O ciclo de análise de dados é uma poderosa metodologia de trabalho para resolver problemas através de dados. Com ela podemos ter uma visão geral sobre as etapas do processo, o que é fundamental para não se perder no caminho. No entanto, apenas ter essa compreensão não é suficiente, é preciso dar o próximo passo: colocar em prática uma análise de dados.
Nesse artigo mostramos como resolver um problema do cotidiano de todo brasileiro proprietário de algum veículo: em qual posto o combustível está mais barato? Usamos ferramentas de análise de dados como o Shiny para desenvolver uma solução com dados públicos, aplicando todo o ciclo de análise de dados através das linguagens R e Python.
Definição do problema e objetivos
A definição do problema a ser resolvido requer o conhecimento ou expertise na área de atuação. No caso dos preços de combustíveis sabemos que, com base na teoria econômica, pode existir o problema da informação assimétrica. Esse problema se refere a quando, em uma transação, uma das partes possui mais ou melhor informação do que a outra, o que pode criar um desequilíbrio no poder de negociação.
No caso do preço dos combustíveis, o dono do posto provavelmente possui mais e melhor informação do que o cliente que apenas vai abastecer seu veículo. O dono do posto define o preço do combustível com base em diversas variáveis e o preço na concorrência pode ser uma delas. O cliente, geralmente, abastece seu veículo no posto mais próximo e não possui conhecimento sobre o preço praticado no próximo posto. Assim, o dono de um posto pode praticar preços maiores do que a concorrência explorando a assimetria de informação. Essa é uma situação do cotidiano do brasileiro: o carro acusa que está na reserva, o motorista pára no posto A e abastece, roda mais alguns metros ou quilômetros e descobre que no posto B o preço era menor. ?
Sendo assim, vamos tentar resolver esse problema: reduzir a assimetria de informação referente ao preço de combustíveis. E utilizaremos a análise de dados com o objetivo de que haja menos surpresas no orçamento familiar do motorista e cliente de posto. Isso é extremamente relevante pois, por exemplo, a gasolina representa 4,7% do orçamento mensal das famílias brasileiras, conforme dados do IPCA/IBGE de março/2023, constituindo o subitem de maior peso dentro da cesta de produtos e serviços considerados na pesquisa.
Identificação e coleta de dados
Existem dados sobre o problema que queremos analisar? Onde os dados estão disponibilizados? Como os dados podem ser coletados? Os dados são confiáveis?
Essas são apenas algumas das perguntas pertinentes nesta etapa do ciclo de análise de dados. Felizmente, os dados de preços de combustíveis existem no Brasil e são disponibilizados publicamente para livre acesso pela ANP. No site é possível encontrar arquivos de dados sobre combustíveis de automotivos e gás de botijão, agregados por semestre, mês ou semana. Além disso, a agência ainda disponibiliza os metadados, que é uma boa prática e ajuda a entender os dados.
Agora que identificamos os dados, vamos definir o que precisamos para a análise e prosseguir para a coleta de dados. Para simplificar, vamos restringir a nossa análise aos dados do combustível gasolina comum nas 4 últimas semanas e somente para uma cidade, vamos escolher Rio de Janeiro-RJ como exemplo. Os dados a nível de Brasil para esse recorte estão disponíveis neste link. Note que o link pode estar quebrado no momento que você tentar acessá-lo, pois os sites do governo mudam com frequência.
Para coletar os dados, e para as demais etapas do projeto, vamos utilizar linguagem de programação. Na prática, é possível utilizar qualquer linguagem moderna para ciência de dados, como R e Python, pois independentemente da escolha é possível atingir o mesmo resultado, ou algo muito semelhante.
