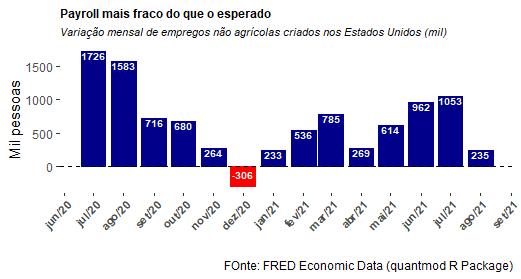
Na sexta-feira, o U.S. Bureau of Labor Statistics divulgou o dado do nonfarm payroll, ou seja, a quantidade de postos de trabalho não agrícolas criadas/destruídas ao longo do mês. O resultado para agosto foi de uma criação de 235 mil postos de trabalho. O dado veio bem abaixo do esperado.
Para visualizar os dados do payroll no R, podemos usar o pacote quantmod como no código abaixo.
library(quantmod)
library(ggplot2)
library(gridExtra)
library(dplyr)
library(magrittr)
library(scales)
library(timetk)
getSymbols('PAYEMS', src='FRED')
data = tk_tbl(PAYEMS, preserve_index = TRUE, rename_index = 'date') %>%
rename(payroll=PAYEMS) %>%
mutate(variacao = payroll - lag(payroll,1))
subdata = filter(data, date > '2020-06-01')
ggplot(subdata, aes(x=date, y=variacao))+
geom_bar(stat='identity', colour=ifelse(subdata$variacao>0, 'darkblue', 'red'),
fill=ifelse(subdata$variacao>0, 'darkblue', 'red'))+
geom_text(aes(label=round(variacao,2),
vjust = ifelse(variacao > 0, 1, -1)), size=2.6,
hjust=0.5, colour="white", fontface='bold')+
geom_hline(yintercept=0, colour='black', linetype='dashed')+
scale_x_date(breaks = date_breaks("1 month"),
labels = date_format("%b/%y"))+
theme(axis.text.x=element_text(angle=45, hjust=1),
plot.title = element_text(size=9, face='bold'),
plot.subtitle = element_text(size=8, face='italic'),
panel.background = element_rect(colour='white', fill='white'),
axis.text.x.bottom = element_text(size=8, face='bold'))+
labs(x='', y='Mil pessoas',
title='Payroll mais fraco do que o esperado',
subtitle='Variação mensal de empregos não agrícolas criados nos Estados Unidos (mil)',
caption='FOnte: FRED Economic Data (quantmod R Package)')
______________________
(*) Aprenda a coletar e tratar dados macroeconômicos com o nosso Curso de Análise de Conjuntura usando o R.

