O Produto Interno Bruto é o principal indicador para acompanhamento do nível de atividade no Brasil, medindo a soma final de todos os bens e serviços produzidos no país. Os dados do PIB podem ser acessados através do SIDRA, sendo importados facilmente no R através do pacote {sidrar}. No Relatório AM de hoje, trazemos uma parte do código que ensinamos no Curso de Análise de Conjuntura de como automatizar o processo de coleta, tratamento e visualização dos dados do PIB.
library(tidyverse) library(sidrar) library(flextable)
## Funções e objetos úteis
# Acumular valores percentuais em 'n' janelas móveis
acum_i <- function(data, n){
data_ma_n <- RcppRoll::roll_meanr(data, n)
data_lag_n <- dplyr::lag(data_ma_n, n)
data_acum_n = (((data_ma_n/data_lag_n)-1)*100)
return(data_acum_n)
}
# Cores para gráficos e tabelas
colors <- c(
blue = "#282f6b",
red = "#b22200",
yellow = "#eace3f",
green = "#224f20",
purple = "#5f487c",
orange = "#b35c1e",
turquoise = "#419391",
green_two = "#839c56",
light_blue = "#3b89bc",
gray = "#666666"
)
# Fonte para gráficos e tabelas
foot_ibge <- "Fonte: analisemacro.com.br com dados do Sidra/IBGE."
# Definir padrão de tabelas
flextable::set_flextable_defaults(
big.mark = " ",
font.size = 10,
theme_fun = theme_vanilla,
padding.bottom = 6,
padding.top = 6,
padding.left = 6,
padding.right = 6,
decimal.mark = ",",
digits = 2L
)
Definimos a chave do API que coletaremos através do {sidrar}.
## Parâmetros e códigos para coleta de dados parametros <- list( # PIB com ajuste sazonal api_pib_sa = "/t/1621/n1/all/v/all/p/all/c11255/90707/d/v584%202", # PIB sem ajuste api_pib = "/t/1620/n1/all/v/all/p/all/c11255/90707/d/v583%202" )
Retiramos os dados com a função get_sidra do pacote {sidrar}.
## Coleta dos dados # PIB com ajuste sazonal raw_pib_sa <- sidrar::get_sidra(api = parametros$api_pib_sa) # PIB sem ajuste raw_pib <- sidrar::get_sidra(api = parametros$api_pib)
Tratamos os dados, realizando a limpeza e o cálculo das variações do índice do PIB.
## Tratamento dos dados # PIB com ajuste sazonal pib_sa <- raw_pib_sa %>% dplyr::mutate( date = zoo::as.yearqtr(`Trimestre (Código)`, format = "%Y%q"), var_marginal = (Valor / dplyr::lag(Valor, 1) - 1) * 100 ) %>% dplyr::select(date, "pib_sa" = Valor, var_marginal) %>% dplyr::as_tibble() # PIB sem ajuste pib <- raw_pib %>% dplyr::mutate( date = zoo::as.yearqtr(`Trimestre (Código)`, format = "%Y%q"), var_interanual = (Valor / dplyr::lag(Valor, 4) - 1) * 100, var_anual = acum_i(Valor, 4) ) %>% dplyr::select(date, "pib" = Valor, var_interanual, var_anual) %>% dplyr::as_tibble() # Juntar os dados do PIB df_pib <- dplyr::inner_join(pib_sa, pib, by = "date") %>% tidyr::drop_na() %>% dplyr::filter(date >= "2007 Q1")
Índice do PIB
Vemos que é possível visualizar através do pacote ggplo2 o índice do PIB ao longo do tempo, comparando o PIB sem e com ajuste sazonal.
