A política fiscal refere-se na forma que o governo faz uso dos gastos e das receitas. Sua condução afeta diversas variáveis econômicas, portanto, seu acompanhamento é necessário, como forma de antever os rumos da economia. É possível acessar facilmente os dados fiscais do Brasil através do Banco Central com diversos pacotes no R. Nós ensinamos como realizar não só a coleta no R, mas também o tratamento e a visualização dos dados no nosso Curso de Análise de Conjuntura.
No Relatório AM dessa semana, ensinaremos como realizar a coleta através do pacote {GetBCBData}. Também utilizaremos dados do IPCA para deflacionar os valores e do PIB para compararmos com os gastos com juros.
Carregamos os pacotes necessários.
# Carregar pacotes
if (!require("pacman")) install.packages("pacman")
pacman::p_load(
"GetBCBData",
"sidrar",
"magrittr",
"dplyr",
"lubridate",
"purrr",
"timetk",
"tidyr",
"stringr",
"ggplot2",
"ggthemes",
"flextable"
)
Definimos objetos para facilitar a criação do código.
## Funções e objetos úteis
# Cores para gráficos e tabelas
colors <- c(
blue = "#282f6b",
red = "#b22200",
yellow = "#eace3f",
green = "#224f20",
purple = "#5f487c",
orange = "#b35c1e",
turquoise = "#419391",
green_two = "#839c56",
light_blue = "#3b89bc",
gray = "#666666"
)
# Fonte para gráficos e tabelas
foot_bcb <- "Fonte: analisemacro.com.br com dados do BCB."
# Definir padrão de gráficos
theme_am <- function() {
ggthemes::theme_clean() %+replace%
ggplot2::theme(
plot.background = ggplot2::element_rect(colour = NA),
legend.background = ggplot2::element_rect(colour = NA),
strip.text = ggplot2::element_text(size = 8, face = "bold")
)
}
ggplot2::theme_set(theme_am())
Coletamos os dados através do pacote {GetBCBData}. Primeiro devemos buscar os códigos das variáveis através do Sistema Gerenciador de Séries do Banco Central. Cada código refere-se a um conjunto de dados. Salvamos esses valores em um objeto. Para o IPCA, utilizaremos o pacote {sidrar} para buscar valores do SIDRA.
Após isso, seguimos para a importação dos dados, do tratamento e após para a visualização.
## Parâmetros e códigos para coleta de dados
parametros <- list(
