
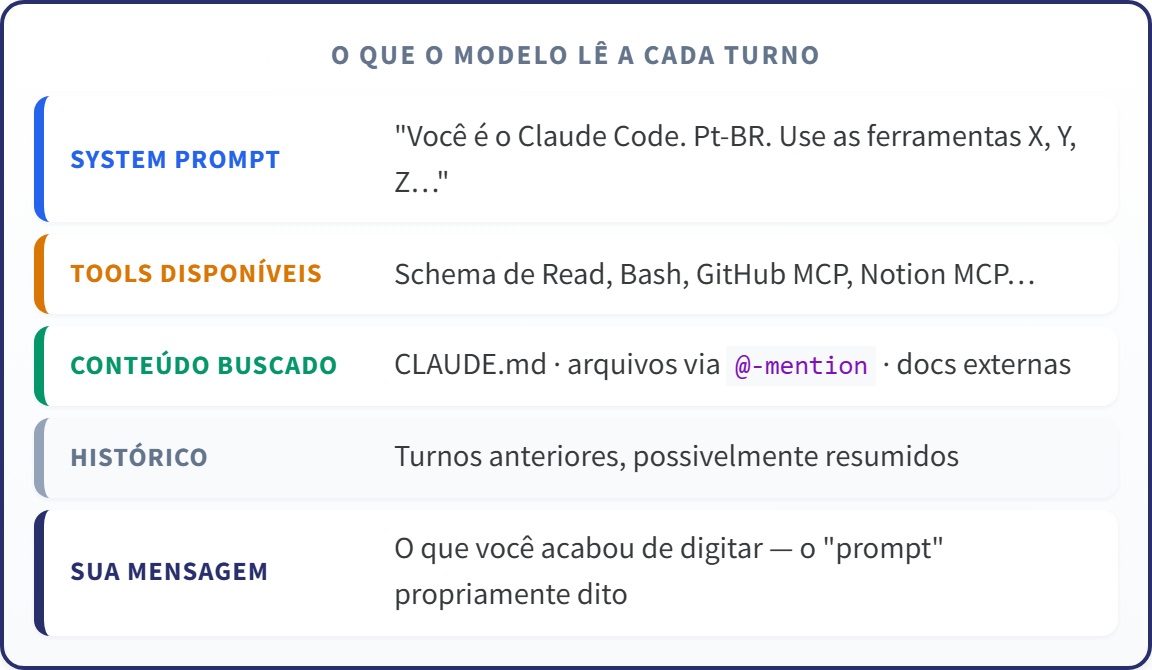
Context engineering é o trabalho de escolher e organizar tudo o que um modelo de IA lê antes de responder: instruções do sistema, documentos buscados, histórico da conversa, descrições de ferramentas e a sua pergunta.
A habilidade central de quem trabalha com LLM hoje deixou de ser escrever um prompt mais bonito e passou a ser decidir o que entra na janela de contexto a cada interação — porque o modelo só responde com base no que está ali, não no que ele "sabe".
Este guia mostra por que o foco migrou do prompt para o contexto, o que vive na janela a cada turno e quais alavancas você usa no Claude Code para controlar isso. O caminho passa por seis peças encaixadas (token, previsão, treino, alucinação, RAG e agente) que terminam todas no mesmo lugar: o contexto.
Como o modelo lê: tudo vira token
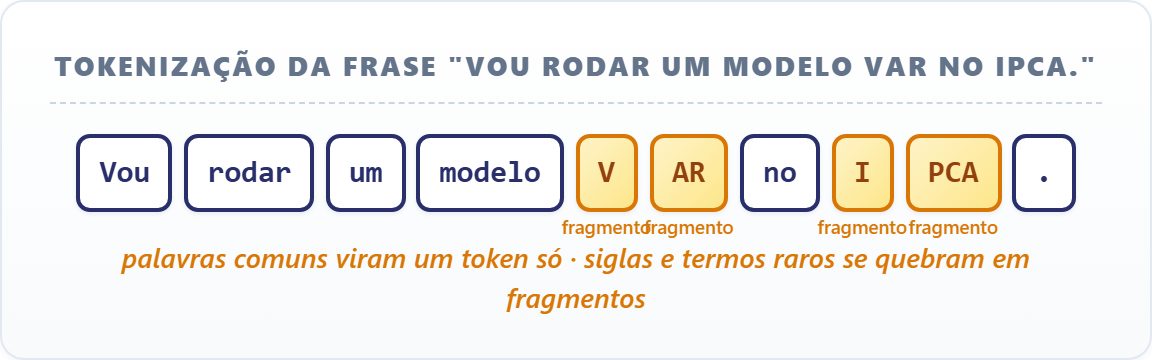
O computador opera com números, não com letras. Quando você manda um pedido para o Claude, a primeira coisa que acontece é a quebra do texto em pedaços chamados tokens: cada token é um trecho (uma palavra inteira, um fragmento ou um sinal de pontuação) com um número associado num dicionário interno do modelo, que costuma ter entre 50 e 200 mil entradas.
