 A análise do mercado de trabalho tem sido um dos pontos mais importantes da atual conjuntura. Afinal, é preciso explicar a leitores e clientes os motivos pelos quais a despeito do baixo crescimento mostrado pelas Contas Nacionais, o desemprego encontra-se próximo à mínima histórica. Assunto que já tratei em algumas oportunidades nesse e em outros espaços (veja aqui). Hoje, visando aumentar o grau de compreensão dos leitores sobre o mercado de trabalho brasileiro, vou replicar aqui um estudo do Bradesco feito no ano passado, que relaciona o Cadastro Geral de Empregados e Desempregados do Ministério do Trabalho (CAGED) com a Pesquisa Mensal de Emprego do IBGE (PME). A análise econométrica feita pelo Banco sugere que variações passadas daquela ajudam a explicar variações contemporâneas desta. Para verificar esse resultado, farei uso do Teste da Causalidade de Granger, disponibilizando os dados no final para quem se interessar em igualmente replicar o exercício.
A análise do mercado de trabalho tem sido um dos pontos mais importantes da atual conjuntura. Afinal, é preciso explicar a leitores e clientes os motivos pelos quais a despeito do baixo crescimento mostrado pelas Contas Nacionais, o desemprego encontra-se próximo à mínima histórica. Assunto que já tratei em algumas oportunidades nesse e em outros espaços (veja aqui). Hoje, visando aumentar o grau de compreensão dos leitores sobre o mercado de trabalho brasileiro, vou replicar aqui um estudo do Bradesco feito no ano passado, que relaciona o Cadastro Geral de Empregados e Desempregados do Ministério do Trabalho (CAGED) com a Pesquisa Mensal de Emprego do IBGE (PME). A análise econométrica feita pelo Banco sugere que variações passadas daquela ajudam a explicar variações contemporâneas desta. Para verificar esse resultado, farei uso do Teste da Causalidade de Granger, disponibilizando os dados no final para quem se interessar em igualmente replicar o exercício.
As pesquisas
As duas pesquisas possuem metodologias bastante distintas. Enquanto o CAGED é uma pesquisa nacional, a PME engloba apenas as seis maiores regiões metropolitanas. Além disso, o CAGED avalia o fluxo mensal de admitidos e demitidos no regime formal, já a PME verifica o estoque de ocupados e desocupados a cada ponto do tempo. As demais diferenças entre as pesquisas estão resumidas na tabela abaixo.

Nesse contexto, antes mesmo de abrir o pacote estatístico é preciso compatibilizar as pesquisas. Isto é, torná-las comparáveis. Para isso, tomou-se os dados do CAGED apenas das seis regiões metropolitanas avaliadas na PME (Recife, Salvador, BH, Rio, SP e Porto Alegre). Na PME considerou-se a população ocupada em empresas privadas com carteira de trabalho. Ademais, foi tomada a variação da média móvel trimestral de ambas as séries para o período de maio de 2003 a abril de 2014, em um total de 132 observações. O gráfico acima ilustra o comportamento das séries. Para acessar o CAGED e a PME consulte as instruções no final do post.
Testes de Raiz Unitária e Estacionariedade
O próximo passo é importar os dados para algum programa estatístico (R, Gretl, Eviews...). Vou usar o Eviews nesse exercício e realizar os testes ADF, ADF GLS, PP e KPSS para determinar se as séries possuem raiz unitária ou se são estacionárias. Os resultados estão resumidos nas duas figuras que seguem.
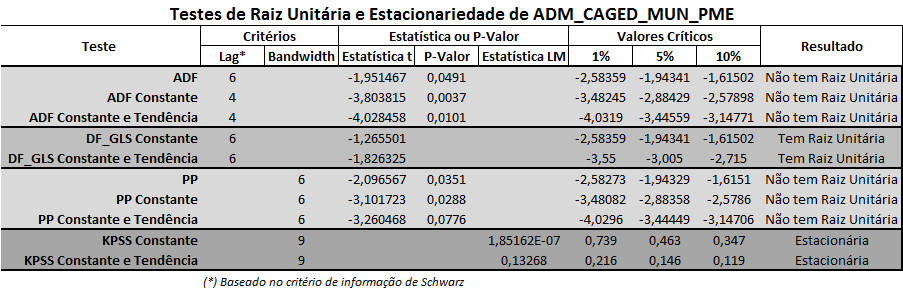
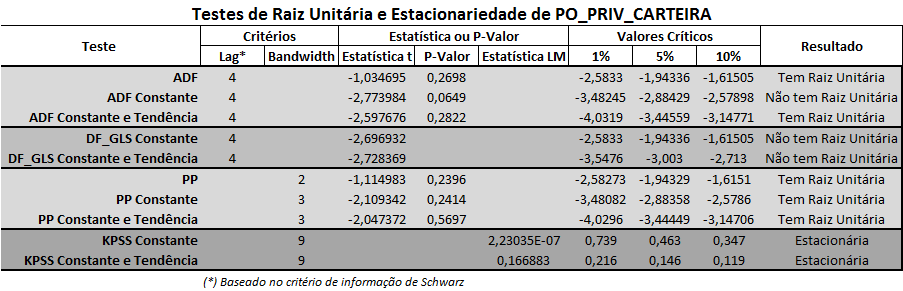
Os resultados indicam que a série ADM_CAGED_MUN_PME é I(0) enquanto a série PO_PRIV_CARTEIRA pode ser I(1). Isso traz algumas considerações para verificar causalidade, que trato a seguir.
