As semanas de agosto têm sido intensas, leitor, motivo pelo qual não tenho tido tempo de postar nada de  por aqui. Hoje, entretanto, eu não posso deixar de responder a um amigo sobre um problema que deixa confuso muito estudante e professor de economia. As pessoas, muitas vezes, acham que o crescimento é liderado pelo consumo, pelo crédito, por isso ou por aquilo. A intuição presente no princípio da demanda efetiva é forte ao ponto de entorpecer corações e mentes. Falta crescimento? Culpa da confiança de empresários e consumidores. E, claro, de banqueiros, que não querem emprestar. Estão sentados no dinheiro alheio, ganhando mais dinheiro com aplicações financeiras. Nessa linha, inclusive, que deve pensar a atual presidente da Caixa Econômica, Miriam Belchior, dada a recente decisão daquela instituição, sobre concessão de crédito para o setor automotivo - o mesmo setor que já recebeu rios de dinheiro e incentivo fiscal nesse país. A minha pergunta, digo a desculpa para usar o , é será que existe causalidade bem definida entre crédito e PIB?
por aqui. Hoje, entretanto, eu não posso deixar de responder a um amigo sobre um problema que deixa confuso muito estudante e professor de economia. As pessoas, muitas vezes, acham que o crescimento é liderado pelo consumo, pelo crédito, por isso ou por aquilo. A intuição presente no princípio da demanda efetiva é forte ao ponto de entorpecer corações e mentes. Falta crescimento? Culpa da confiança de empresários e consumidores. E, claro, de banqueiros, que não querem emprestar. Estão sentados no dinheiro alheio, ganhando mais dinheiro com aplicações financeiras. Nessa linha, inclusive, que deve pensar a atual presidente da Caixa Econômica, Miriam Belchior, dada a recente decisão daquela instituição, sobre concessão de crédito para o setor automotivo - o mesmo setor que já recebeu rios de dinheiro e incentivo fiscal nesse país. A minha pergunta, digo a desculpa para usar o , é será que existe causalidade bem definida entre crédito e PIB?
Com a palavra, os dados...
Não vou usar teoria aqui, nem irei rebuscar muito a resposta, porque meu amigo não é economista, apesar de saber mais economia do que muita gente boa por aí. Vamos aos dados, direto - dúvidas e questões mais teóricas, nos comentários, por favor. Para efeito de transparência, eu estou usando as séries 2007, 2043 e 4382 do Banco Central do Brasil, respectivamente, estoque de crédito sob controle de bancos públicos, estoque de crédito sob controle de bancos privados e uma medida de PIB mensal.
Bom, você já percebeu que estou usando uma diferenciação entre crédito público e privado. Não é por querer, viu, é que o Banco Central não tem uma série de estoque de crédito total longa, logo para gerar uma, desde julho de 1994 - quando o Brasil começou a virar um país sério - eu preciso somar essas duas. No , eu faço isso com o código abaixo.
### Importação de dados data <- ts(read.csv(file='credito.csv',header=T,sep=";",dec=","), start=c(1994,07), freq=12) head(data) data <- data[,-1] #### Crédito Total credtot <- data[,1]+data[,2]
Construída a série de crédito total, vamos aos gráficos. Recordando, já que faz tempo que não uso essa função por aqui, gráfico é sempre mais rápido com a função gtsplot, do pacote BMR. Esqueceu? Não tem problema, basta carregar o pacote BMR - em caso de dúvida, dá uma olhada aqui - e seguir o código abaixo.
################################################################
################# Gráfico Crédito Total e PIB ##################
dados <- cbind(data[,3], credtot)
colnames(dados) <- c('PIB', 'Crédito Total')
dates <- seq(as.Date('1994-07-01'), as.Date('2015-04-01'), by='1 month')
gtsplot(dados, dates=dates)
E os gráficos...
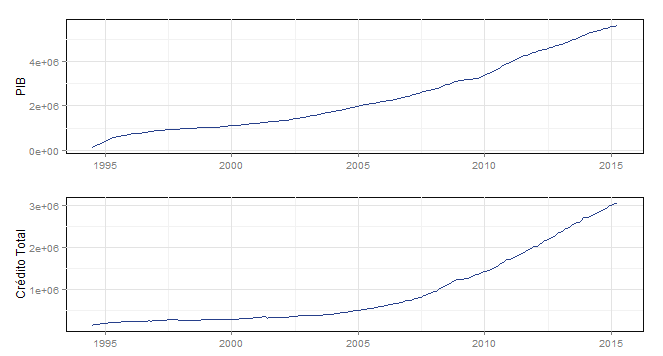
Economista sério olha para esses gráficos e já vê problemas, certo? Sim, as séries não são estacionárias, o que é um problema para o teste de causalidade que iremos fazer a seguir. Diferencie imediatamente, então, com a função diff. Os gráficos dessas séries são postos abaixo.