Abaixo estão os dados brutos coletados do site da ANP:
# Carregar pacotes library(readr) # Carregar dados brutos link_anp <- paste0( "https://www.gov.br/anp/pt-br/centrais-de-conteudo/dados-abertos/", "arquivos/shpc/qus/ultimas-4-semanas-gasolina-etanol.csv" ) dados_brutos <- readr::read_csv2(link_anp) head(dados_brutos)
Pré-processamento e análise exploratória de dados
Como pode ser visto, os dados da ANP são disponibilizados em formato CSV com várias colunas e linhas com informações sobre localidade, posto, preço de venda, data, bandeira e etc. Nosso interesse é nos dados de preço de venda da gasolina comum na cidade do Rio de Janeiro nas últimas 4 semanas. Aplicando esses filtros, chegamos na tabela de dados processados abaixo:
# Dados de preço da gasolina na cidade do Rio de Janeiro-RJ dados_rio <- dados_brutos |> dplyr::filter( `Estado - Sigla` == "RJ", Municipio == "RIO DE JANEIRO", Produto == "GASOLINA" ) |> dplyr::mutate(data = lubridate::dmy(`Data da Coleta`)) |> dplyr::select( -c( "Produto", "Valor de Compra", "Unidade de Medida", "Municipio", "Estado - Sigla", "Regiao - Sigla", "Data da Coleta" ) ) head(dados_rio)
| Revenda | CNPJ da Revenda | Nome da Rua | Numero Rua | Complemento | Bairro | Cep | Valor de Venda | Bandeira | data |
|---|---|---|---|---|---|---|---|---|---|
| MULTI POSTO CENTRO AUTOMOTIVO LTDA. | 07.303.380/0001-82 | ESTRADA DO QUITUNGO | 1610 | NA | BRAZ DE PINA | 21215-565 | 5.29 | BRANCA | 2023-08-29 |
