Neste post vamos mostrar como utilizar o recém lançado pacote basedosdados, que fornece um jeito simples para acessar o datalake da organização Base dos Dados. São centenas de dados disponíveis, já tratados e de fácil compatibilização entre si. Entre as bases disponíveis nesse datalake estão RAIS, CAGED, comércio exterior, dados eleitorais e dados de CNPJ.
Para acessar os dados é necessário ter uma conta e um projeto no Google Cloud. Assim, tendo um projeto, é preciso colocar a sua chave identificadora utilizando a função "set_billing_id".
library(tidyverse) library(basedosdados) basedosdados::set_billing_id(XXXXXX) # trocar para o seu identificador
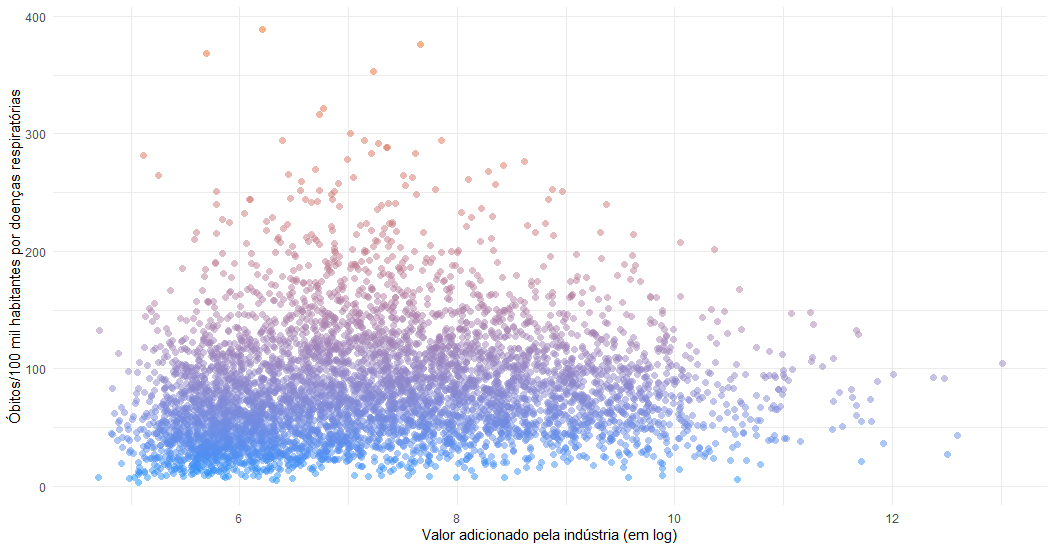
Iremos utilizar um exemplo simples para mostrar a facilidade do cruzamento de dados. Nota-se que o objetivo não é fazer nenhum tipo de inferência, mas apenas mostrar a funcionalidade do pacote. Iremos cruzar três variáveis a nível municipal: População, valor adicionado pela indústria e óbitos por doenças respiratórias (CID-J). As duas primeiras são provenientes do IBGE, já a última vem do Sistema de Informações sobre Mortalidade (SIM), do Datasus. Cada "query", ou seja, a seleção dos dados, é feita por meio de SQL.
#óbitos query1 <- "SELECT ano, id_municipio, SUM(numero_obitos) AS obitos FROM `basedosdados.br_ms_sim.municipio_causa` WHERE LEFT(causa_basica,1) = 'J' # Apenas doenças respiratórias GROUP BY ano, id_municipio" obitos <- read_sql(query1) #população query2 <- "SELECT * FROM `basedosdados.br_ibge_populacao.municipios`" pop <- read_sql(query2) #PIB query3 <- "SELECT id_municipio, ano, VA_industria FROM `basedosdados.br_ibge_pib.municipios`" pib <- read_sql(query3)
Uma grande facilidade trazida pelo Base dos Dados é fornecer centralização e padronização. Por exemplo, nesse caso, podemos juntar as três tabelas pelo Código IBGE de cada município e pelo ano, que já estão com o mesmo nome em todas elas. Quem já trabalhou com dados municipais sabe que os identificadores dos municípios podem estar em formatos diferentes ou até não estarem presentes, dificultando bastante o tratamento dos dados.
Assim, juntando os três data frames e filtrando apenas para valores de 2018, podemos mostrar a relação entre óbitos por doenças respiratórias e o valor per capita adicionado pela indústria.
df <- left_join(obitos, pop, by = c("id_municipio", "ano"))
df <- left_join(df, pib, by = c("id_municipio", "ano"))
df_18 <- df %>%
filter(ano == 2018) %>%
mutate(obitos_pc = obitos*100000/populacao,
industria_pc = VA_industria/populacao,
log_industria_pc = log(industria_pc),
pc = predict(prcomp(~log_industria_pc+obitos_pc, .))[,1])
ggplot(data = df_18, aes(x = log_industria_pc, y = obitos_pc, color = pc)) +
geom_point(show.legend = FALSE, shape = 16, size = 2, alpha = .5) +
theme_minimal() +
ylab("Óbitos/100 mil habitantes por doenças respiratórias") +
xlab("Valor adicionado pela indústria (em log)") +
scale_color_gradient(low = "#0091ff", high = "#f0650e")
Conheça o Curso de Avaliação de Políticas Públicas usando o R


