Um dos motivos de eu ter me afastado do debate público no Brasil é que ele é bizarramente viesado e com uma ausência gritante de análise de dados. Mais vale a opinião de quem nunca estudou economia do que a análise série das bases de dados disponíveis. E praticamente toda semana tem um exemplo dessa (triste) realidade. A polêmica atual é o preço do arroz: será que ele explodiu mesmo?
Para ver isso, podemos acessar a variação do preço do arroz para o consumidor final, que pode ser captada dentro do Índice de Preços ao Consumidor Amplo, o famoso IPCA. O IPCA é composto (atualmente) por 377 subitens, dentre eles o arroz, que está no subgrupo Alimentação no Domicílio, que por sua vez pertence ao grupo Alimentação e Bebidas - caso você não faça ideia do que eu estou falando, considere fazer nosso Curso de Análise de Conjuntura usando o R.
Uma vez definido que queremos ver o comportamento da variação do preço do arroz ao longo do tempo, podemos pegar os dados no SIDRA/IBGE. Para isso, podemos usar o pacote sidrar e importar os dados diretamente para o RStudio. A seguir, o início do script que eu montei para pegar apenas os dados do subitem arroz. Observe que há três séries, de acordo com a POF a que faz referência a série.
############################################################### ###### Evolução do preço do arroz ao longo do tempo ########### ############################################################### library(tidyverse) library(sidrar) library(tstools) serie01 = get_sidra(api = '/t/2938/n1/all/v/63/p/all/c315/7173/d/v63%202')$Valor serie02 = get_sidra(api= '/t/1419/n1/all/v/63/p/all/c315/7173/d/v63%202')$Valor serie03 = get_sidra(api='/t/7060/n1/all/v/63/p/all/c315/7173/d/v63%202')$Valor
Uma vez que os dados foram coletados, nós podemos criar um tibble colocando todas as séries juntas, adicionando um vetor de datas para poder gerar os gráficos e também uma nova série com a variação acumulada em 12 meses.
dates = seq(as.Date('2006-07-01'), as.Date('2020-08-01'), by='1 month')
data = tibble(date = dates,
var_mensal = c(serie01, serie02, serie03),
var_12m = acum_p(var_mensal, 12))
data_long =
data %>%
gather(metrica, valor, -date)
Uma vez que os dados estejam devidamente coletados e tratados, nós podemos visualizar os mesmos em dois gráficos. Um que expressa a variação mensal do preço do arroz e outro que expressa a variação acumulada em 12 meses.
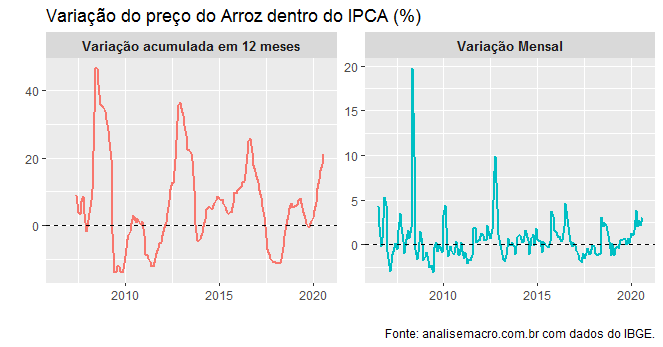
Estamos pegando dados desde julho de 2006 e eu não sei você, mas eu não vejo nada de anormal com o que está acontecendo atualmente...
____________________
(*) Para ter acesso aos códigos dos nossos posts, exercícios e demais conteúdos exclusivos, assine nossa lista VIP aqui.
(**) Isso e muito mais você aprende no nosso Curso de Análise de Conjuntura usando o R.

