O ponto inicial de aprendizado do Python, principalmente para a análise de dados, configura-se em entender os tipos de dados e suas estruturas. Essa etapa se mostra fundamental na trilha para quem inicia nesse mundo, e quem decide pular essa etapa acaba obtendo dificuldades futuras. No post de hoje iremos apresentar os pontos fundamentais dos tipos e estrutura de dados do Python, focando para análise de dados.
Tipos de dados
Os tipos de dados são os tipos dos objetos atribuídos dentro do Python. Vamos elencar quatro importantes
- String: usualmente caracteres, envoltos de aspas - 'Analise', 'macro', 'python!';
- Float: são números reais separados por decimal - 4.2, 3.5, 3.8;
- Integer: são números reais inteiros - 8, -5, 1;
- Boolean: são valores lógicos - True, False.
Vamos realizar um exercício e ver a forma que eles se inserem dentro do Python. Iremos atribuir objetos dados e ver quais os seus tipos com a função type().
analise = 'Análise Macro' type(analise) # str first_float = 8.7 type(first_float) # float first_integer = 5 type(first_integer) # int first_boolean = True type(first_boolean) # bool
Estruturas de dados
Agora que vimos quais são os tipos de dados, devemos entender o que ocorre quando agrupamos eles em múltiplos valores juntos. Esse agrupamento de dados possui o nome de coleção (collection). O Python, por padrão, possui diversas coleção de tipos de objetos, também é possível trabalhar com outros (como vamos ver) importando módulos.
Começaremos com a coleção lista, que compreende-se em um conjunto de valores (homogêneos ou heterogêneos) , que pode ser juntados por meio de um colchete.
lista = [5, 3, 9, 0] type(lista) # list lista_ = [5, 6, 9, 'analise', True]
NumPy - Arrays
NumPy é um módulo do Python para computação numérica. As arrays do NumPy podem ser definidas como uma coleção de dados do mesmo tipo em n dimensões. Mostraremos primeiro uma array de uma dimensão.
import numpy array = numpy.array([5, 4, 2, 9]) type(array) # numpy.ndarray
Como vimos, a função array do NumPy transforma uma lista de valores em uma nova estrutura de dados.
Pandas - DataFrames
Data Frames são as mais conhecida estruturas de dados das linguagens de programação focadas em análise de dados. É possível utilizar no Python através do módulo Pandas (um dos mais conhecidos do Python). O nome desse módulo é uma abreviação de panel data of econometrics. O segredo do Pandas está em poder utilizar a estrutura de dados do numpy em conjunto de suas funções para realizar a montagem e manipulação de dados.
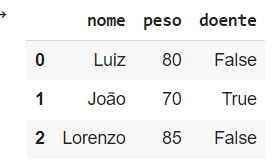
import pandas as pd linha_1 = numpy.array(['Luiz', 80, False]) linha_2 = numpy.array(['João', 70, True]) linha_3 = numpy.array(['Lorenzo', 85, False]) data = pd.DataFrame(data = [linha_1, linha_2, linha_3], columns = ['nome', 'peso', 'doente']) data
Aprenda mais!
Para conhecer mais sobre a linguagem Python, e descobrir como você pode realizar sua aplicação no mundo real, veja nossos cursos de Estatística usando R e Python, e R e Python para Economistas.
____________________
Oferta Especial!
No próximo dia 17, das 9h às 19h da manhã, você terá a chance de participar do pré-lançamento do treinamento Análise de Dados Macroeconômicos e Financeiros no R. Para concorrer a uma das vagas com desconto, acesse o link e conheça os detalhes.
____________________

