Toda segunda-feira, o Banco Central publica um boletim que resume as expectativas de mais de 100 instituições sobre o futuro de variáveis macroeconômicas como o PIB, a taxa de câmbio, a inflação e a taxa de juros. O boletim Focus conta, inclusive, com um script de R no nosso Curso de Análise de Conjuntura usando o R. A seguir, ilustro o início do script.
 Para coletar os dados de expectativas do Focus, eu utilizo o pacote rbcb, que está disponível no github. Para fazer o tratamento dos dados, utilizamos os pacotes tidyverse. Para ilustrar, vamos pegar os dados esperados para o crescimento do PIB.
Para coletar os dados de expectativas do Focus, eu utilizo o pacote rbcb, que está disponível no github. Para fazer o tratamento dos dados, utilizamos os pacotes tidyverse. Para ilustrar, vamos pegar os dados esperados para o crescimento do PIB.
library(rbcb)
library(tidyverse)
pibe = get_annual_market_expectations('PIB Total',
start_date = '2015-01-01')
O código acima retorna um tibble com os dados de crescimento médio e mediano esperados para vários anos, bem como outras métricas como o desvio padrão das previsões. A seguir, nós plotamos o crescimento médio e mediano esperados para 2020, a partir do início de 2019.
img <- readPNG('logo.png')
g <- rasterGrob(img, interpolate=TRUE)
filter(pibe, reference_year == '2020' & date > '2019-01-02') %>%
ggplot(aes(x=date))+
geom_line(aes(y=mean, colour='Média'), size=.8)+
geom_line(aes(y=median, colour='Mediana'), size=.8)+
scale_colour_manual('', values=c('Média'='darkblue',
'Mediana'='red'))+
geom_hline(yintercept=0, colour='black', linetype='dashed')+
labs(title='Crescimento Esperado para 2020',
subtitle='Boletim Focus: média e mediana das instituições',
caption='Fonte: analisemacro.com.br com dados do BCB.')+
xlab('')+ylab('% a.a.')+
scale_x_date(breaks = date_breaks("14 days"),
labels = date_format("%d/%b"))+
theme(axis.text.x=element_text(angle=45, hjust=1))+
theme(panel.background = element_rect(fill='#acc8d4',
colour='#acc8d4'),
plot.background = element_rect(fill='#8abbd0'),
axis.line = element_line(colour='black',
linetype = 'dashed'),
axis.line.x.bottom = element_line(colour='black'),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
legend.position = c(.5,.3),
legend.background = element_rect((fill='#acc8d4')),
legend.key = element_rect(fill='#acc8d4',
colour='#acc8d4'),
plot.margin=margin(5,5,15,5))+
annotation_custom(g,
xmin=as.Date('2019-01-03'),
xmax=as.Date('2019-05-30'),
ymin=-3, ymax=-1)
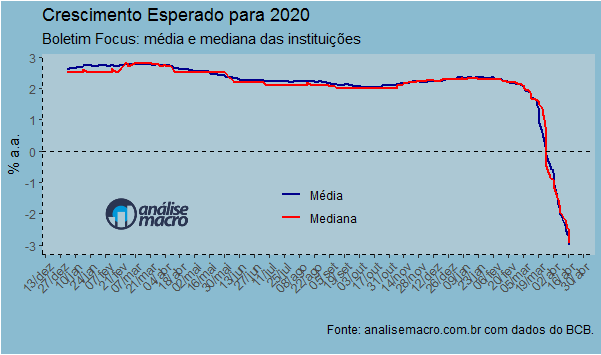
Observa-se uma queda pronunciada nas expectativas de crescimento para 2020 a partir de março, refletindo o recrudescimento da pandemia do coronavírus. No último dado disponível, o crescimento médio esperado é de -3,01% e o mediano de -2,96%. Essas previsões, contudo, estão cercadas de grande incerteza, como pode ser visto no desvio padrão abaixo.
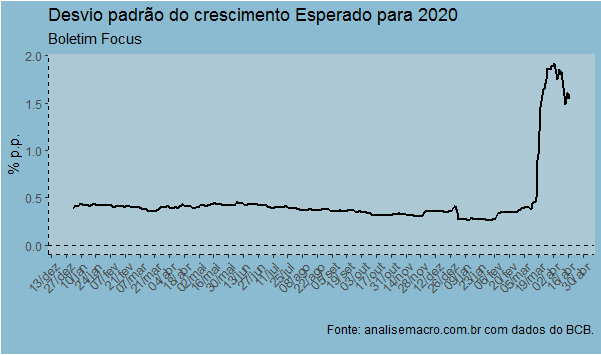
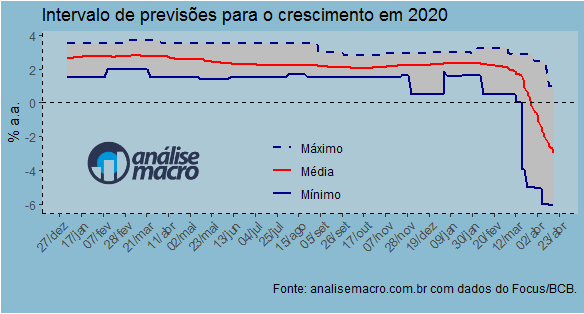
Na ponta, o desvio padrão tem diminuído, por conta de um início de convergência nas previsões. O intervalo de projeções, contudo, continua bastante amplo, com previsões mínimas chegando a -6%. O gráfico a seguir ilustra.
(*) Isso e muito mais você aprende em nosso Curso de Análise de Conjuntura usando o R.
___________

