Visualização de dados é uma habilidade essencial, seja para quando você quer plotar suas despesas e receitas mensais ou quando é pra gerar um relatório mais apresentável no seu trabalho. E com o pacote {ggplot2} essa tarefa fica mais simples, fácil e escalável. Neste exercício, vamos descobrir um pouco da mecânica por trás do pacote e como usá-lo para gerar seus primeiros gráficos!
Para reproduzir o exercício a seguir você precisará dos seguintes pacotes:
# Carregar pacotes/dependências library(ggplot2) # CRAN v3.3.5 library(magrittr) # CRAN v2.0.2
Criando gráficos com ggplot2
O {ggplot2} funciona em camadas e, para facilitar o entendimento, pense que ao criar um {ggplot2} você está fazendo uma receita de torta onde você começa adicionando a base, depois a(s) camada(s) do recheio e, por fim, a cobertura. Tanto quanto o resultado final das tortas depende da habilidade da(o) confeiteira(o), o gráfico de {ggplot2} depende do empenho e conhecimento do(a) programador(a). E ambos podem ficar incrivelmente prazerosos aos olhos depois de prontos!
Com isso em mente, vamos a um exemplo criando um gráfico simples de dispersão. Para tal, usaremos o dataset economics, disponível no próprio pacote. Esse conjunto de dados traz informações de indicadores econômicos agregados da economia norte americana (EUA), possuindo como característica o atributo de série temporal.
Abaixo, por conveniência, salvamos os dados em objetos para trabalharmos com eles adiante. Perceba que eles estão disponíveis em dois formatos, wide e long, e é necessário que os dados sejam de classe data.frame/tibble. Primeiro uma inspeção visual nos dados:
# Datasets de exemplo: dados econômicos dos EUA dados <- ggplot2::economics dados_long <- ggplot2::economics_long dados # # A tibble: 574 x 6 # date pce pop psavert uempmed unemploy # <date> <dbl> <dbl> <dbl> <dbl> <dbl> # 1 1967-07-01 507. 198712 12.6 4.5 2944 # 2 1967-08-01 510. 198911 12.6 4.7 2945 # 3 1967-09-01 516. 199113 11.9 4.6 2958 # 4 1967-10-01 512. 199311 12.9 4.9 3143 # 5 1967-11-01 517. 199498 12.8 4.7 3066 # 6 1967-12-01 525. 199657 11.8 4.8 3018 # 7 1968-01-01 531. 199808 11.7 5.1 2878 # 8 1968-02-01 534. 199920 12.3 4.5 3001 # 9 1968-03-01 544. 200056 11.7 4.1 2877 # 10 1968-04-01 544 200208 12.3 4.6 2709 # # ... with 564 more rows
A camada inicial
Para criar um gráfico do {ggplot2} sempre comece especificando a camada inicial com a função ggplot(). Essa função recebe a entrada de dados a serem plotados e também pode servir para especificar os eixos X e Y:
# Camada inicial dados %>% ggplot2::ggplot()

Especificando os eixos
Conforme esperado, a camada inicial (ou seja, a "base" da nossa torta) não tem nada de muito informativo ou que dê uma pista sobre o que a imagem/gráfico se trata. Sendo assim, devemos adicionar a próxima camada: especificar os eixos X e Y - procedimento as vezes referido como "estética do gráfico" - usando a função aes(). Para adicionar novas camadas use, ao final da linha, o símbolo de adição (+).
Usaremos como exemplo as variáveis unemploy e psavert do dataset, que representam o número de desempregados em milhares e a taxa de poupança pessoal, respectivamente:
# Camada inicial e (+) estética dos eixos dados %>% ggplot2::ggplot() + ggplot2::aes(x = unemploy, y = psavert)
Inserindo as observações
Agora já há uma informação de escala das variáveis tomando forma em ambos os eixos. O que está faltando são as observações dos dados. Para inseri-las há múltiplas possibilidades (família de funções geom_*()), mas o exercício proposto é criar um gráfico de dispersão, portanto devemos usar a função geom_point() adicionando nova camada.
