O leitor frequente desse espaço já viu eu escrever diversas vezes sobre os dados do CAGED, o Cadastro Geral de Empregados e Desempregados do extinto Ministério do Trabalho. O dado do CAGED era muito bom para avaliar o mercado de trabalho, além de também ter um fit bem legal para ajudar na construção de modelos preditivos. A coleta dos dados agregados do CAGED, contudo, sempre foi bem ruim, a não ser, óbvio, que você tivesse alguma concentradora de dados, como a Bloomberg.
Pois bem, não é que a atual equipe econômica conseguiu piorar o que já era ruim? Desde janeiro desse ano, houve a substituição do CAGED pelo eSocial, de modo que a série de admitidos e demitidos gerada pelo CAGED está descontinuada. Em outras palavras, há uma série que termina em dezembro de 2019 e outra série que começa em janeiro de 2020.
Resolvi falar sobre isso porque é um problema recorrente no país: a descontinuidade de séries econômicas. Países como os Estados Unidos, por exemplo, têm séries econômicas longas, que às vezes chegam a mais de 100 anos de dados. Um verdadeiro parque de diversões para quem trabalha com dados e, principalmente, para a geração de pesquisas.
Para além dessa descontinuidade, uma outra crítica é a disponibilidade de dados. Há um site chamado de Programa de Disseminação das Estatísticas de Trabalho, onde há a disponibilidade de planilhas de Excel, bem toscas diga-se, para quem trabalha com programas estatísticos ou com linguagens de programação, como é o meu caso. É preciso perder um tempo para tratar os dados dessas planilhas, que são individuais, uma planilha para cada mês!
A não ser que você tenha um terminal Bloomberg - né, ministro? - sua vida ficou bem difícil, se o objetivo é tratar os dados do CAGED, tá ok?
Bom, feita as críticas e cumprindo a missão desse espaço, mostro como pegar os dados agregados do Novo Caged a partir do IPEADATA, um site bem desatualizado para o mundo de hoje, mas que conta com um pacote de R para a importação de dados, o pacote ecoseries. A seguir, carregamos os pacotes e importamos os dados.
################################################
######## Análise do CAGED com o R ##############
library(ecoseries)
library(tidyverse)
library(scales)
library(seasonal)
#### Coleta de Dados via IPEADATA ####
## Baixar dados do CAGED
saldo_caged = series_ipeadata("272844966", periodicity = 'M')$serie_272844966
admitidos_caged = series_ipeadata("231410417", periodicity = 'M')$serie_231410417
demitidos_caged = series_ipeadata("231410418", periodicity = 'M')$serie_231410418
## Baixar dados do Novo Caged
saldo_novocaged = series_ipeadata("2096725336", periodicity = 'M')$serie_2096725336
admitidos_novocaged = series_ipeadata("2096725334", periodicity = 'M')$serie_2096725334
demitidos_novocaged = series_ipeadata("2096725335", periodicity = 'M')$serie_2096725335
Como é possível observar, estou pegando tanto os dados do CAGED quanto do tal Novo CAGED. É o início do script desse tema que ensino no nosso Curso de Análise de Conjuntura usando o R. Com base no novo CAGED, podemos gerar o gráfico abaixo.
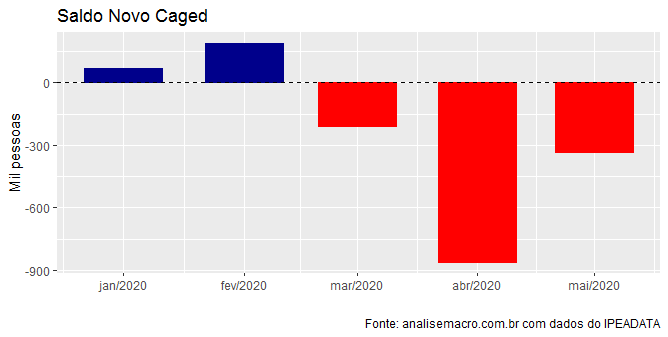
Nos meses de março, abril e maio houve uma perda líquida de quase 1,4 milhões de empregos! É uma crise com poucos precedentes na História brasileira. Digo isso no achismo, obviamente, porque não existem séries econômicas longas no país, lembra?
Bom, fica aqui então o desabafo de alguém que gostava muito dos dados do CAGED. Agora, é tentar compatibilizar as duas séries...
ps: custava ao menos criar uma API, Ministro? 🙁
____________________
(*) Você aprende a coletar, tratar, analisar e apresentar dados com o R em nossos Cursos Aplicados de R.
(**) Os alunos do plano premium dos nossos Cursos Aplicados de R têm acesso a mais de 70 exercícios do Clube do Código.

