Os dados da indústria referentes a novembro divulgados agora há pouco pelo IBGE acabaram vindo pior do que o esperado pelo mercado. Houve queda de 1,2% na comparação com outubro e de 1,7% na comparação interanual. Com efeito, o trimestre móvel encerrado em novembro acabou mostrando queda de 0,1% na comparação com o trimestre móvel encerrado em outubro. A produção industrial conta com script automático que é ensinado/disponibilizado no nosso Curso de Análise de Conjuntura usando o R. A tabela abaixo resume os números principais da indústria geral.
| Mensal | Interanual | Trimestral | Anual | |
|---|---|---|---|---|
| 2019 Sep | 0,2 | 1,0 | 0,4 | -1,3 |
| 2019 Oct | 0,8 | 1,1 | 0,7 | -1,3 |
| 2019 Nov | -1,2 | -1,7 | -0,1 | -1,3 |
Os dados da produção industrial estão disponíveis no SIDRA do IBGE. Para pegá-los, nós podemos utilizar o pacote sidrar como abaixo.
library(sidrar) # Importação dos dados table1 = get_sidra(api='/t/3653/n1/all/v/3134,3135/p/all/c544/all/d/v3134%201,v3135%201') table2 = get_sidra(api='/t/3651/n1/all/v/3134,3135/p/all/c543/129278,129283,129300,129301,129305/d/v3134%201,v3135%201')
Com a função get_sidra() nós podemos pegar os dados da produção industrial referentes às categorias econômicas e atividades industriais. A função, contudo, retorna um data frame bagunçado, que precisa ser tratado para que consigamos ter uma matriz onde cada coluna representa uma variável e cada linha seja uma observação, que nesse caso é uma observação mensal - uma série temporal mensal. Há várias formas de coletar os dados e construir um data frame, tibble ou mesmo matriz limpas. Abaixo, dou o exemplo mais simples para pegar os dados da indústria geral com ajuste sazonal.
geral_sa = table1$Valor[table1$`Variável (Código)`==3134 & table1$`Seções e atividades industriais (CNAE 2.0) (Código)`==129314]
É possível automatizar a busca com um loop, de modo a coletar todos as variáveis que você deseja. Em seguida, podemos criar um tibble como no código a seguir.
# As tibble
dates = seq(as.Date('2002-01-01'), ultima, by='1 month')
data_tl = tibble(dates, geral, extrativa, transform, bk, bi, bc, bcd,
bcnd)
data_sa_tl = tibble(dates, geral_sa, extrativa_sa, transform_sa, bk_sa,
bi_sa, bc_sa, bcd_sa, bcnd_sa)
A seguir, podemos construir um gráfico da produção industrial geral com ajuste sazonal restrita a dezembro de 2016 para frente com o uso da função filter() do pacote dplyr.
filter(data_sa_tl, dates > '2016-12-01') %>%
ggplot(aes(x=dates, y=geral_sa))+
annotate("rect", fill = "lightblue", alpha = 0.7,
xmin = as.Date('2019-07-01'),
xmax = as.Date('2019-11-01'),
ymin = -Inf, ymax = Inf)+
geom_line(size=.8, colour='darkblue')+
scale_x_date(breaks = date_breaks("2 month"),
labels = date_format("%b/%Y"))+
theme(axis.text.x=element_text(angle=45, hjust=1),
plot.title = element_text(size=12, colour='darkblue',
face='bold'))+
labs(x='', y='',
title='Produção Industrial Geral (com ajuste sazonal)',
caption='Fonte: analisemacro.com.br com dados do IBGE')
Por fim, o gráfico...
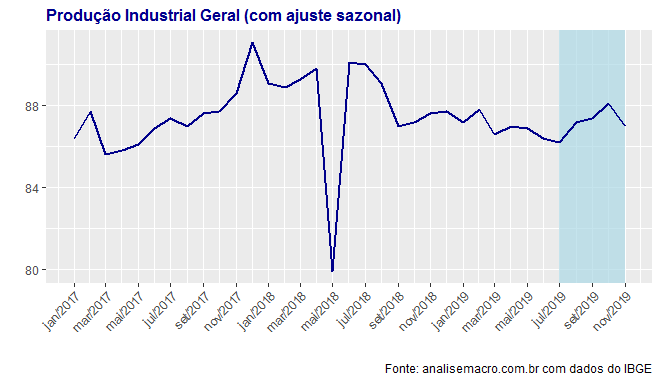
Como é possível verificar pelo gráfico, a indústria abortou a recuperação que vinha sendo ensaiada nos últimos meses. É, de fato, o setor que mais tem sentido os choques dos últimos meses.
O script, a propósito, segue com a análise por categorias e atividades da indústria.
_____________________________


