[et_pb_section admin_label="section"][et_pb_row admin_label="row"][et_pb_column type="1_2"][et_pb_text admin_label="Texto" background_layout="light" text_orientation="justified" text_font="Abel||||" text_font_size="21" use_border_color="off" border_color="#ffffff" border_style="solid"]
A população desocupada (PD) chegou a 12,868 milhões de pessoas no trimestre móvel encerrado em julho, para uma população economicamente ativa (PEA) de 104,529 milhões de pessoas.Com efeito, a taxa de desemprego (PD/PEA) chegou a 12,3%. Houve, em relação a junho, um recuo de 98 mil na população desocupada, refletindo um avanço de 424 mil pessoas na população ocupada (PO) e de 326 mil na PEA. Abaixo, trazemos alguns gráficos que ilustram o comportamento do mercado de trabalho no último dado divulgado pelo IBGE. Uma análise completa da PNAD com o uso do R é, a propósito, ensinada no nosso Curso de Análise de Conjuntura usando o R.
[/et_pb_text][/et_pb_column][et_pb_column type="1_2"][et_pb_image admin_label="Imagem" src="https://analisemacro.com.br/wp-content/uploads/2018/08/ultimosdias6.png" show_in_lightbox="off" url="https://analisemacro.com.br/cursos-de-r/" url_new_window="off" use_overlay="off" animation="off" sticky="off" align="center" force_fullwidth="off" always_center_on_mobile="on" use_border_color="off" border_color="#ffffff" border_style="solid"]
[/et_pb_image][/et_pb_column][/et_pb_row][et_pb_row admin_label="row"][et_pb_column type="4_4"][et_pb_text admin_label="Texto" background_layout="light" text_orientation="justified" text_font="Abel||||" text_font_size="21" use_border_color="off" border_color="#ffffff" border_style="solid"]
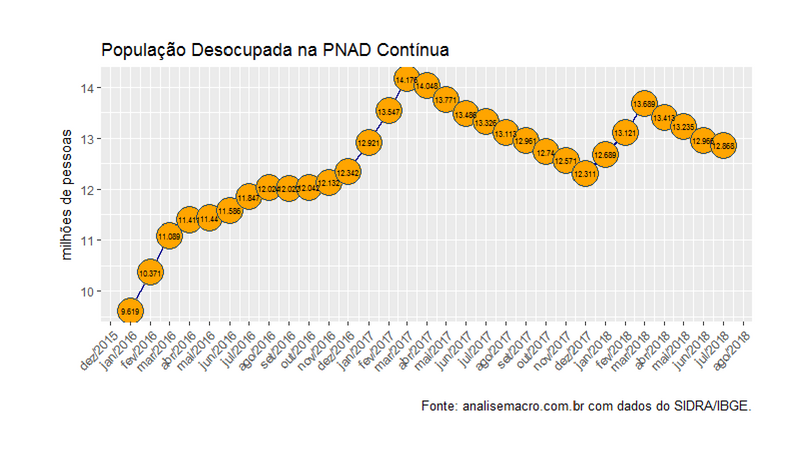
A população desocupada era de 12,311 milhões em dezembro, tendo avançado para 12,868 milhões no trimestre encerrado em julho, na série sem ajustes. Como a série tem sazonalidade, contudo, é preciso tratar essa característica. Assim, na série com ajuste sazonal, a desocupação saiu de 13,130 milhões em dezembro para 12,730 milhões no trimestre encerrado em julho. O gráfico abaixo, por suposto, compara as duas séries.

Abaixo, por suposto, colocamos a taxa de desemprego (PD/PEA) com a sua respectiva taxa ajustada sazonalmente.
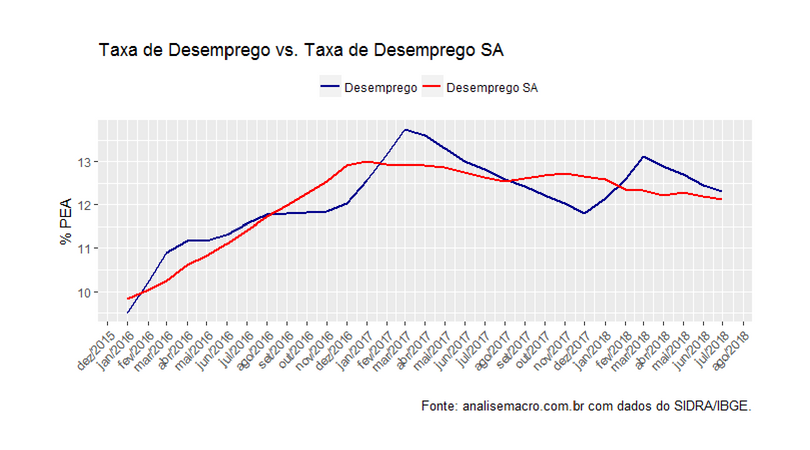
Uma apresentação completa da PNAD Contínua está disponível aqui. No nosso Curso de Análise de Conjuntura usando o R, por suposto, os alunos aprendem o passo a passo para gerar apresentações como essa, coletando os dados de forma automática do SIDRA e tratando os mesmos com o R. Já na sequência de Cursos de Econometria, os alunos aprendem a construir modelos univariados e multivariados para séries como a do desemprego. As inscrições, por suposto, para as turmas de setembro, que começam no próximo dia 3/9, estão se encerrando: corra e garanta a sua vaga!
[/et_pb_text][et_pb_image admin_label="Imagem" src="https://analisemacro.com.br/wp-content/uploads/2018/08/coversetembro.png" show_in_lightbox="off" url="https://analisemacro.com.br/cursos-de-r/" url_new_window="off" use_overlay="off" animation="off" sticky="off" align="center" force_fullwidth="off" always_center_on_mobile="on" use_border_color="off" border_color="#ffffff" border_style="solid"]
[/et_pb_image][/et_pb_column][/et_pb_row][/et_pb_section]