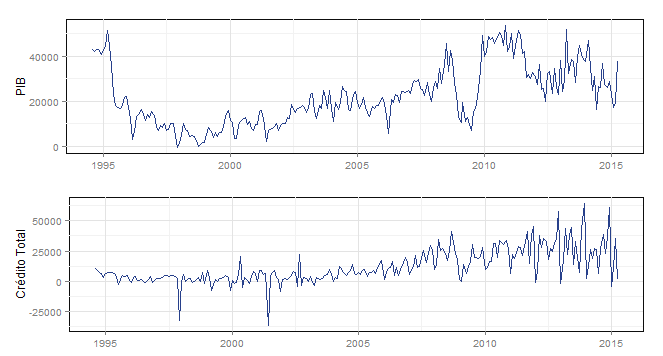
Melhor, não é mesmo? Para confirmar a estacionariedade, você deve fazer um teste, algo que não irei fazer, dada a pressa - fica como exercício. Dúvida sobre isso, aqui. E, por fim, um teste de causalidade de Granger entre PIB e Crédito Total. Eu coloquei no código abaixo 12 como ordem de defasagem, dado o resultado dos critérios de informação.
######################### GRANGER CAUSALITY ##########################
VARselect(dados,lag.max=12, type=c("const"),season=NULL)
grangertest(dados[,'PIB']~dados[,'Crédito Total'],
order=12, data=dados)
grangertest(dados[,'Crédito Total']~dados[,'PIB'],
order=12, data=dados)
A saída dos testes...
> granger1 Granger causality test Model 1: dados[, "PIB"] ~ Lags(dados[, "PIB"], 1:12) + Lags(dados[, "Crédito Total"], 1:12) Model 2: dados[, "PIB"] ~ Lags(dados[, "PIB"], 1:12) Res.Df Df F Pr(>F) 1 212 2 224 -12 1.3915 0.1716 > granger2 Granger causality test Model 1: dados[, "Crédito Total"] ~ Lags(dados[, "Crédito Total"], 1:12) + Lags(dados[, "PIB"], 1:12) Model 2: dados[, "Crédito Total"] ~ Lags(dados[, "Crédito Total"], 1:12) Res.Df Df F Pr(>F) 1 212 2 224 -12 2.0727 0.01993 * --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
O resultado dos testes, dada a escolha de 12 defasagens conforme a maioria dos critérios de informação, é que a hipótese de que o PIB não granger causa o Crédito Total é rejeitada, conforme o p-valor em negrito. Para o caso contrário [crédito total não granger causa o PIB] não é possível rejeitar. De acordo com o teste, a ideia de que os bancos emprestam e depois o PIB cresce não é verdadeira, até porque os bancos precisam ver a maré mudar para emprestar. Em outras palavras, os determinantes do crescimento deveriam ser buscados em outro canto, que não no crédito bancário.
Indo um pouco mais além
Mas, calma, pensa você. 12 defasagens? É sério, isso? Meio complicado pensar que a relação entre crédito e PIB precise de 12 defasagens, não é mesmo? Pensando nisso, eu rodei outro código, para ver como a relação se dá com diferentes defasagens, até chegar à 12ª. Para não ter que fazer isso 12 vezes, o nos ajuda. O código roda o teste de granger para a defasagem de 1 a 12 e salva o p-valor de cada uma deles.
######################################################################
#################### OUTRAS ORDENS DE DEFASAGEM ######################
pvalue <- matrix(NA, nrow=12, ncol=2)
colnames(pvalue) <- c('Crédito Total', 'PIB')
for(i in 1:12){
pvalue[i,1] <- grangertest(dados[,'PIB']~dados[,'Crédito Total'],
order=i, data=dados)[2,4]
pvalue[i,2] <- grangertest(dados[,'Crédito Total']~dados[,'PIB'],
order=i, data=dados)[2,4]
}
E abaixo eu coloco os p-valores. A primeira coluna é p-valor do teste Crédito Total não granger causa PIB e a segunda coluna é o p-valor do teste PIB não granger causa Crédito Total.
| Crédito Total | PIB |
| 0.0005 | 0 |
| 0.005 | 0.00000 |
| 0.023 | 0.005 |
| 0.015 | 0.008 |
| 0.049 | 0.039 |
| 0.043 | 0.119 |
| 0.051 | 0.043 |
| 0.024 | 0.059 |
| 0.031 | 0.062 |
| 0.048 | 0.074 |
| 0.125 | 0.086 |
| 0.172 | 0.020 |
Faz mais sentido agora, não é mesmo? Repare que adotando critérios de informação, nos baseamos na 12ª defasagem e fomos levados a inferir que o PIB granger causa o Crédito Total. Mas ao olhar todas as defasagens, até a 12ª, o que fica claro é que tanto o PIB granger causa o Crédito Total quanto o Crédito Total granger causa o PIB. Em outras palavras, à medida que o PIB cresce, os bancos se sentem mais confortáveis para emprestar e dado isso, o PIB cresce mais ainda. O processo, nesse caso, parece ser mais simultâneo do que unidirecional. Logo, leitor, não tem jeito, quer achar os determinantes fundamentais do crescimento? Não vá bater na porta da Miriam Belchior, porque ela não sabe... 🙁

