No último dia 29 de janeiro, o Banco Central divulgou as Estatísticas Fiscais referentes à dezembro de 2020. Com efeito, ficamos sabendo como se comportaram as principais variáveis fiscais ao longo de 2020, um ano repleto de desafios por conta da pandemia do coronavírus. Nesse Comentário Semanal do boletim Focus, nós trazemos uma edição especial focada em variáveis fiscais.
Para começar, como de praxe, nós carregamos os pacotes que utilizamos.
library(rbcb) library(scales) library(tidyverse)
A seguir, nós buscamos dois grupos de dados. Para começar, nós pegamos os dados referentes às variáveis efetivamente observadas. O código a seguir pega os dados diretamente do Sistema de Séries Temporais do Banco Central.
## Coleta de dados reais
series = list('DBGG' = 13762,
'DLSP' = 4513,
'NFSP Primário' = 5793,
'NFSP Nominal' = 5727)
data_variaveis = get_series(series, start_date = '2019-01-01') %>%
purrr::reduce(inner_join) %>%
gather(variavel, valor, -date)
A seguir, nós pegamos os dados referentes às expectativas contidas para essas variáveis dentro do boletim Focus.
## Coleta de dados de expectativas
data_expectativas = get_annual_market_expectations('Fiscal',
start_date = '2019-01-01')
data_expectativas$indic_detail = ifelse(data_expectativas$indic_detail == "Resultado Primário",
'Resultado Primário',
data_expectativas$indic_detail)
data_expectativas$indic_detail = ifelse(data_expectativas$indic_detail ==
unique(data_expectativas$indic_detail)[3],
'DLSP',
data_expectativas$indic_detail)
data_expectativas$indic_detail = ifelse(data_expectativas$indic_detail ==
unique(data_expectativas$indic_detail)[4],
'DBGG',
data_expectativas$indic_detail)
De posse dos dados, nós podemos olhar o que ocorreu com as variáveis observadas.
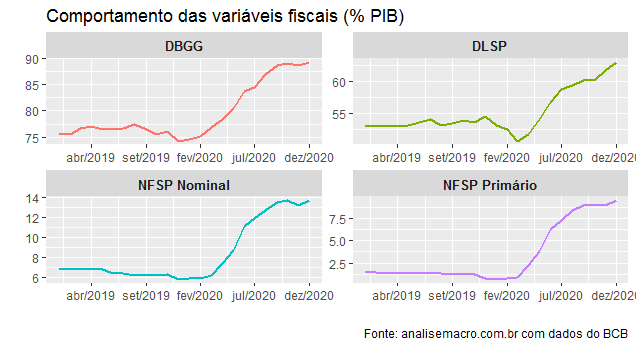
O ano de 2020 terminou com a Dívida Bruta muito próxima dos 90% do PIB (89,3%) e com a Dívida Líquida em 63%. Em dezembro de 2019, a DBGG estava em 74,3%, enquanto a DLSP estava em 54,6% do PIB. Isto é, houve um aumento de 15 pontos percentuais na DBGG ao longo de 2020.
A deterioração do fluxo explica a maior parte dessa evolução. As Necessidades de Financiamento do Setor Público (NFSP) saíram de 0,84% em dezembro de 2019 para 9,49% do PIB em dezembro de 2020, no seu corte primário, que não inclui gastos com juros. No seu corte nominal, que inclui gastos financeiros, houve uma variação de 7,91 pontos percentuais: de 5,79% para 13,7% do PIB.
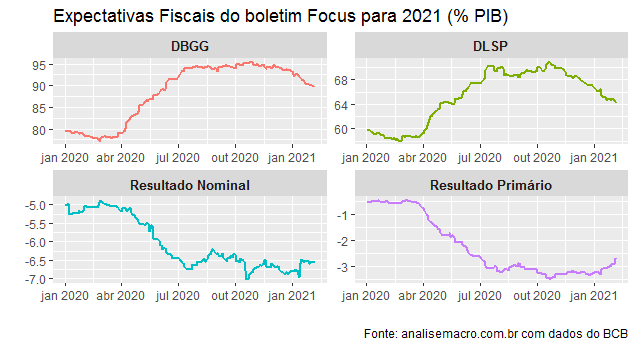
Ao longo de 2021, diga-se, os agentes de mercado esperam uma certa estabilidade nas variáveis de estoque, enquanto para o fluxo, o resultado nominal esperado está em -6,59% do PIB e o primário em -2,72%.
____________________
(*) No nosso Curso de Análise de Conjuntura usando o R, nós estressamos a coleta e tratamento de dados fiscais com o R;
(**) O código de R desse artigo está disponível para os membros do novo Clube AM. Para saber mais, clique aqui.