Teste de Causalidade de Granger
Na seção anterior chegamos à conclusão que a série PO_PRIVADA_CARTEIRA pode ser I(1) enquanto a série ADM_CAGED_MUN_PME era I(0). Desse modo, adotei duas estratégias. Em um primeiro exercício, não diferenciei as séries. Segui nessa abordagem o script de Toda and Yamamoto (1995), sugerido pelo professor Dave Giles em seu blog Econometrics Beat - sugiro que os mais interessados consultem aqui. Após os procedimentos rotineiros (ver nas observações o problema principal encontrado) para esse tipo de teste (ver os critérios de informação para determinar o número de defasagens da matriz, ver a autocorrelação dos resíduos, verificar se o modelo é "estável", a partir das raízes do polinômio...) e os ajustes sugeridos pelo paper, rodei o teste de granger. Os resultados para essa abordagem estão postos abaixo.
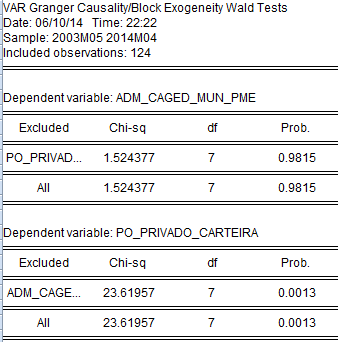
A hipótese nula do teste de granger é que os coeficientes das observações defasadas de X não são estatisticamente significativos para explicar a variação de Y. Logo, rejeitar a hipótese nula implica que as variações passadas de X ajudam a explicar a variação contemporânea de Y. Na figura acima é possível verificar na parte de cima que não é possível rejeitar a hipótese nula quando a variável dependente é ADM_CAGED_MUN_PME. Já na parte de baixo, quando a variável dependente é a PO_PRIVADO_CARTEIRA a hipótese nula do teste de granger é rejeitada. O teste sugere, desse modo, que os resultados do CAGED precedem os resultados da PME.
Em um segundo exercício, criei o VAR com as séries diferenciadas. Após fazer os mesmos procedimentos rotineiros, rodei o teste de granger. Os resultados corroboraram com a evidência acima, como mostra a figura seguinte.
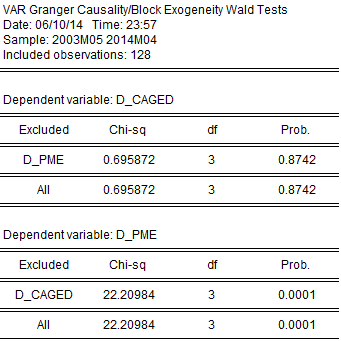
Conclusões
A baixa taxa de desemprego tem implicações importantes para a conjuntura econômica, seja em termos de crescimento ou de inflação. Como mostrei aqui, por exemplo, desemprego e inflação de serviços (a parte do IPCA que tem ficado sistematicamente em 9% no acumulado em 12 meses), cointegram, logo se o desemprego está baixo, a inflação de serviços deve continuar elevada. Em termos de crescimento, baixo desemprego exige que a taxa de investimento e/ou a produtividade da economia aumentem, dado que aumentar o produto não é possível com o mero aumento de ocupação do fator trabalho. Desse modo, melhor compreender as relações que existem entre as pesquisas disponíveis é um passo importante para os interessados em conjuntura econômica.
(*) Observações:
(1) PME (www.sidra.ibge.gov.br)
(2) CAGED (http://bi.mte.gov.br/bgcaged, usuário: basico, senha=12345678)
(3) Minha planilha: Dados
(4) Meu arquivo Eviews: CagedPME
(5) O principal problema com os modelos estimados está nos resíduos, que apresentam autocorrelação serial. Esse problema persiste mesmo aumentando o intervalo de defasagem.
(6) Agradeço a meu amigo Sávio Cescon por ter me enviado esse estudo do Bradesco e os dados do CAGED desagregado tempos atrás, momento a partir do qual passei a me interessar cada vez mais pelos nuances do mercado de trabalho brasileiro.

