Essa semana, saíram dados do Cadastro Geral de Empregados e Desempregados (CAGED) do Ministério do Trabalho, referentes ao emprego formal, com carteira e dados mais amplos da Pesquisa Nacional por Amostram de Domicílios (PNAD Contínua). A seguir, comento alguns destaques de ambas as pesquisas, utilizando os scripts automáticos de R que ensino no nosso Curso de Análise de Conjuntura usando o R.
Os dados do CAGED podem ser baixados a partir do IPEADATA com o pacote ecoseries. O código a seguir exemplifica.
library(ecoseries)
## Baixar dados
caged = ts(series_ipeadata('272844966',
periodicity = 'M')$serie_272844966$valor,
start=c(1999,05), freq=12)
Como há uma sazonalidade desconcertante nos dados, é preciso fazer um ajuste nos mesmos - ensino nesse vídeo aqui a fazer o ajuste. Uma vez feito o ajuste, podemos construir um gráfico como o abaixo, usando o pacote ggplot2.
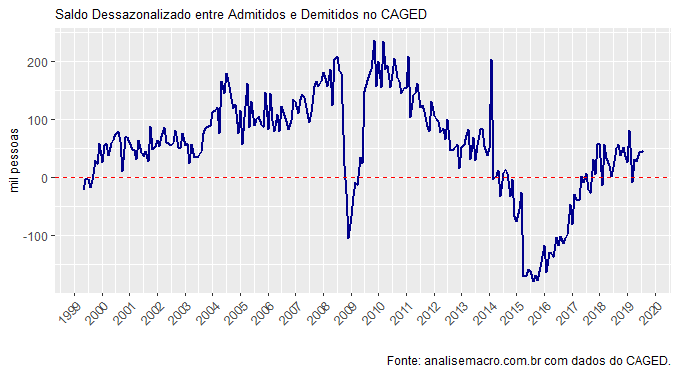
Há, por suposto, uma nítida recuperação do saldo entre admitidos e demitidos. Na ponta e sem ajuste, foram gerados esse ano 539.640 postos líquidos de trabalho com carteira assinada. Isso é uma boa notícia, obviamente, para um mercado de trabalho que ainda sofre os efeitos de uma das maiores recessões da nossa História.
Olhando para o mesmo item na PNAD Contínua, isto é, a população ocupada com carteira assinada, o ritmo de recuperação ainda se mostra bastante lento, com alguns recuos na margem, como é possível notar no gráfico abaixo.
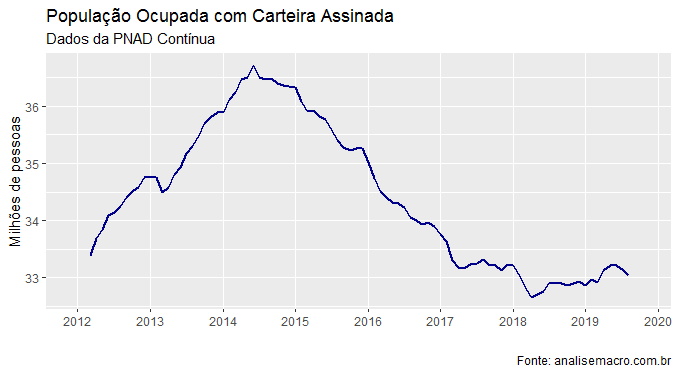
O estoque de ocupados com carteira vem caindo desde junho nessa pesquisa. Na margem, por suposto, a recuperação da população ocupada vem sendo liderada pelos ocupados sem carteira e pelos "conta-própria", como é possível verificar na abertura desse grupo, como no gráfico abaixo.
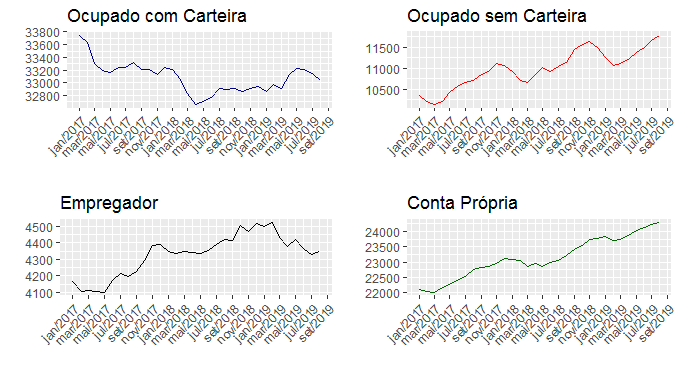
Vem daí, por suposto, os vetores que tem impulsionado uma queda (lenta) da taxa de desocupação, como pode ser visto no gráfico a seguir.
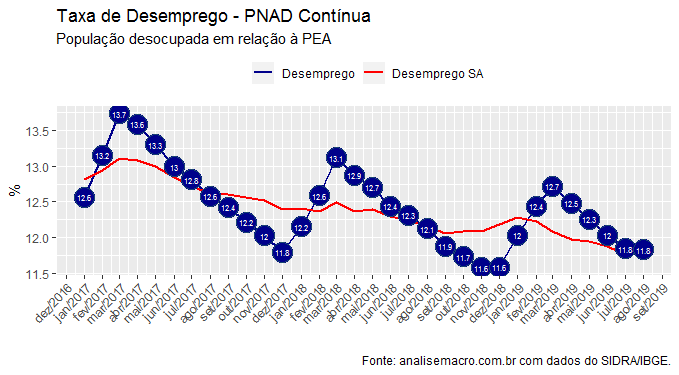
CAGED e PNAD Contínua têm metodologias e abordagens distintas, obviamente, mas é curioso notar a discrepância entre uma e outra na margem. A acompanhar os próximos meses...


