Bancos de Dados
O termo banco de dados (database), para a maioria das pessoas, pode significar uma coleção de dados ou itens (listas de qualquer tipo, como por exemplo, pagamentos mensais, clientes, compras, etc).
Porém, o termo é estritamente definido como uma coleção de registros integrados que formam um método de coleta e organização de dados. E obviamente, implica na utilização de uma tecnologia, como por exemplo, planilhas contendo dados de clientes, arquivos de texto contendo dados sobre voos ou bancos de dados relacionais.
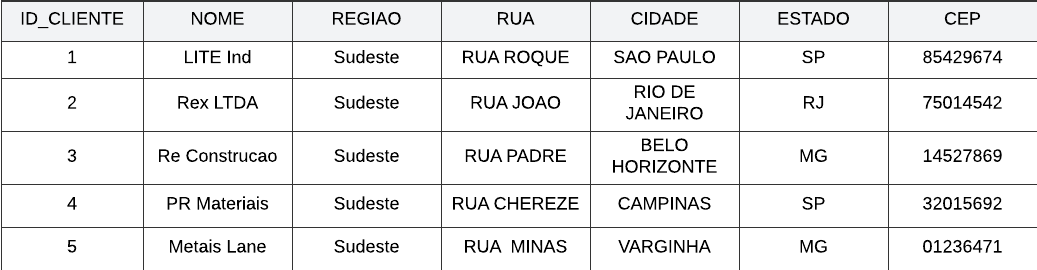
Um registro é a representação de um objeto físico ou conceitual. Por exemplo, o envio de pedidos para clientes de uma empresa. Cada registro desta pesquisa representa um cliente. Os registros possuem atributos, como por exemplo, nome, região, rua e cidade. As observações (o registro de cada atributo) são os dados.
É comum encontrar dados coletados em diferentes formatos, como CSV, JSON por meio de APIs, XML em um banco de dados NoSQL, e diferentes outros.
Entretanto, os Bancos de Dados Relacionais SQL dominam o mercado e são os mais utilizados por sistemas de bancos de dados em empresas.
Formato dos dados
Os dados podem ser armazenados em diferentes formas e estruturas.
Podem ser em formas não estruturadas, como por exemplo: documentos em texto, imagens e áudios.
E em forma estruturada, em formato tabular, como uma planilha ou tabela de banco de dados contendo texto ou valores numérico (como por exemplo, na imagem acima). A maioria dos softwares para a análise de dados realiza aplicações em dados estruturados, principalmente a linguagem SQL.
Metadados
Um banco de dados consiste em ambos os dados e os metadados.
Metadados são as informações que descrevem a estrutura dos dados no banco de dados. É uma forma de entender como os dados estão dispostos para facilitar as consultas.
Os bancos de dados guardam os metadados em um local chamado dicionário de dados, que contém definições e representações de elementos de dados (tabelas, colunas, restrições, etc).
Tamanho de banco de dados e complexidade
Um banco de dados pode possuir diferentes tamanhos, de simples coleções de poucos registros para sistemas que possuem milhões. A usabilidade do banco de dados pode ser definida com base no seu tamanho, no equipamento em que é utilizado e no tamanho da organização que o mantém. Sendo assim, os separamos em três tipos:
Banco de dados pessoal: é desenhado para uma única pessoa para ser utilizado em um único computador. Possui uma estrutura simples e tamanho relativamente pequeno.
Banco de dados de uma organização ou grupo de trabalho: Esse tipo de banco de dados é geralmente maior que um pessoal e mais complexo. Necessita ser utilizado por diversas pessoas que tentam acessar o mesmo dados ao mesmo tempo
Banco de dados de uma empresa: São enormes, guardando informações sobre a organização inteira.
Bancos de dados Relacionais
Dados estruturados, como mencionado, possuem formatos tabulares, com linhas (registros) e colunas (atributos). Esse formato em banco de dados relacional é referenciado como uma tabela. Cada tabela pode armazenar diferentes subconjuntos e tipos de dados em níveis diferentes de detalhes.
Um banco de dados relacional é uma coleção de tabelas que se relacionam entre si. Vamos utilizar como exemplo duas tabelas de PEDIDOS e CLIENTES, representados, respectivamente, abaixo.
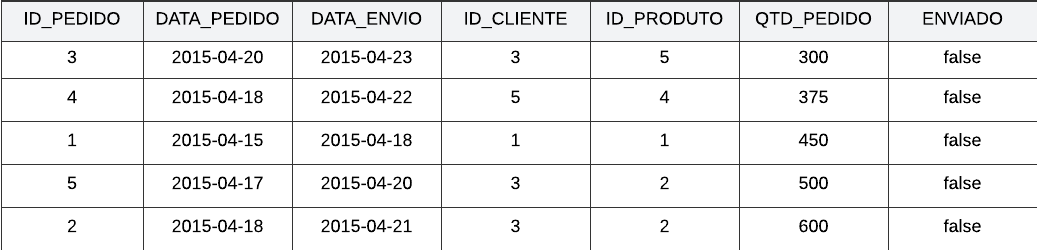
Veja que na primeira tabela, PEDIDOS, contém a coluna chamada ID_CLIENTE. Essa coluna também está contida na tabela CLIENTES. Através dela, as informações se relacionam de forma que seja possível ligar os dados entre as duas tabelas.
Com isso, através das informações sobre os pedidos, é possível localizar as informações sobre os clientes que realizaram os pedidos.
Por que Tabelas Separadas?
As tabelas são construídas de formas separadas devido ao conceito de normalização. Basicamente, é a separação de diferentes tipos de dados em suas próprias tabelas. Se houvesse todas as informações em apenas uma tabela, ela seria redundante, inchada e causando aumento da manutenção e diminuição do desempenho.

Veja que se houvesse as informações do clientes na tabela PEDIDOS, ocasionaria o aumento de linhas relacionadas a Re Construcao. Isso é redundante, e toma espaço inútil no armazenamento, além de que ocasiona um aumento na manutenção, caso seja necessário mudanças nos dados.
Considerações
Por fim, podemos entender o que são Bancos de Dados, e como bancos de dados relacionais funcionam. Esse forma de montagem de armazenamento de dados é extremamente útil em uma organização, e é potencializada no processo de análise de dados com a linguagem SQL.
____________________________________________________
Quer aprender mais?
Veja nosso curso de SQL para Economia e Finanças, onde ensinamos todo o processo para aqueles que desejam entrar na área. O curso faz parte da trilha Ciência de Dados para Economia e Finanças.