# Gráfico de dispersão (obsevações) dados %>% ggplot2::ggplot() + ggplot2::aes(x = unemploy, y = psavert) + ggplot2::geom_point()
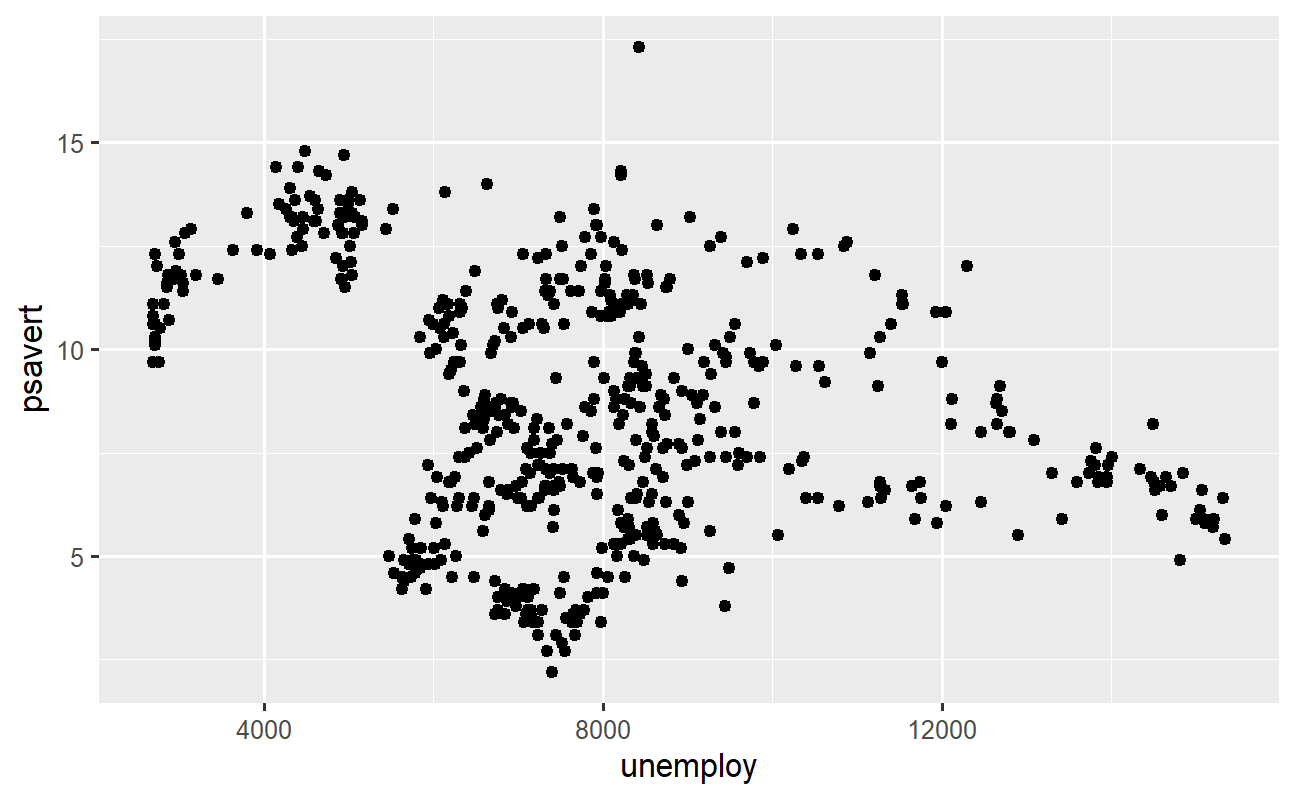 Este é o exemplo mais simples de um gráfico de {ggplot2}, porém serve para entender o fluxo de trabalho com o pacote. A partir daqui, podemos adicionar mais camadas, títulos, definir tema, enfeitar e personalizar o gráfico para torná-lo mais apresentável. Vamos focar nisso agora!
Este é o exemplo mais simples de um gráfico de {ggplot2}, porém serve para entender o fluxo de trabalho com o pacote. A partir daqui, podemos adicionar mais camadas, títulos, definir tema, enfeitar e personalizar o gráfico para torná-lo mais apresentável. Vamos focar nisso agora!