| POSTO E GARAGEM DOM HELDER CAMARA LTDA | 04.802.584/0001-70 | AVENIDA DOM HELDER CAMARA | 4539 | NA | DEL CASTILHO | 20771-000 | 5.59 | RAIZEN | 2023-08-28 |
| POSTO E AUTO SERVICO INSULANO LTDA | 07.634.487/0001-03 | ESTRADA DO DENDE | 400 | NA | TAUA / ILHA DO GOVERNADOR | 21920-000 | 5.69 | VIBRA | 2023-08-29 |
| POSTO MANÉ GARRINCHA DE BOTAFOGO LTDA. | 07.877.289/0001-70 | RUA VOLUNTARIOS DA PATRIA | 308 | NA | BOTAFOGO | 22270-010 | 5.77 | RAIZEN | 2023-08-29 |
| POSTO DE GASOLINA JAGUAR DO ANIL LTDA | 07.752.635/0001-94 | AVENIDA TEN. CEL. MUNIZ DE ARAGAO | 1240 | NA | ANIL | 22765-008 | 5.35 | BRANCA | 2023-08-30 |
| MARQUES’S PETER AUTO POSTO LTDA | 05.570.770/0001-93 | RUA JOSE DOMINGUES | 250 | NA | ENCANTADO | 20756-130 | 5.68 | VIBRA | 2023-08-28 |
Em poucos comandos, os dados já estão prontos para serem analisados! Para entender mais sobre tratamento de dados veja o curso de Programação para Análise de Dados da Análise Macro.
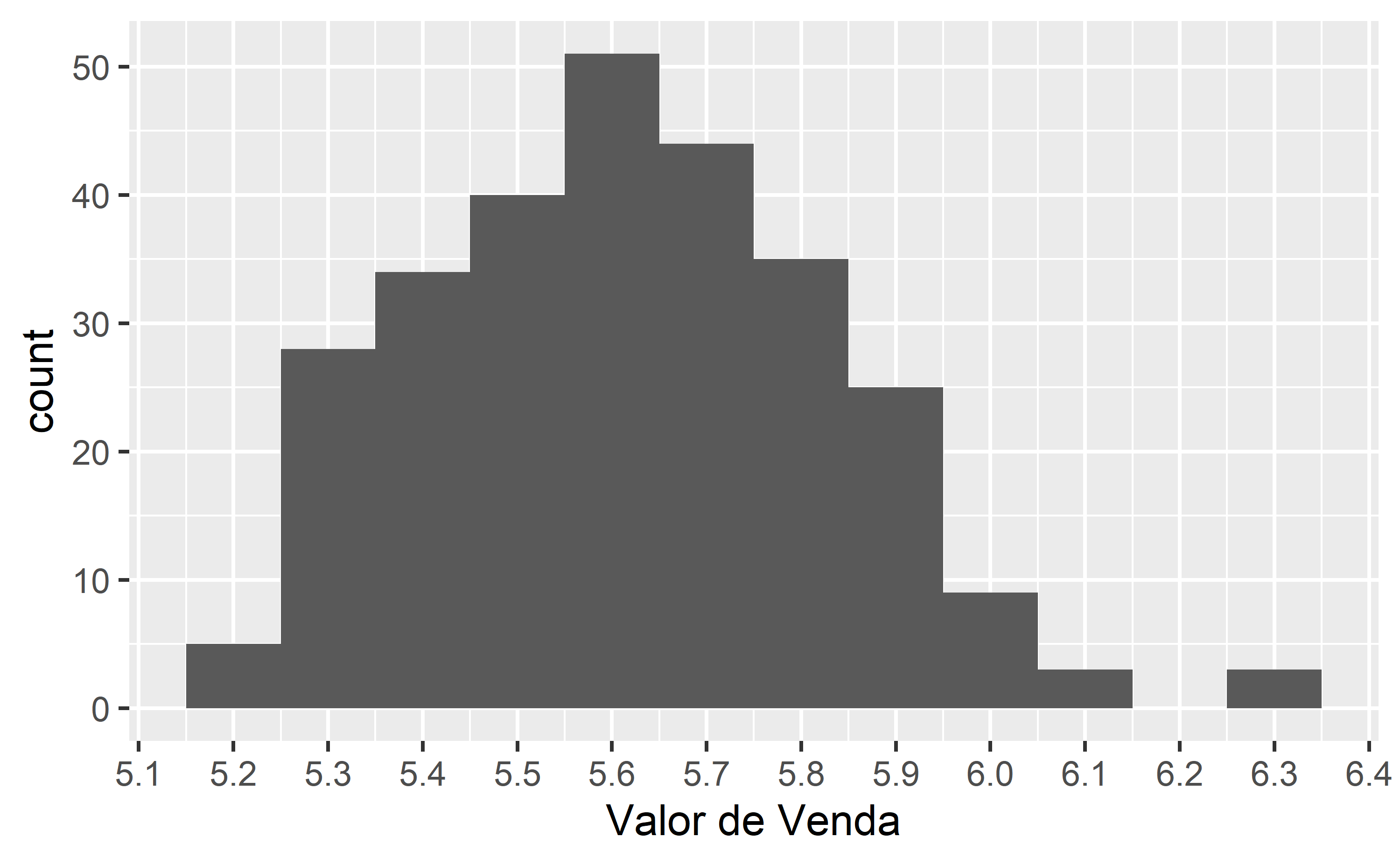
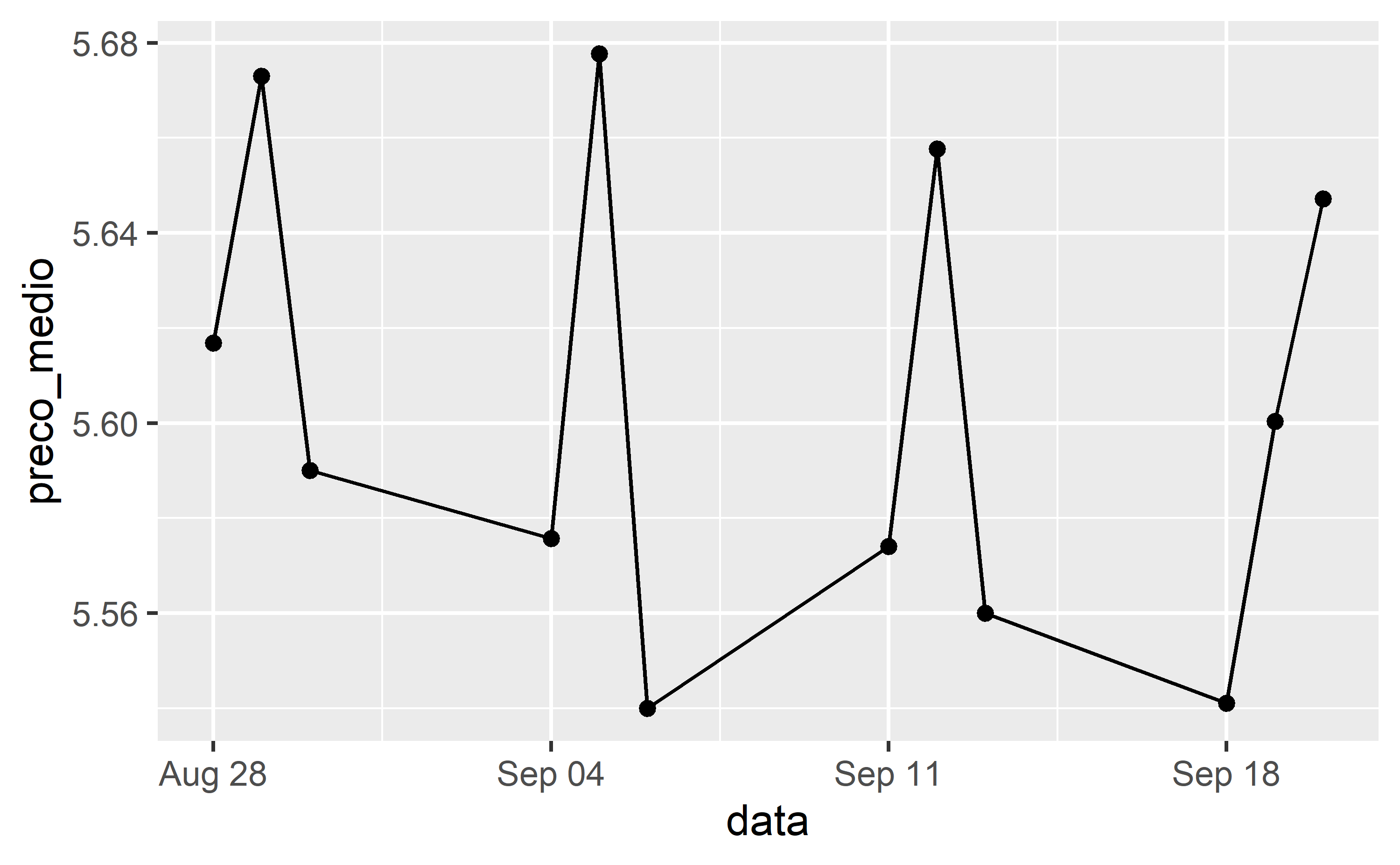
Abaixo plotamos o histograma dos preços e sua evolução temporal média por cada data de coleta:
# Histograma dados_rio |> ggplot2::ggplot() + ggplot2::aes(x = `Valor de Venda`) + ggplot2::geom_histogram(binwidth = 0.1) + ggplot2::scale_x_continuous(n.breaks = 10)
# Linha dados_rio |> dplyr::summarise(preco_medio = mean(`Valor de Venda`, na.rm = TRUE), .by = data) |> ggplot2::ggplot() + ggplot2::aes(x = data, y = preco_medio) + ggplot2::geom_line() + ggplot2::geom_point()
Poderíamos