Palavras comuns viram um token só; siglas e termos raros se quebram em pedaços. Como o corpus de treino é majoritariamente em inglês, textos em português consomem mais tokens para a mesma informação.
Isso não é detalhe técnico solto: token é a unidade que você paga na API e a unidade que enche a janela de contexto. Um documento de mil palavras em português tende a ocupar de 1.500 a 1.800 tokens.
Saber estimar isso é o primeiro passo para entender por que o contexto é um recurso escasso que precisa ser gerenciado.
A tarefa única do LLM: prever o próximo token
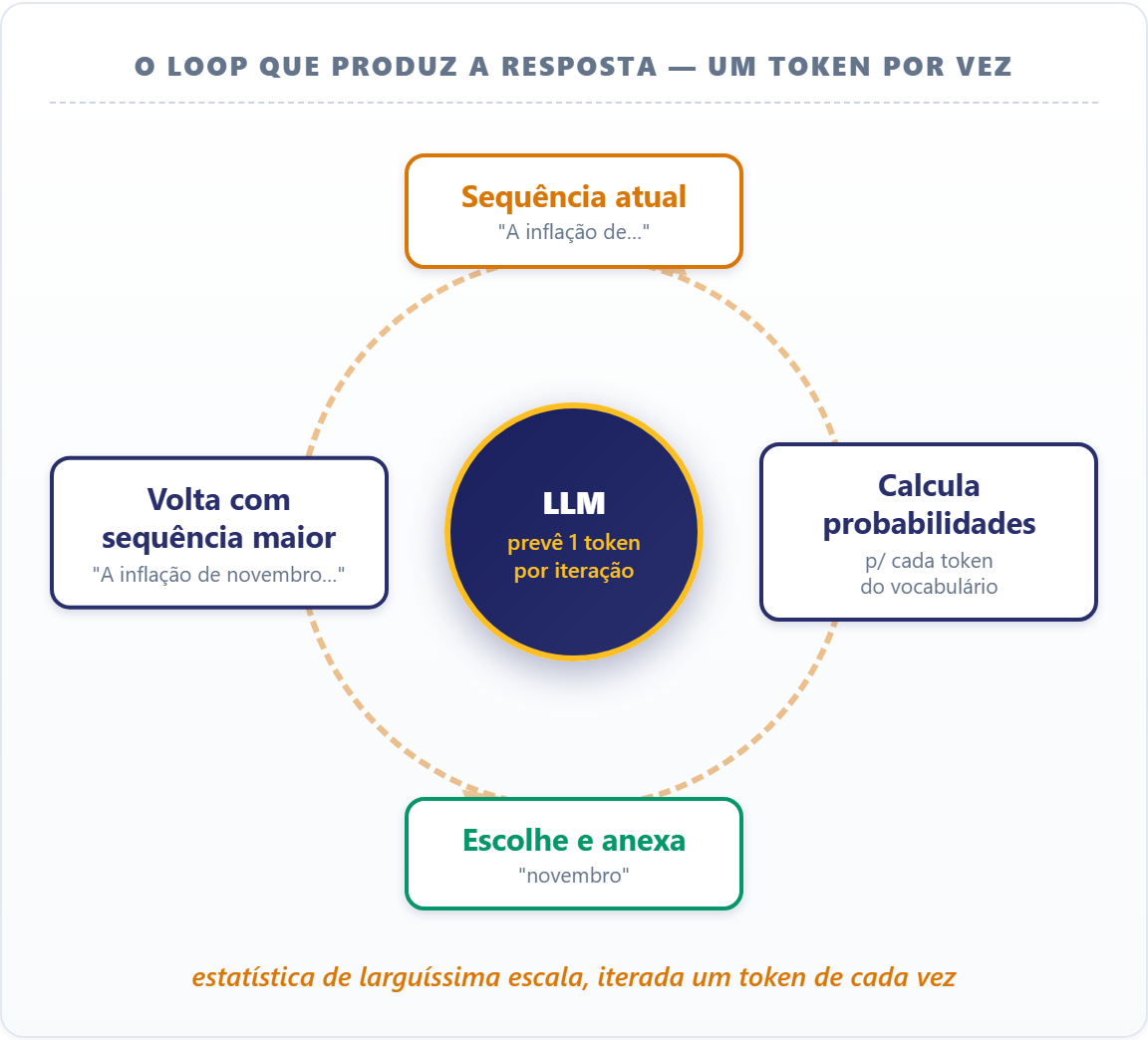
Com o texto virado em sequência de números, o modelo faz uma coisa só: recebe a sequência vista até agora e devolve, para cada token possível do dicionário, a probabilidade de ele ser o próximo. Escolhe um (geralmente o mais provável, com algum ruído controlado), anexa à sequência e repete, e toda resposta sai desse loop.
