexos, o XGBoost se mostrou superior. Para uma previsão mais estável e consistente com o comportamento histórico, o ARIMA ainda é uma ferramenta valiosa. A IA, com o TimeGPT, oferece uma alternativa poderosa e de rápida implementação. No entanto, a combinação estratégica das três abordagens em um modelo ensemble prova ser o caminho mais promissor para uma previsão mais resiliente e confiável da PMC.
Quer aprender mais?
Conheça nossa Formação do Zero à Análise de Dados Econômicos e Financeiros usando Python e Inteligência Artificial. Aprenda do ZERO a coletar, tratar, construir modelos e apresentar dados econômicos e financeiros com o uso de Python e IA.

