O crédito direcionado, aquele que é administrado por bancos públicos e possui subsídios importantes envolvidos na sua intermediação, ainda é bastante relevante no mercado de crédito brasileiro. Para ilustrar, como ensinamos em nosso Curso de Análise de Conjuntura usando o R, vamos coletar os dados referentes a crédito diretamente do Banco Central com o R.
Para isso, nós utilizamos o pacote rbcb, como abaixo.
library(rbcb)
library(tidyverse)
library(zoo)
library(scales)
series = list('livres'= 20542,
'direcionado' = 20593)
data = get_series(series) %>%
reduce(inner_join) %>%
mutate(total = livres + direcionado,
'Crédito Livre' = livres/total*100,
'Crédito Direcionado' = direcionado/total*100) %>%
select(date, 'Crédito Livre', 'Crédito Direcionado') %>%
gather(variavel, valor, -date)
No código acima, nós estamos basicamente pegando os dados do crédito livre, aquele que é intermediado sem subsídios e o crédito direcionado que falamos acima. A partir das séries coletadas, nós podemos criar as taxas de crédito livre e de crédito direcionado a partir do estoque total de crédito. Com efeito, podemos gerar o gráfico abaixo.
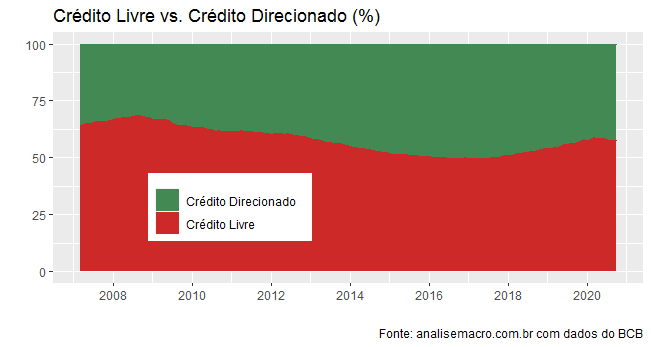
A despeito da mudança na estrutura da taxa de juros que regula os empréstimos do BNDES, parte importante do estoque de crédito direcionado, o mesmo ainda responde por mais de 40% do total de crédito no Brasil.
__________________


