Há alguma discussão sobre a manutenção do controle da inflação no Brasil, por conta do recente repique dos preços no atacado e também por alguma pressão no subgrupo alimentação no domicílio. Para explorar esses pontos, podemos verificar o comportamento da inflação cheia e dos núcleos de inflação, que buscam justamente expurgar esses efeitos de curto prazo, concentrando-se na inflação subjacente. Para isso, como ensino no nosso Curso de Análise de Conjuntura usando o R, podemos pegar os dados de inflação diretamente do SIDRA/IBGE com o R.
A propósito, darei uma aula ao vivo amanhã, 29/09, sobre Dados Econômicos no R. Para garantir o seu acesso à aula, se inscreva aqui.
########################################################### ############ Análise da Inflação no Brasil ############### library(sidrar) library(tidyverse) library(tstools) library(BETS) ### Inflação cheia ipca = '/t/1737/n1/all/v/2266/p/all/d/v2266%2013' %>% get_sidra(api=.) %>% mutate(date = parse_date(`Mês (Código)`, format="%Y%m")) %>% rename(indice = Valor) %>% mutate(inflacao_mensal = (indice/lag(indice,1)-1)*100, inflacao_anual = (indice/lag(indice,12)-1)*100) %>% select(date, indice, inflacao_mensal, inflacao_anual) %>% as_tibble()
O código acima ilustrar como é possível pegar os dados do número índice do IPCA, o principal índice de inflação do país e a partir dele, calcular a inflação mensal e a inflação acumulada em 12 meses.
Uma vez que tenhamos a chamada inflação cheia, é possível pegar os sete núcleos de inflação criados e atualizados pelo Banco Central. Para pegar esses dados, podemos usar o pacote BETS, o pacote Quandl, o pacote rbcb ou mesmo a própria API do Banco Central. A seguir, pegamos os dados com o pacote BETS.
codes = c(4466,11426,11427,16121,16122, 27838, 27839)
nucleos = BETSget(codes, from='2012-01-01', data.frame=T)
data_nucleos = matrix(NA, nrow=nrow(nucleos[[1]]),
ncol=length(codes))
for(i in 1:length(codes)){
data_nucleos[,i] = t(nucleos[[i]]$value)
}
colnames(data_nucleos) = c('ipca_ms', 'ipca_ma', 'ipca_ex0',
'ipca_ex1', 'ipca_dp', 'ipca_ex2',
'ipca_ex3')
nucleos_vm =
data_nucleos %>%
as_tibble() %>%
mutate(date = nucleos[[1]]$date) %>%
select(date, everything())
nucleos_12m =
data_nucleos %>%
ts(start=c(2006,07), freq=12) %>%
acum_p(12) %>%
as_tibble() %>%
mutate(date = nucleos[[1]]$date) %>%
select(date, everything()) %>%
drop_na()
Também podemos voltar ao SIDRA/IBGE, para pegar os dados do subgrupo alimentação no domicílio.
alim_dom_01 = get_sidra(api='/t/1419/n1/all/v/63/p/all/c315/7171/d/v63%202')$Valor alim_dom_02 = get_sidra(api='/t/7060/n1/all/v/63/p/all/c315/7171/d/v63%202')$Valor alim_dom = full_join(alim_dom_01, alim_dom_02) %>% mutate(date = parse_date(`Mês (Código)`, format="%Y%m")) %>% mutate(inflacao_12m = acum_p(Valor,12)) %>% select(date, Valor, inflacao_12m)
Por fim, podemos criar os limites da meta de inflação para ilustrar se há algum rompimento em relação à inflação efetivamente observada.
meta = c(rep(4.5,12*7-11), rep(4.25, 12), rep(4, 8))
meta_max = c(rep(4.5+2,12*5-11), rep(4.5+1.5,12*2),
rep(4.25+1.5,12), rep(4+1.5, 8))
meta_min = c(rep(4.5-2,12*5-11), rep(4.5-1.5,12*2),
rep(4.25-1.5,12), rep(4-1.5, 8))
data_meta =
tibble(date = seq(as.Date('2012-12-01'), as.Date('2020-08-01'),
by='1 month'),
meta_min = meta_min,
meta = meta,
meta_max = meta_max)
O gráfico com todos esses componentes está ilustrado a seguir.
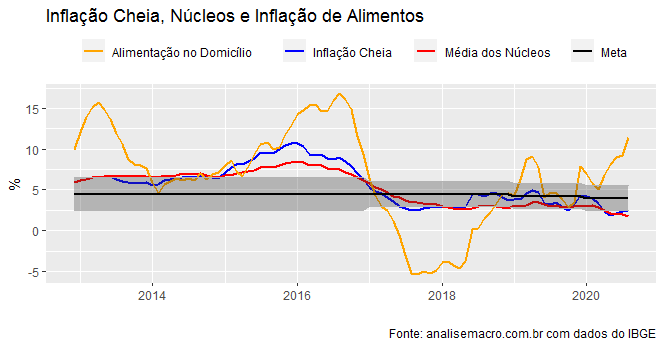
Há, de fato, um repique na inflação de alimentos, que tem sido causado por diferentes vetores. Contudo, tanto a inflação cheia quanto a média dos 7 núcleos de inflação seguem bastante comportadas. Não me parece, diga-se, haver preocupação em relação à trajetória da inflação no país.