Adicionando mais camadas
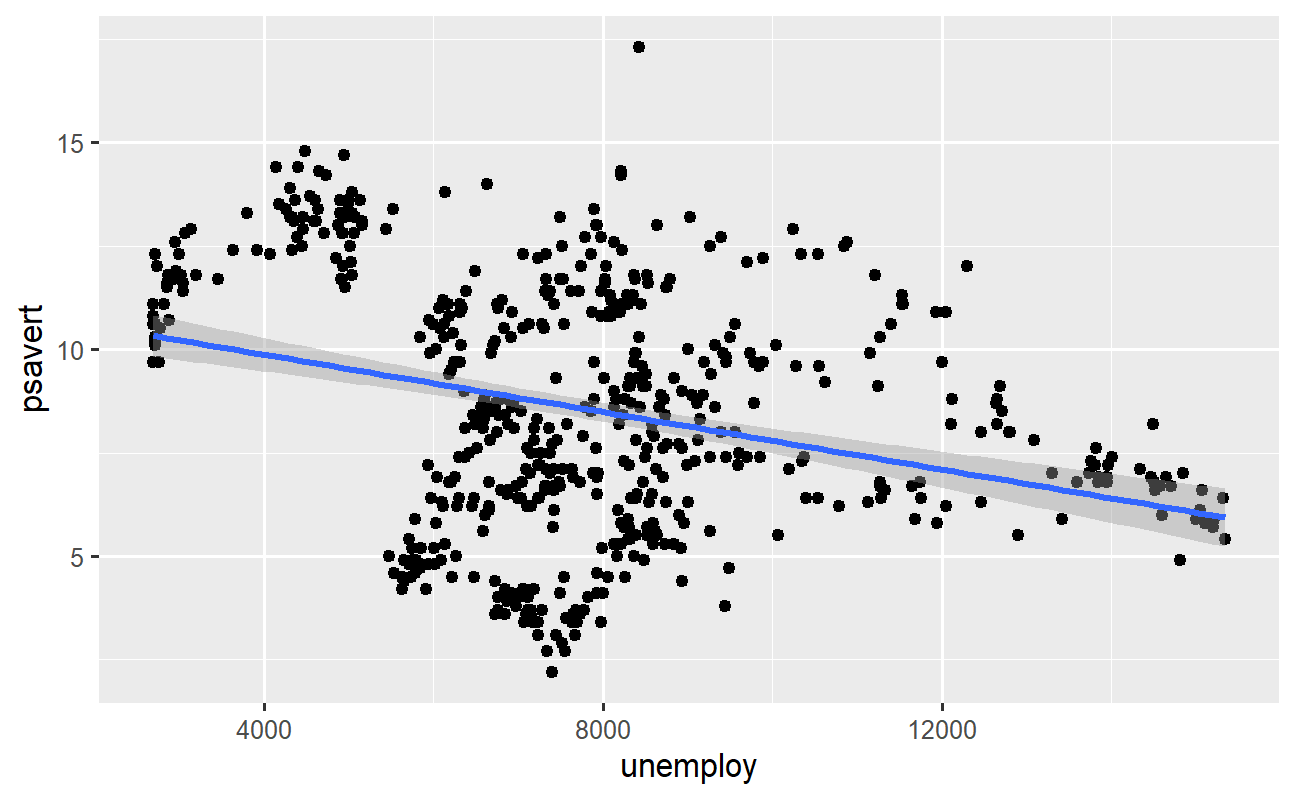
Para adicionar mais camadas referentes às observações de dados devemos usar uma das funções geom_*(). Vamos supor que o gráfico de dispersão criado acima não tenha dado uma visão clara sobre a relação entre as variáveis. Neste caso, convém adicionar uma linha de regressão entre as variáveis. A função geom_smooth() serve para este propósito, havendo algumas opções de método que podem ser especificadas (consulte a documentação):
# Gráfico de dispersão + linha de regressão entre variáveis dados %>% ggplot2::ggplot() + ggplot2::aes(x = unemploy, y = psavert) + ggplot2::geom_point() + ggplot2::geom_smooth(method = "lm")
Adicionando tema e títulos
Com os dados plotados e camadas definidas, chegou o momento de ir um pouco além e "enfeitar a torta", deixando o resultado final mais atrativo aos olhos. Nesta etapa a criatividade, a curiosidade e olhar analítico fazem diferença, mas no exemplo abaixo vamos simplificar e usar um tema gráfico padronizado, disponibilizado pelo próprio {ggplot2} (família de funções theme_*()). Por fim, adicionamos título, subtítulo, títulos dos eixos X e Y e legenda do gráfico usando a função labs(). Simples, não?
