A tarefa preditiva
O objetivo do exercício é prever o futuro de uma série temporal, tomando como exemplo o Índice Nacional de Preços ao Consumidor Amplo (IPCA), divulgado pelo IBGE. Esta série temporal é bastante conhecida entre os economistas e possui algumas características de destaque:
- Sazonalidade anual
- Tendência crescente
- Inércia (autocorrelação positiva)
Estas são características presentes em várias séries temporais, sejam econômicas ou não, o que torna a série do IPCA representativa para fins de tarefa preditiva. Aqui trataremos a série em variação percentual mensal. Para saber mais sobre as características do IPCA, pesquise por “ipca” no blog da Análise Macro.

- Abordagem econométrica: utilizaremos o modelo SARIMA (open source), visto que pode captar a inércia e a sazonalidade da série e está implementado em Python.
- Abordagem de machine learning: utilizaremos o algoritmo XGBoost (open source), visto que pode captar a sazonalidade e outras características usando feature engineering e está implementado em Python.
- Abordagem de IA: utilizaremos o TimeGPT (closed source), visto que é um modelo baseado em LLMs otimizado para prever séries temporais no curto prazo e está implementado em Python.
Todos os modelos escolhidos são utilizados com seus parâmetros padrão de software. Um modelo de passeio aleatório sazonal também é utilizado como base de comparação.
Separamos os dados da série temporal em duas simples amostras: a primeira, chamada de treino, será usada para estimar parâmetros/treinar o modelo; a segunda, chamada de teste, será usada para comparar as previsões do modelo com os dados reais e corresponde às últimas 12 observações.
Ao final, comparamos os modelos usando como métrica a Raiz do Erro Quadrático Médio (RMSE) para construir um ranking. Sendo assim, quanto menor o RMSE, maior é a acurácia do modelo em termos preditivos. Note que, para simplificar, não utilizaremos validação cruzada, portanto os resultados aqui expostos podem não se generalizar para amostras diferentes.
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Previsão com modelos econométricos
As previsões geradas pelo modelo econométrico ARIMA podem ser conferidas abaixo:

Previsão com modelos de Machine Learning
As previsões geradas pelo modelo de machine learning XGBoost podem ser conferidas abaixo:

Previsão com modelos de IA
As previsões geradas pelo modelo de inteligência artificial TimeGPT podem ser conferidas abaixo:

Comparando resultados
A análise visual das previsões já pode dar algum indicativo de desempenho dos modelos, ao comparar os dados observados (linha preta) com os dados previstos (linha azul) pelos modelos no período selecionado. Em termos quantitativos, podemos fazer essa comparação calculando métricas de acurácia, como o RMSE:
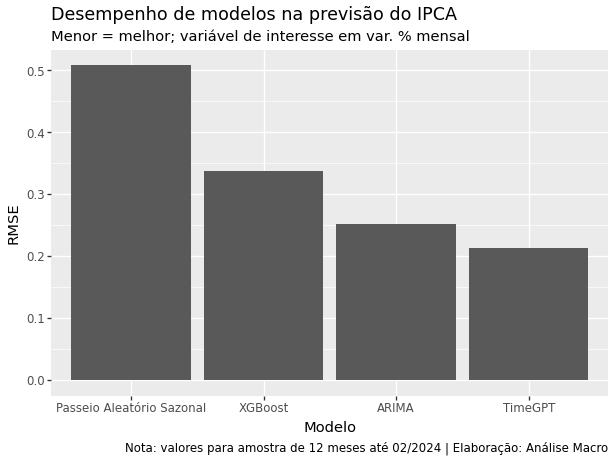
O gráfico acima mostra o RMSE calculado para a amostra de teste em consideração. Quanto menor for o valor desta métrica, menos erráticas são as previsões do modelo. Sendo assim, podemos dizer que o modelo com o melhor desempenho para prever o IPCA é o modelo de inteligência artificial TimeGPT. Note, novamente, que para amostras diferentes os resultados podem ser completamente diferentes (fica como exercício a aplicação de validação cruzada).
Estes resultados nos levam a uma resposta afirmativa para a questão inicial do exercício, ou seja, realmente precisamos de IA em tarefas preditivas? A análise isolada dos resultados certamente nos inclinaria a adotar modelos de IA para fins de previsão, mas a acurácia do modelo é apenas um dos fatores relevantes em uma tarefa preditiva. Aqui não estamos discutindo sobre fatores como custo de operação, tempo de processamento, interpretação de resultados, dentre outros. Apesar dos resultados interessantes obtidos, estes outros fatores também precisam ser levados em consideração na tomada de decisão.
Conclusão
Imagine que você tenha uma “simples” tarefa: prever o futuro de uma variável econômica relevante, como a taxa de inflação do país. Existem diversas abordagens para cumprir esta missão, desde o uso de modelos preditivos econométricos, modelos de machine learning ou até mesmo modelos de inteligência artificial (IA). Qual caminho escolher? Qual abordagem é a melhor? Neste artigo tentamos dar uma resposta para estas perguntas, usando como exemplo o IPCA como variável de interesse.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.