continuar explorando mais a fundo os dados, mas vamos tentar avançar para as próximas etapas e tentar desenvolver a solução para o problema que queremos resolver. Na prática, podemos ir e voltar entre uma ou outra etapa do ciclo de análise de dados conforme a necessidade. O ciclo de análise de dados não é um processo linear e podemos voltar nessa etapa para fazer ajustes e explorações adicionais.
Proposta de solução
Temos um problema definido para ser solucionado, temos os dados e sabemos um pouco sobre como eles se comportam. O que está faltando agora é desenvolver a solução baseada nestes dados, usando ferramentas para esta finalidade, como o Shiny. Dashboards estão presentes em todo lugar atualmente, então não estamos inventando a roda e não precisaremos treinar o usuário para utilizar essa solução.
O Shiny é uma biblioteca de desenvolvimento de dashboards e aplicativos web interativos, implementada em R e Python. Com ela é possível criar interfaces customizadas, alimentar dados, habilitar filtros e botões de interação e muitos mais! Para saber mais sobre o Shiny confira o curso de Produção de Dashboards da Análise Macro.
A ideia é fazer uma Prova de Conceito (PoC, na sigla em inglês), com a finalidade de entregar uma solução o mais rápido possível. Com isso feito, torna-se mais claro no projeto de análise de dados, com base em feedbacks e monitoramento, o que deu certo e o que precisa ser melhorado, assim como as próximas soluções analíticas que podem ser lançadas.