# Adicionando tema padronizado e títulos dados %>% ggplot2::ggplot() + ggplot2::aes(x = unemploy, y = psavert) + ggplot2::geom_point() + ggplot2::geom_smooth() + ggplot2::theme_light() + ggplot2::labs( title = "Relação entre Taxa de poupança e Nº de desempregados", subtitle = "Dados de 1967 a 2015", x = "Nº de desempregados (milhares)", y = "Taxa de poupança pessoal", caption = "Fonte: FRED" )
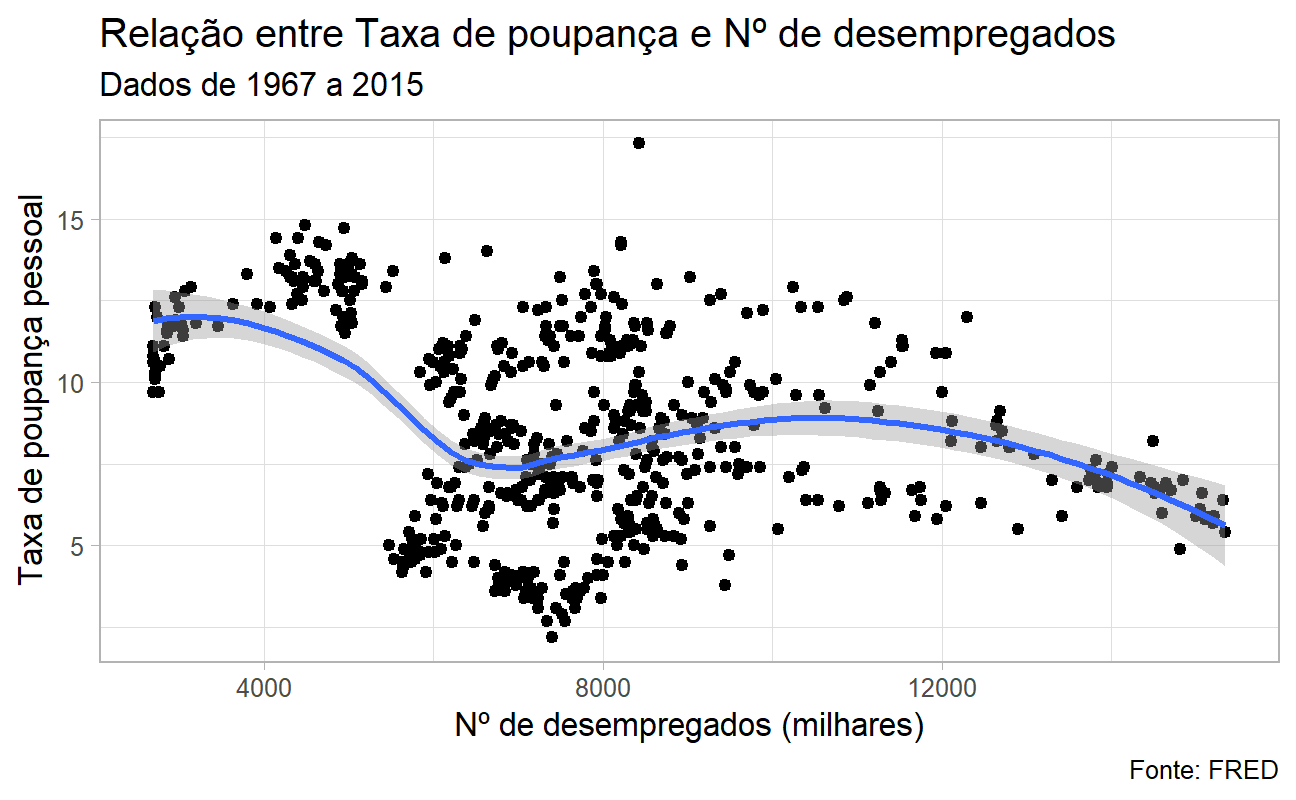
Gráfico de linha
Vamos agora explorar um pouco mais do {ggplot2}: os gráficos de linha. Você pode criar um gráfico de linha com os seus dados, geralmente se for uma série temporal, usando a função geom_line(). No exemplo abaixo, plotamos a população total em milhares dos EUA (variável pop):
