O governo divulgou nessa semana os dados do Cadastro Geral de Empregados e Desempregados, o famoso CAGED. Com efeito, vi muitas matérias na imprensa sobre o resultado negativo em março de saldo negativo de 43.196 entre admissões e demissões. O problema desse resultado é que, como vemos em nosso Curso de Análise de Conjuntura usando o R, ele está contaminado por um problema típico de séries temporais, chamado sazonalidade, isto é, um comportamento que se apresenta de forma regular ao longo dos anos.
Para ilustrar esse problema, coloco abaixo o saldo do CAGED, que peguei do IPEADATA com o pacote ecoseries.
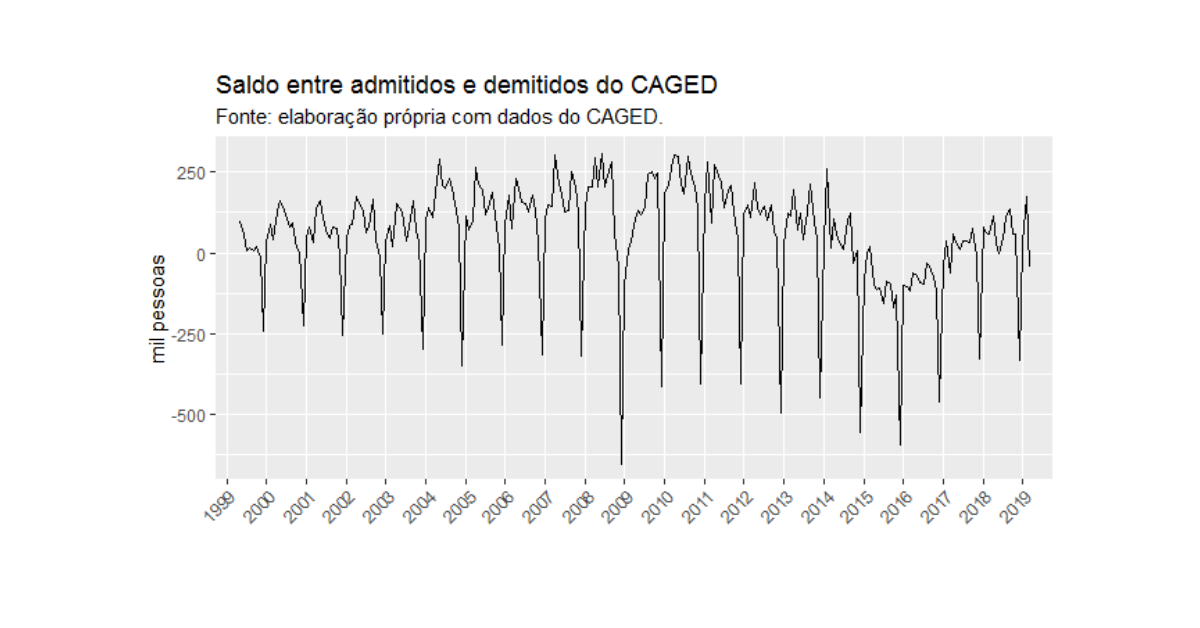 É nítido no gráfico um comportamento regular da série ao longo dos anos, não é mesmo? Assim, de forma a fazer uma análise precisa do que está acontecendo com a série do CAGED, precisamos primeiro "limpar" a sazonalidade. No R, como vemos em nosso Curso de Análise de Conjuntura usando o R, podemos fazer isso através do pacote seasonal. Fazendo esse tratamento, obtemos os dados do CAGED dessazonalizados como abaixo.
É nítido no gráfico um comportamento regular da série ao longo dos anos, não é mesmo? Assim, de forma a fazer uma análise precisa do que está acontecendo com a série do CAGED, precisamos primeiro "limpar" a sazonalidade. No R, como vemos em nosso Curso de Análise de Conjuntura usando o R, podemos fazer isso através do pacote seasonal. Fazendo esse tratamento, obtemos os dados do CAGED dessazonalizados como abaixo.
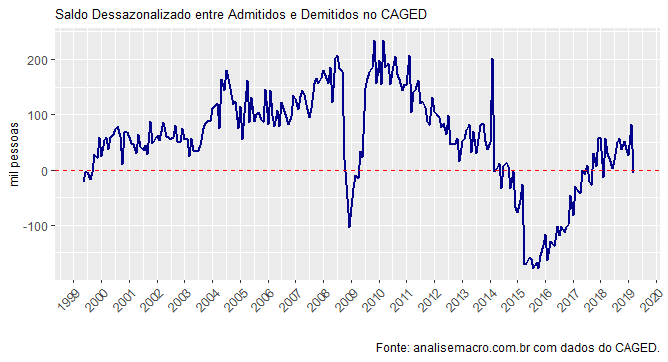
Totalmente diferente, não é mesmo? Com esse gráfico podemos ver que o mercado de trabalho vem ensaiando uma recuperação desde 2015/2016. Ao mesmo tempo, podemos ver que na ponta, de fato, março foi mesmo um mês ruim. A última vez que a série dessazonalizada tinha apresentado um mês negativo havia sido em fevereiro do ano passado.
 Essa, diga-se, é a forma correta de fazer a análise dos dados, que você aprende em nosso Curso de Análise de Conjuntura usando o R.
Essa, diga-se, é a forma correta de fazer a análise dos dados, que você aprende em nosso Curso de Análise de Conjuntura usando o R.

