Na Edição 60 do Clube do Código, construímos um modelo simples que explica a trajetória do spread bancário no Brasil. O spread é a diferença entre as taxas de captação e de empréstimo bancário, que é sistematicamente mais elevado no país do que a evidência internacional. De modo a entender essa anomalia, utilizamos como variáveis explicativas para o spread as provisões dos bancos, compulsórios bancários, taxa de inadimplência, taxa Selic e taxa de desemprego. Abaixo o ajuste do modelo.
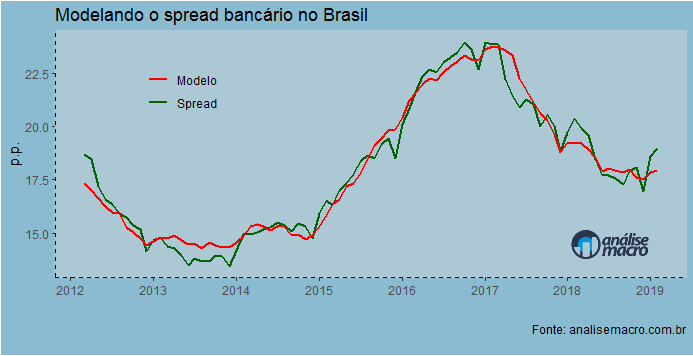 O modelo que construímos tem um R^2 de 0,96, o que significa que o mesmo consegue explicar 96% da variação na nossa variável de interesse. Abaixo, colocamos uma tabela que resume os resultados encontrados.
O modelo que construímos tem um R^2 de 0,96, o que significa que o mesmo consegue explicar 96% da variação na nossa variável de interesse. Abaixo, colocamos uma tabela que resume os resultados encontrados.
| Dependent variable: | |
| spread | |
| provisoes | 1.232** |
| (0.512) | |
| compulsorio | 0.007** |
| (0.003) | |
| inadimplencia | 1.338*** |
| (0.386) | |
| selic | 0.559*** |
| (0.030) | |
| desemprego | 0.559*** |
| (0.115) | |
| Constant | -7.509*** |
| (1.426) | |
| Observations | 84 |
| R2 | 0.962 |
| Adjusted R2 | 0.960 |
| Note: | *p<0.1; **p<0.05; ***p<0.01 |
Como se depreende da tabela, todas as variáveis foram estatisticamente significativas para explicar o spread bancário. Em particular, os resultados encontrados sugerem que um aumento de 1 p.p. na taxa de inadimplência faz o spread bancário aumentar em 1,33 p.p.
Como de praxe, os códigos do exercício estão disponíveis no repositório do Clube do Código.
____________________
ps: estamos aqui na Análise Macro com inscrições abertas para os cursos de Macro Aplicada e para a Formação em Produção de Trabalhos Empíricos usando o R, onde você aprende a lidar com dados da forma que eu mostrei no post com o uso do R. O primeiro lote está com 30% de desconto, mas deve acabar logo, então corre e se inscreve logo!