# Gráfico de linha dados %>% ggplot2::ggplot() + ggplot2::aes(x = date, y = pop) + ggplot2::geom_line()
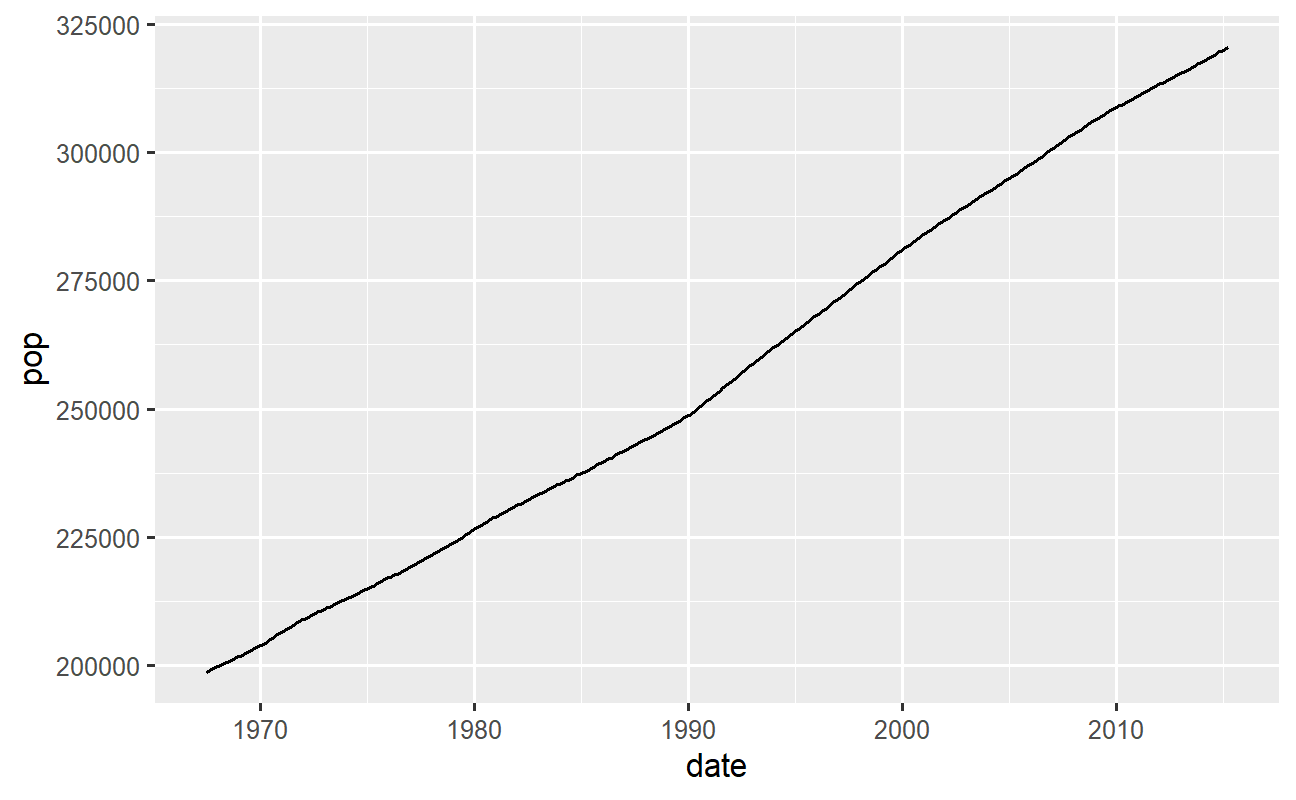
Gráfico de múltiplas linhas
Se você quer criar um gráfico com mais de uma linha, também é muito fácil: dê preferência por usar dados em formato long e especifique, no argumento color da camada da estética, o nome da coluna que identifica cada linha no gráfico (variáveis). Por exemplo:
# Gráfico de múltiplas linhas dados_long %>% ggplot2::ggplot() + ggplot2::aes(x = date, y = value, color = variable) + ggplot2::geom_line()
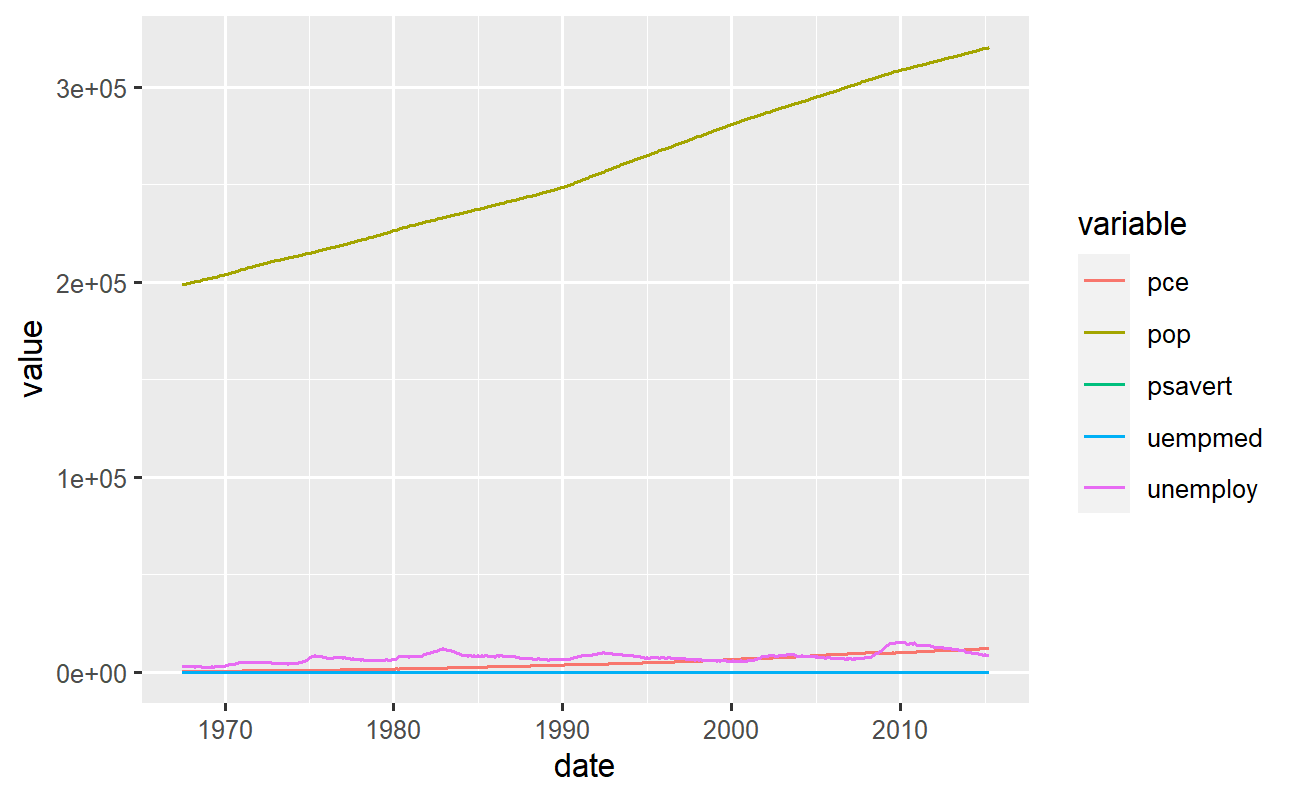