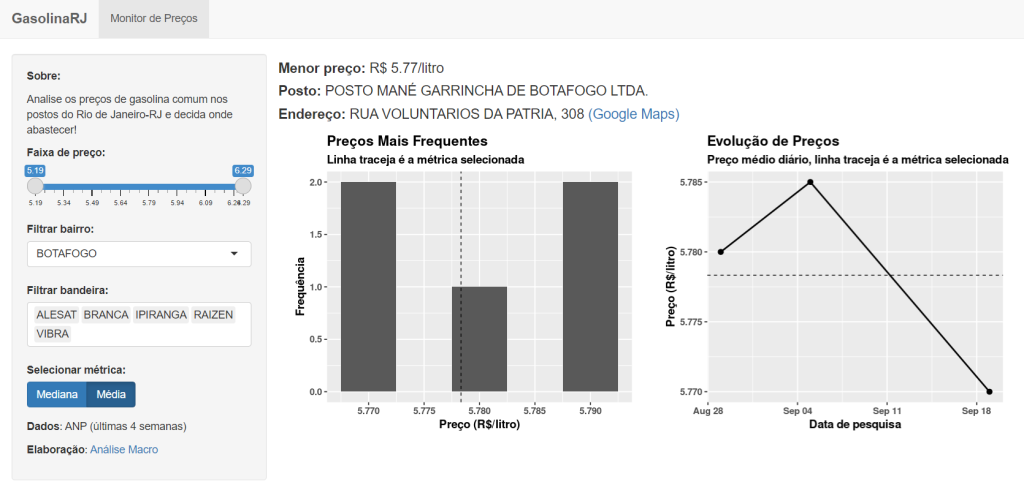
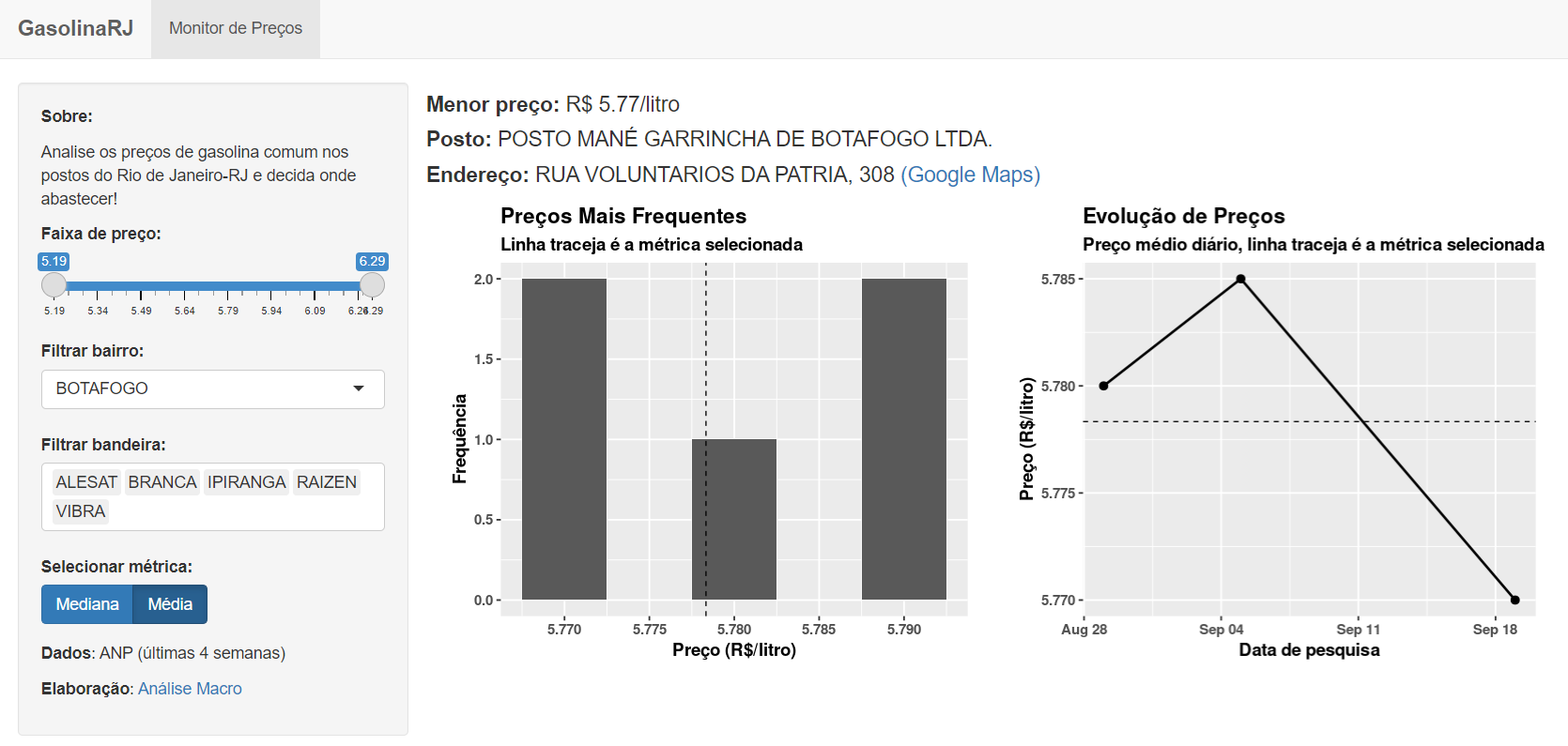
Abaixo expomos a implementação da dashboard analítica dos preços de gasolina comum praticados na cidade do Rio de Janeiro.