Não há raciocínio no sentido humano, e sim um modelo estatístico de larguíssima escala que aprendeu, observando bilhões de páginas, quais sequências de tokens fazem sentido. É por isso que o que você coloca antes da pergunta muda tanto a resposta: você está inclinando a distribuição de probabilidade do próximo token.
Por que o modelo não sabe a Selic de hoje
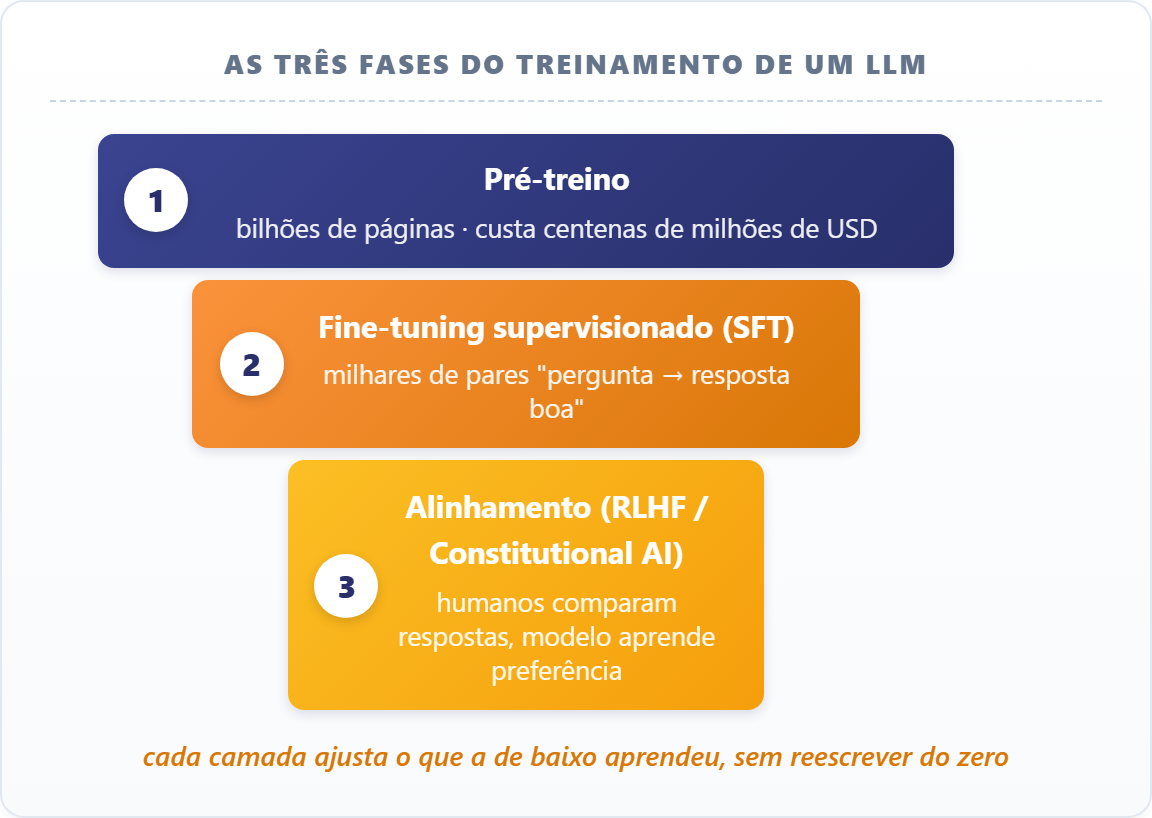
O treinamento de um LLM passa por três fases: o pré-treino (bilhões de páginas, custo de centenas de milhões de dólares), o fine-tuning supervisionado (milhares de pares "pergunta → resposta boa") e o alinhamento (humanos comparam respostas e o modelo aprende a preferência).
Cada fase ajusta o que a anterior aprendeu. Pré-treinar do zero é raríssimo justamente pelo custo, e por isso o mercado é dominado por meia dúzia de empresas.
O ponto prático é o que acontece quando o treino termina: o conhecimento do modelo congela num marco chamado knowledge cutoff, e eventos posteriores ele não conhece.
Perguntar "qual a Selic atual?" para um LLM puro, sem ferramenta de busca, equivale a pedir um chute baseado no que era verdade meses ou anos atrás — e a resposta pode soar confiante mesmo estando errada. Esse é o cenário-mãe da alucinação, e é o primeiro motivo pelo qual os fatos atuais precisam entrar pelo contexto.