## Resultado do Setor Público Consolidado
# NFSP sem desvalorização cambial
# Fluxo mensal corrente - Total - R$ (milhões)
resultado_spc = c(
"Resultado primário - INSS" = 7854,
"Resultado primário - Governo Federal" = 7853,
"Resultado primário - Governos Estaduais" = 4643,
"Resultado primário - Governos Municipais" = 4644,
"Resultado primário - Empresas Estatais" = 4645,
"Resultado primário - Setor Público Consolidado" = 4649,
"Juros nominais - Governo Federal" = 4607,
"Juros nominais - Banco Central" = 4608,
"Juros nominais - Governos Estaduais" = 4610,
"Juros nominais - Governos Municipais" = 4611,
"Juros nominais - Empresas Estatais" = 4612,
"Juros nominais - Setor Público Consolidado" = 4616,
"Resultado nominal - Setor Público Consolidado" = 4583
),
# PIB acumulado dos últimos 12 meses - Valores correntes (R$ milhões)
pib = c("PIB 12 meses" = 4382),
# IPCA - Número-índice (base: dezembro de 1993 = 100)
ipca = "/t/1737/n1/all/v/2266/p/all/d/v2266%2013"
)
</pre> ## Coleta dos dados # IPCA para deflacionar valores raw_ipca <- sidrar::get_sidra(api = parametros$ipca) # PIB para cálculos em "% PIB raw_pib <- GetBCBData::gbcbd_get_series( id = parametros$pib, first.date = "2001-12-01", use.memoise = FALSE ) # Resultado do Setor Público Consolidado raw_resultado_spc <- GetBCBData::gbcbd_get_series( id = parametros$resultado_spc, first.date = "2001-12-01", use.memoise = FALSE ) <pre>
</pre>
## Tratamento dos dados
# IPCA
ipca <- raw_ipca %>%
dplyr::select("date" = `Mês (Código)`, "ipca" = `Valor`) %>%
dplyr::mutate(date = lubridate::ym(date))
# PIB
pib <- raw_pib %>%
dplyr::select("date" = `ref.date`, "pib" = `value`)
# Resultado do Setor Público Consolidado
resultado_spc <- raw_resultado_spc %>%
dplyr::select("date" = `ref.date`, "variable" = `series.name`, "nominal" = value) %>%
purrr::reduce(
.x = list(., ipca, pib),
.f = dplyr::left_join,
by = "date"
) %>%
dplyr::as_tibble() %>%
dplyr::group_by(variable) %>%
dplyr::mutate(
# Deflacionar valores
real = (ipca[date == max(date)] / ipca) * nominal,
# Acumular valores nominais em 12 meses (% PIB)
nominal_acum_12m_pib = timetk::slidify_vec(
.x = nominal,
.f = sum,