Acesse a dashboard pelo link: https://analisemacro.shinyapps.io/gasolinarj_r/
Outros recursos podem ser implementados e há bastante espaço para melhorar os existentes. Além disso, os dados da ANP para determinados pontos de coleta de preços podem ser descontinuados a qualquer momento, o que requer cuidado ao analisar os dados.
Validação da solução
Na etapa de validação dentro do ciclo de análise de dados o objetivo é verificar se o problema definido pode ser solucionado com a proposta de solução desenvolvida. Note que não desenvolvemos nenhum modelo que permita utilizar métricas tradicionais de avaliação, como RMSE ou Acurácia, portanto precisaremos avaliar a solução de maneira subjetiva ou coletando feedback de usuários. A segunda opção só é possível após um certo tempo, então vamos prosseguir com a primeira.
O problema era a assimetria de informação: o motorista ia no posto A e abastecia e depois verificava que no posto B o preço era menor. A dashboard desenvolvida ajuda o motorista a evitar esse tipo de situação? Possivelmente sim! Com os dados na palma da mão o motorista pode facilmente verificar os postos mais próximos de sua localização, assim como consultar os dados de preço praticados recentemente e historicamente. Além disso, os elementos da dashboard apresentam alguns indicadores para auxiliar o motorista na tomada de decisão.
Em suma, acreditamos que essa primeira versão da dashboard soluciona em boa medida o problema de assimetria de informação.
Implantação da solução
Na última etapa do ciclo de análise de dados é preciso tomar uma decisão sobre como a solução, uma vez que tenha sido validada, será implementada e/ou comunicada para seus usuários. No caso de uma dashboard, a implementação pode se dar por meio do processo conhecido como deploy ou publicação, que compreende disponibilizar a dashboard, usualmente por um link, para livre acesso dos usuários.
Dashboard desenvolvidas no framework Shiny podem ser publicadas de diversas formas, desde as mais simples até as mais sofisticadas. Uma possibilidade é utilizar o serviço gratuito Shinyapps.io: basta cadastrar uma conta de usuário e gerar uma chave de token para fazer o deploy da dashboard. Ao final do processo é gerado um link, como esse da dashboard acima: https://analisemacro.shinyapps.io/gasolinarj_r/
Após a publicação da dashboard (ou durante o desenvolvimento do projeto) é importante documentar todo o projeto e organizar as informações relevantes para comunicar essa solução aos potenciais usuários. Essa etapa é crucial para o sucesso do projeto, afinal não queremos criar dashboards que ninguém irá acessar. Então é importante comunicar bem as informações, criar storytelling de dados, imagens, vídeos, etc. para que o usuário consiga rapidamente compreender como a solução analítica pode ajudar ele.
Conclusão
Chegamos ao final dessa jornada por dentro da implementação de um projeto de análise de dados. O objetivo foi resolver um problema real com dados reais, visando explorar os desafios que podem ser encontrados no dia a dia de trabalho. Percorremos todas as etapas do ciclo analítico, desde a definição do problema até o deploy da solução desenvolvida, dando ênfase nos conceitos e possibilidades que se encontram no caminho. Escolhemos usar ferramentas modernas e práticas para projetos de dados, deixando claro que podem ser usadas outras alternativas, sem prejuízo dos resultados finais.
Quer aprender mais?
- Cadastre-se gratuitamente aqui no Boletim AM e receba toda terça-feira pela manhã nossa newsletter com um compilado dos nossos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas;
- Quer ter acesso aos códigos, vídeos e scripts de R/Python desse exercício? Vire membro do Clube AM aqui e tenha acesso à nossa Comunidade de Análise de Dados;
- Quer aprender a programar em R ou Python com Cursos Aplicados e diretos ao ponto em Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas? Veja nossos Cursos aqui.

