[et_pb_section admin_label="section"][et_pb_row admin_label="row"][et_pb_column type="1_2"][et_pb_text admin_label="Texto" background_layout="light" text_orientation="justified" text_font="Abel||||" text_font_size="21" use_border_color="off" border_color="#ffffff" border_style="solid"]
Na edição 37 do Clube do Código, verificamos através de um teste de causalidade se existia relação entre interesse pela Uber e a taxa de desemprego. Os resultados encontrados sugeriam que não só a correlação entre as variáveis era elevada, como de fato existia uma causalidade no sentido de Granger entre aumentos da taxa de desemprego e aumento do interesse pela Uber. Na edição 46, por suposto, voltamos ao tema, de forma a construir um modelo VAR, explorando as funções impulso-resposta entre as variáveis, bem como a decomposição de variância, temas do nosso Curso de Séries Temporais usando o R. Nesse post, resumimos os resultados encontrados.
[/et_pb_text][/et_pb_column][et_pb_column type="1_2"][et_pb_image admin_label="Imagem" src="https://analisemacro.com.br/wp-content/uploads/2018/09/extraoutubro.png" show_in_lightbox="off" url="https://analisemacro.com.br/cursos-de-r/" url_new_window="off" use_overlay="off" animation="off" sticky="off" align="center" force_fullwidth="off" always_center_on_mobile="on" use_border_color="off" border_color="#ffffff" border_style="solid"]
[/et_pb_image][/et_pb_column][/et_pb_row][et_pb_row admin_label="row"][et_pb_column type="4_4"][et_pb_text admin_label="Texto" background_layout="light" text_orientation="justified" text_font="Abel||||" text_font_size="21" use_border_color="off" border_color="#ffffff" border_style="solid"]
A primeira parte de qualquer exercício de análise de dados, como aprendemos em nosso Curso de Introdução ao R e nosso Curso de Análise de Conjuntura usando o R é coletar os dados. Para esse exercício específico, nós utilizamos como proxy para o interesse pela Uber as buscar relacionadas à palavra-chave uber no google trends. De modo a coletar os dados, utilizamos o pacote gtrendsR conforme abaixo.
library(gtrendsR)
trends = gtrends('uber', geo='BR')
Já o desemprego foi especificado pela taxa de desemprego disponibilizada pela PNAD Contínua do IBGE. Essa variável foi coletada através do pacote sidraR como abaixo.
library(sidrar) desemprego = get_sidra(api='/t/6381/n1/all/v/4099/p/all/d/v4099%201')
De posse dos dados, a segunda parte é tratá-los, uma vez que os mesmos não estão em um formato comum sob o qual podem ser relacionados. O tratamento da taxa de desemprego é mais simples, posto que basta retirar o valor da taxa no data frame obtido a partir do SIDRA-IBGE, transformando a mesma em uma série temporal mensal. Já o interesse pela Uber é um pouco mais complicado, uma vez que os dados obtidos possuem uma frequência semanal. De modo que a mesma possa ser relacionada à taxa de desemprego, precisamos primeiro ordenar o interesse pela Uber de acordo com um vetor de datas, bem como mensalizar os mesmos, como aprendemos em nosso Curso de Introdução ao R. O código abaixo exemplifica.
gtrends = data.frame(time=trends$interest_over_time$date, empregos=as.numeric(trends$interest_over_time$hits)) gtrends$time = as.Date(gtrends$time, format='%d/%m/%Y') gtrends = xts(gtrends$empregos, order.by=gtrends$time) gtrends = gtrends[complete.cases(gtrends)] gtrends = ts(apply.monthly(gtrends, FUN=mean), start=c(2013,09), freq=12)
Uma vez tratados os dados, podemos gerar o gráfico abaixo com as séries obtidas.