.period = 12,
.align = "right"
) / pib * 100,
# Acumular valores reais em 12 meses
real_acum_12m = timetk::slidify_vec(
.x = real,
.f = sum,
.period = 12,
.align = "right"
)
) %>%
tidyr::drop_na() %>%
dplyr::ungroup()
<pre>
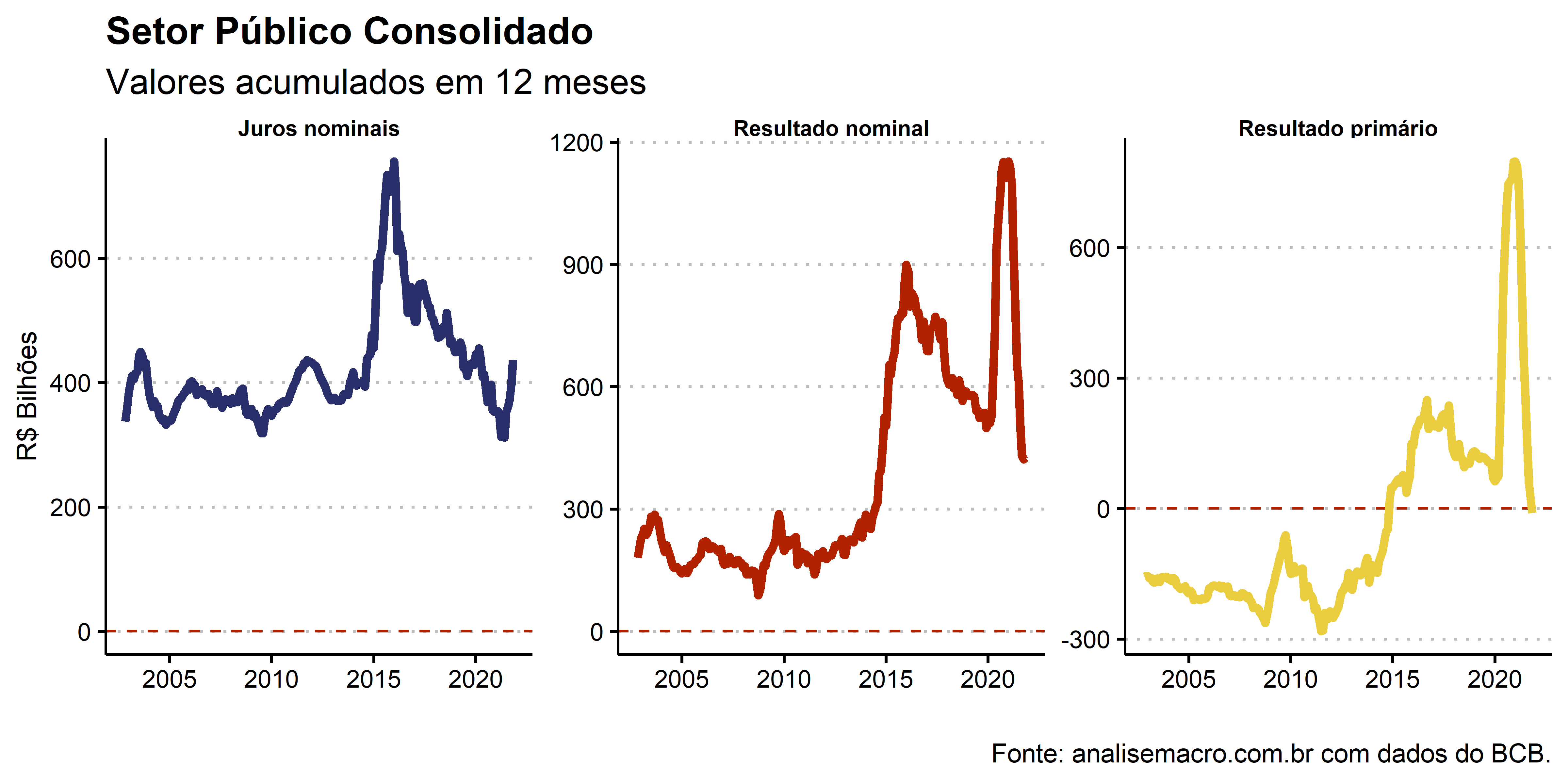
Criamos um gráfico da variação acumulada em 12 meses dos Juros Nominais, Resultado Nominal e Resultado Primário.
# Setor Público Consolidado (Res. Primário, Juros e Res. Nominal) resultado_spc %>% dplyr::filter(stringr::str_detect(variable, "Setor Público Consolidado")) %>% dplyr::mutate(variable = stringr::str_remove_all(variable, " - Setor Público Consolidado")) %>% ggplot2::ggplot(ggplot2::aes(x = date, y = real_acum_12m / 1000, color = variable)) + ggplot2::geom_hline(yintercept = 0, color = colors["red"], linetype = "dashed") + ggplot2::geom_line(size = 1.5) + ggplot2::facet_wrap(~variable, scales = "free_y") + ggplot2::scale_color_manual(NULL, values = unname(colors[1:6])) + ggplot2::labs( title = "Setor Público Consolidado", subtitle = "Valores acumulados em 12 meses", y = "R$ Bilhões", x = "", caption = foot_bcb ) + ggplot2::theme(legend.position = "none")
Visualizamos os gastos com juros em razão do PIB.
# Gastos com juros - % PIB acumulado em 12 meses resultado_spc %>% dplyr::filter(stringr::str_detect(variable, "Juros nominais - ")) %>% dplyr::mutate(variable = stringr::str_remove_all(variable, "Juros nominais - ")) %>% ggplot2::ggplot(ggplot2::aes(x = date, y = nominal_acum_12m_pib, color = variable)) + ggplot2::geom_hline(yintercept = 0, color = colors["red"], linetype = "dashed") + ggplot2::geom_line(size = 1.5) + ggplot2::facet_wrap(~variable, scales = "free_y") + ggplot2::scale_color_manual(NULL, values = unname(colors[1:6])) + ggplot2::labs( title = "Gastos com juros", subtitle = "Valores acumulados em 12 meses, % do PIB", y = "% do PIB", x = "", caption = foot_bcb ) + ggplot2::theme(legend.position = "none")

______________________________________
Você confere o script completo no nosso Curso de Análise de Conjuntura usando o R. A apresentação da PMC também está disponível no Clube AM.
______________________________________