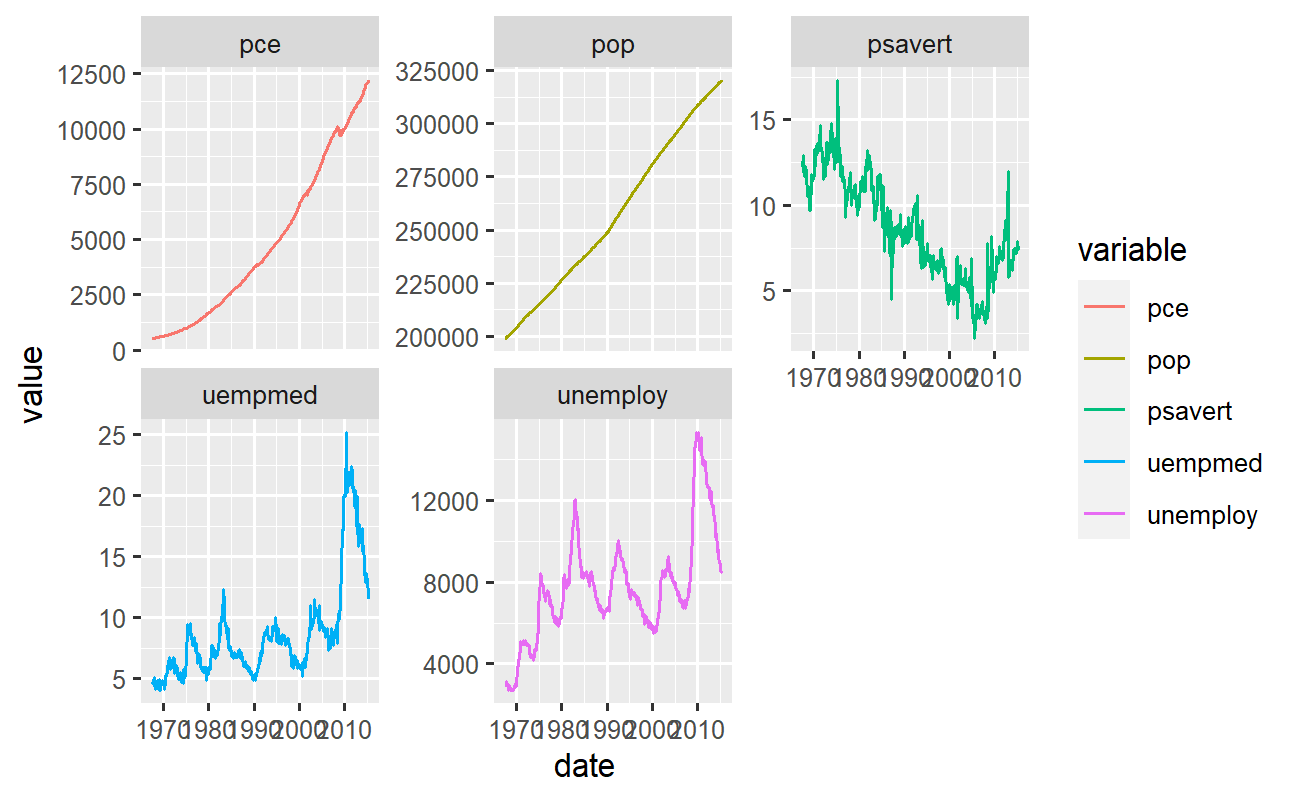
Matriz de gráficos de linhas lado a lado
Perceba que o gráfico de múltiplas linhas anterior dificultou a visualização por questão de escala das variáveis. Neste caso, convém separar cada linha em um gráfico, gerando vários gráficos organizados lado a lado. Isso pode ser feito pela função facet_wrap(), especificando a coluna com os "níveis" de separação dos gráficos e, opcionalmente, o comportamento de escala do eixo Y:
# Matriz de gráficos de linhas lado a lado dados_long %>% ggplot2::ggplot() + ggplot2::aes(x = date, y = value, color = variable) + ggplot2::geom_line() + ggplot2::facet_wrap(facets = ~variable, scales = "free_y")
Referências
Espero que estes simples exemplos tenham aguçado seu interesse por visualização de dados usando o {ggplot2}, pois este é um framework fantástico para apresentar dados. Veja abaixo algumas visualizações criadas com o {ggplot2} publicadas no blog da Análise Macro:
Posts dos gráficos:
- Acessando dados do Censo Demográfico com o R
- Detecção de plágio com NLP no R: o caso Decotelli
- Analisando mais de 9 mil papers econômicos desde 2005
- Teto de Gastos: análise de sentimentos com dados do Twitter
E para se aprofundar, conheça o nosso Curso Gráficos com ggplot2.

