[et_pb_section admin_label="section"][et_pb_row admin_label="row"][et_pb_column type="4_4"][et_pb_text admin_label="Texto" background_layout="light" text_orientation="justified" text_font="Verdana||||" text_font_size="18" use_border_color="off" border_color="#ffffff" border_style="solid"]
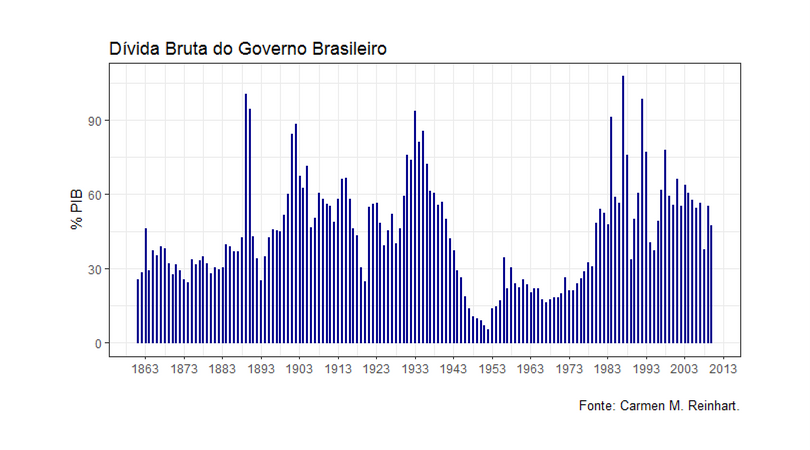
O Roberto Ellery publicou um post no seu blog mostrando grande preocupação com o comportamento da Dívida Bruta brasileira. Para isso, utilizou dados do livro da Carmen M. Reinhart sobre o endividamento brasileiro desde o Império. Achei interessante divulgar porque, como todo mundo sabe, encontrar dados longos para variáveis macroeconômicas desse país é um enorme sacrifício. Abaixo o código para baixar os dados da relação Dívida/PIB.
library(XLConnect)
library(ggplot2)
library(scales)
#### Dívida segundo Carmen M. Reinhart
url = 'http://www.carmenreinhart.com/user_uploads/data/7_data.xls'
temp = tempfile()
download.file(url, destfile=temp, mode='wb')
data = loadWorkbook(temp)
divida = readWorksheet(data, sheet = 'Brazil', header = TRUE,
startRow = 59)[,7]
time = seq(as.Date('1861-01-01'), as.Date('2010-01-01'),
by='1 year')
df = data.frame(time=time, divida=divida)
ggplot(df, aes(x=time))+
geom_bar(aes(y=divida),
stat='identity', colour='darkblue', fill='darkblue',
width=50)+
scale_x_date(breaks = date_breaks("10 years"),
labels = date_format("%Y"))+
theme_bw()+xlab('')+ylab('% PIB')+
labs(title='Dívida Bruta do Governo Brasileiro',
caption='Fonte: Carmen M. Reinhart.')
E abaixo o gráfico...
[/et_pb_text][et_pb_divider admin_label="Divisor" color="#000000" show_divider="on" divider_style="dotted" divider_position="top" divider_weight="10" hide_on_mobile="off" height="5"] [/et_pb_divider][/et_pb_column][/et_pb_row][et_pb_row admin_label="row"][et_pb_column type="1_2"][et_pb_text admin_label="Texto" background_layout="light" text_orientation="justified" text_font="Verdana||||" text_font_size="18" use_border_color="off" border_color="#ffffff" border_style="solid"]
A Análise de Dados está presente em praticamente todas as áreas do conhecimento. Estar pronto para coletar, tratar, analisar e apresentar dados é condição mais do que necessária no mundo atual.
Pensando nisso, preparamos cursos aplicados e super didáticos utilizando o R, a linguagem padrão da análise de dados. Clique na figura ao lado e conheça nossos cursos!
[/et_pb_text][/et_pb_column][et_pb_column type="1_2"][et_pb_image admin_label="Imagem" src="https://analisemacro.com.br/wp-content/uploads/2016/04/novembro.png" show_in_lightbox="off" url="https://analisemacro.com.br/cursos-de-r/" url_new_window="off" use_overlay="off" animation="left" sticky="off" align="center" force_fullwidth="off" always_center_on_mobile="on" use_border_color="off" border_color="#ffffff" border_style="solid"] [/et_pb_image][/et_pb_column][/et_pb_row][et_pb_row admin_label="row"][et_pb_column type="1_3"][et_pb_gallery admin_label="Galeria" gallery_ids="17132,17133,17134" fullwidth="on" show_title_and_caption="off" show_pagination="off" background_layout="light" auto="on" auto_speed="6000" hover_overlay_color="rgba(255,255,255,0.9)" caption_all_caps="off" use_border_color="off" border_color="#ffffff" border_style="solid" saved_tabs="all"] [/et_pb_gallery][et_pb_gallery admin_label="Galeria" gallery_ids="17136,17137,17138" fullwidth="on" show_title_and_caption="off" show_pagination="off" background_layout="light" auto="on" auto_speed="6000" hover_overlay_color="rgba(255,255,255,0.9)" caption_all_caps="off" use_border_color="off" border_color="#ffffff" border_style="solid" saved_tabs="all"] [/et_pb_gallery][/et_pb_column][et_pb_column type="2_3"][et_pb_team_member admin_label="Pessoa" saved_tabs="all" name="Vítor Wilher " position="Data Scientist" animation="left" background_layout="light" facebook_url="https://www.facebook.com/vitor.wilher.9" twitter_url="https://twitter.com/vitorwilherbr" linkedin_url="https://www.linkedin.com/in/v%C3%ADtor-wilher-78164024" use_border_color="off" border_color="#ffffff" border_style="solid"]
Vítor Wilher é Bacharel e Mestre em Economia, pela Universidade Federal Fluminense, tendo se especializado na construção de modelos macroeconométricos, política monetária e análise da conjuntura macroeconômica doméstica e internacional. Tem, ademais, especialização em Data Science pela Johns Hopkins University. Sua dissertação de mestrado foi na área de política monetária, titulada "Clareza da Comunicação do Banco Central e Expectativas de Inflação: evidências para o Brasil", defendida perante banca composta pelos professores Gustavo H. B. Franco (PUC-RJ), Gabriel Montes Caldas (UFF), Carlos Enrique Guanziroli (UFF) e Luciano Vereda Oliveira (UFF). Já trabalhou em grandes empresas, nas áreas de telecomunicações, energia elétrica, consultoria financeira e consultoria macroeconômica. É o criador da Análise Macro, startup especializada em treinamento e consultoria em linguagens de programação voltadas para data analysis, sócio da MacroLab Consultoria, empresa especializada em cenários e previsões e fundador do hoje extinto Grupo de Estudos sobre Conjuntura Econômica (GECE-UFF). É também Visiting Professor da Universidade Veiga de Almeida, onde dá aulas nos cursos de MBA da instituição, Conselheiro do Instituto Millenium e um dos grandes entusiastas do uso do R no ensino. Leia os posts de Vítor Wilher aqui. Caso queira, mande um e-mail para ele: vitorwilher@analisemacro.com.br
[/et_pb_team_member][/et_pb_column][/et_pb_row][/et_pb_section]

