O índice de Gini é uma medida de distribuição de renda muito interessante e conhecida, que tenta expressar em um valor único a desigualdade apresentada na curva de Lorenz. Neste exercício mostramos como podemos estimar essa medida facilmente no R.
O índice de Gini consiste em um número entre 0 e 1, onde 0 corresponde à completa igualdade e 1 corresponde à completa desigualdade e pode ser calculado com a fórmula de Brown abaixo:
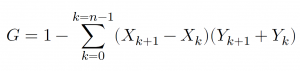
Onde:
G = coeficiente de Gini
X = proporção acumulada da variável "população"
Y = proporção acumulada da variável "renda"
Para esse exercício usaremos os microdados da PNAD Contínua trimestral do IBGE, que possui a variável Rendimento mensal efetivo de todos os trabalhos (VD4020). E para tornar o exercício interessante faremos a estimação do índice de Gini por estado (UF) brasileiro.
Pacotes
Para a finalidade do exercício utilizaremos os seguintes pacotes do R, todos disponibilizados no CRAN:
# Instalar/carregar pacotes
if(!require("pacman")) install.packages("pacman")
pacman::p_load(
"PNADcIBGE",
"survey",
"convey",
"tidyverse"
)
Dados
O último trimestre da pesquisa disponível na data deste exercício é referente ao 1º trimestre de 2021. Apontamos esse período na função get_pnadc(), especificamos as variáveis desejadas para coleta e convertemos o objeto resultante para a classe convey para poder fazer a estimação:
pnadc_0121 <- PNADcIBGE::get_pnadc(year = 2021, quarter = 1, vars = c("UF", "VD4020")) %>%
convey::convey_prep()
Estimar índice de Gini
Para estimar o índice de Gini o pacote convey oferece a função svygini, bastando especificar a variável de renda desejada. Como queremos a estimação por estado, usaremos também a função svyby do pacote survey, que serve justamente para calcularmos estatísticas por grupos dos nossos dados, nesse caso a UF.
gini_uf <- survey::svyby( ~VD4020, by = ~UF, design = pnadc_0121, FUN = convey::svygini, na.rm = TRUE )
Visualizar os resultados
Por fim, vamos fazer um gráfico simples para visualizar o resultado da estimação, usando o ggplot2:
gini_uf %>% dplyr::as_tibble() %>% dplyr::mutate(UF = forcats::fct_reorder(UF, VD4020)) %>% ggplot2::ggplot(ggplot2::aes(x = VD4020, y = UF)) + ggplot2::geom_col(fill = "darkblue") + ggplot2::theme_classic() + ggplot2::labs( title = "Índice de Gini por Estado", subtitle = "Dados do 1º trimestre de 2021", x = NULL, y = NULL, caption = "Fonte: Microdados PNADC-T/IBGE" )
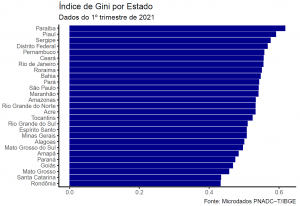 O que você achou do resultado? Surpreendente? Deixe suas impressões!
O que você achou do resultado? Surpreendente? Deixe suas impressões!
Quer aprender mais sobre utilização de microdados? Inscreva-se no curso de R e Python para Economistas.

________________________
(*) Para entender mais sobre micro dados e desigualdade, confira nosso Cursos de Micro Aplicada.