# Gerar gráfico
df_pib %>%
dplyr::filter(date > "2000 Q1") %>%
ggplot2::ggplot(ggplot2::aes(x = date)) +
ggplot2::geom_line(ggplot2::aes(y = pib, color = "PIB"), size = 0.8) +
ggplot2::geom_line(ggplot2::aes(y = pib_sa, color = "PIB s.a."), size = 0.8) +
ggplot2::scale_color_manual(
NULL,
values = c("PIB" = unname(colors[1]), "PIB s.a." = unname(colors[2]))
) +
zoo::scale_x_yearqtr(
breaks = scales::pretty_breaks(n = 8),
format = "%Y T%q"
) +
ggplot2::theme(
plot.title = ggplot2::element_text(size = 12, face = "bold"),
legend.position = "bottom"
) +
ggplot2::labs(
x = NULL,
y = "Número Índice",
title = "Produto Interno Bruto",
caption = foot_ibge
)
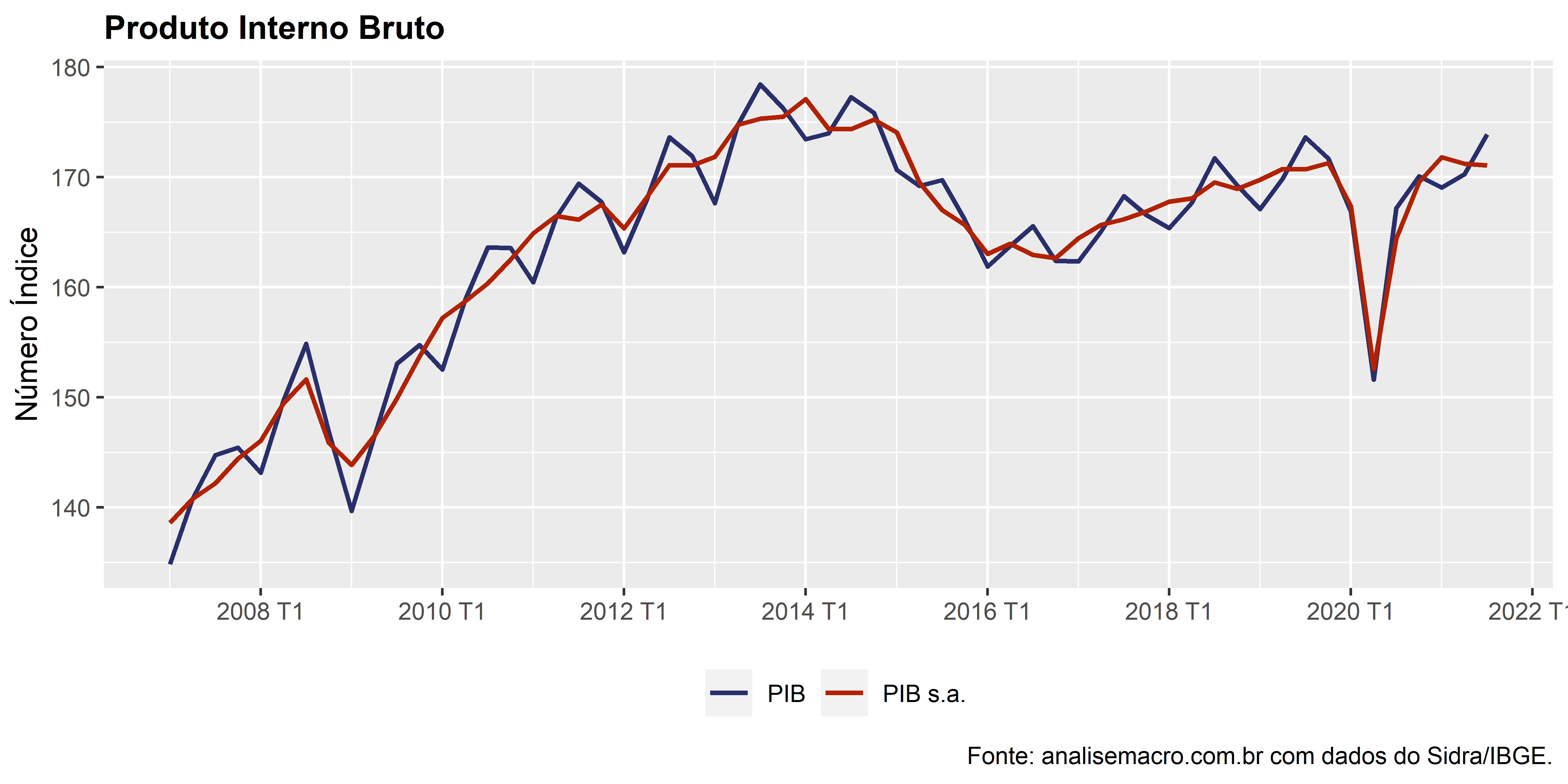 Variações do PIB
Variações do PIB
Realizamos o calculo das variações marginais, interanuais e anuais do PIB, através do índice, dentro do R e podemos visualizar através da construção de um tabela.
# Filtrar últimos 8 trimestres
df_pib_tbl <- df_pib %>%
dplyr::slice_tail(n = 8) %>%
dplyr::select(var_marginal, var_interanual, var_anual)
# Tabela com variações e número índice do PIB
df_pib %>%
dplyr::slice_tail(n = 8) %>%
flextable::flextable() %>%
flextable::set_header_labels(
date = "Trimestre", pib_sa = "PIB s.a.", var_marginal = "Var. Marginal", pib = "PIB",
var_interanual = "Var. Interanual", var_anual = "Var. Anual"
) %>%
flextable::add_header_row(
colwidths = c(3, 3),
values = c("Sazonalmente ajustado", "Sem ajuste sazonal")
) %>%
flextable::colformat_double(j = 2:6, digits = 2) %>%
flextable::align(i = 1, part = "header", align = "center") %>%
flextable::add_footer_lines(foot_ibge) %>%
flextable::color(part = "footer", color = colors["gray"]) %>%
flextable::bg(
j = c("var_marginal", "var_interanual", "var_anual"),
bg = scales::col_numeric(
palette = colorspace::diverge_hcl(n = 20, palette = "Blue-Red 2"),
reverse = TRUE,
domain = c(-max(abs(df_pib_tbl)), max(abs(df_pib_tbl)))
),
part = "body"
) %>%
flextable::theme_vanilla() %>%
flextable::width(width = .95)

____________________
Quer conferir o código completo e aprender a como criar uma análise do PIB utilizando o R? Veja nosso Curso de Análise de Conjuntura.
____________________