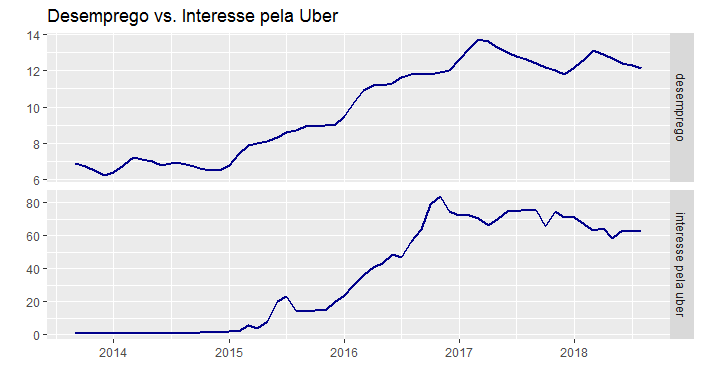
Como se pode notar, o comportamento das séries parece ser bem similar ao longo do período selecionado. Isso acabou nos motivando a verificar se, de fato, existe uma relação entre elas. Primeiro, plotamos um gráfico de correlação como abaixo.
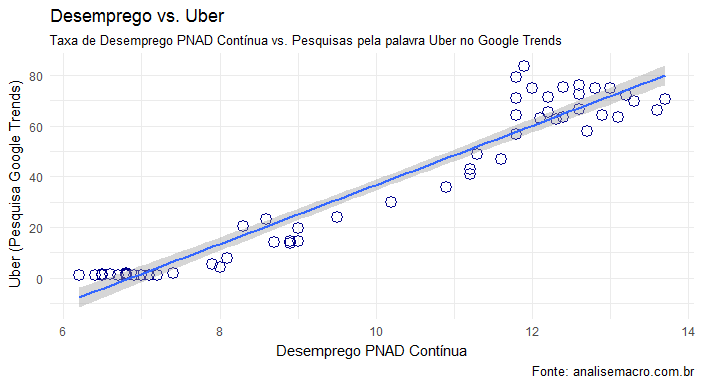
Como se pode notar, de fato, existe uma forte correlação positiva entre as séries. Isso, entretanto, não quer dizer muita coisa, uma vez que correlação não implica causalidade. Duas séries distintas podem ter uma alta correlação - positiva ou negativa - e ainda assim não terem nada em comum. De forma a avançar no nosso entendimento, construímos um Vetor Autorregressivo (VAR) entre as variáveis, como aprendemos no nosso Curso de Séries Temporais usando o R. Com o modelo estimado, nós podemos extrair as funções impulso-resposta, isto é, damos um choque em uma variável e observamos a resposta na outra. O gráfico abaixo ilustra um choque no desemprego e a resposta no interesse pela Uber.

O gráfico mostra que um choque na taxa de desemprego faz o interesse pela Uber aumentar. Ademais, a partir do modelo VAR, fizemos uma decomposição de variância entre as variáveis. Observa-se que 70% da variância do interesse pela Uber é explicada pela taxa de desemprego, passados 12 meses, enquanto apenas 23% da variância do desemprego é explicada pelo interesse pela Uber. Em outras palavras, os resultados encontrados sugerem que há, de fato, uma relação positiva entre as variáveis, no sentido mais forte do desemprego para o interesse pela Uber. Essas evidências se somam ao teste de causalidade feito em edição anterior do Clube do Código.
Todos os códigos e detalhes estarão na edição 46 do Clube do Código, de modo que os membros do Clube possam reproduzir integralmente o exercício. Ainda não é membro do Clube? Conheça e assine aqui.
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row admin_label="row"][et_pb_column type="4_4"][et_pb_image admin_label="Imagem" src="https://analisemacro.com.br/wp-content/uploads/2018/09/turmasdeoutubro.png" show_in_lightbox="off" url="https://analisemacro.com.br/cursos-de-r/" url_new_window="off" use_overlay="off" animation="off" sticky="off" align="center" force_fullwidth="off" always_center_on_mobile="on" use_border_color="off" border_color="#ffffff" border_style="solid"]
[/et_pb_image][/et_pb_column][/et_pb_row][/et_pb_section]