Alucinação é estrutural, não um deslize ocasional
O LLM alucina: produz texto fluente e factualmente errado com a mesma confiança com que produz texto certo. O comportamento decorre de como ele funciona, prevendo o token mais provável em vez de consultar uma base de dados.
Os casos típicos são três: fato fora do cutoff (chuta com base no treino), fato muito específico (mistura fontes vizinhas e inventa, por exemplo, a bibliografia de um autor pouco famoso) e cálculo aritmético (estima o resultado de uma conta em vez de computá-lo).
Qualquer pipeline que dependa de fato atual ou específico precisa de um mecanismo para alimentar o modelo com os fatos certos no momento do pedido. Não dá para confiar que o modelo "sabe".
Quer entender IA por dentro, sem hype?
Toda semana publicamos guias práticos de Python, R e IA aplicados à economia, com o mecanismo explicado por dentro. Assine o Boletim AM e receba direto no e-mail. Para acesso a todos os cursos e materiais da casa, conheça o AM Black.
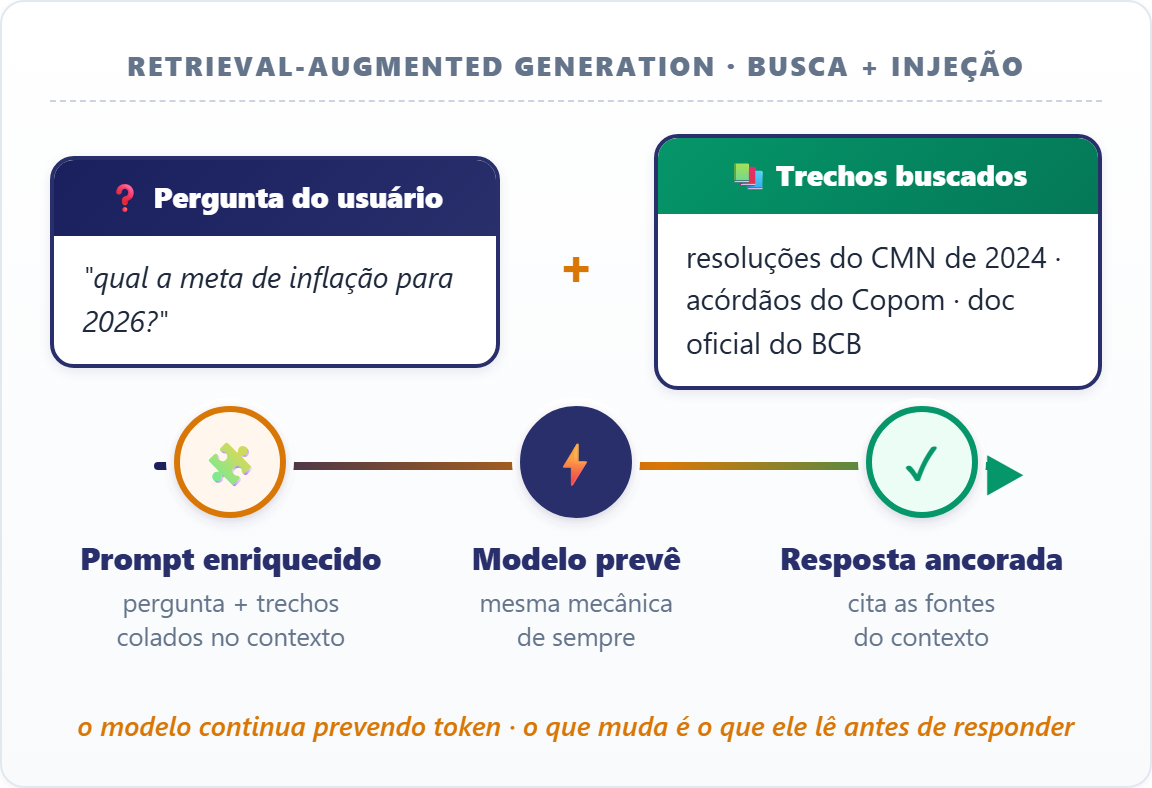
RAG: a resposta da indústria à alucinação
A solução mais comum para a alucinação chama-se RAG (Retrieval-Augmented Generation): em vez de torcer para o modelo lembrar, você busca os documentos relevantes antes e os cola no contexto junto com a pergunta.
A busca pode ser por palavra-chave clássica, por similaridade semântica via embeddings ou híbrida, e o princípio é o mesmo: o modelo responde sobre o que está no contexto, não sobre o que ele lembra. RAG transforma um chute estatístico numa resposta ancorada em fontes.
Não elimina a alucinação (se a busca trouxer o trecho errado, a resposta sai errada), mas reduz bastante. E abre a porta para o passo seguinte: se o modelo pode ler um documento que você buscou, por que não deixar que ele busque sozinho quando precisar? É aí que o modelo deixa de ser assistente e vira agente.
De assistente a agente: o modelo aciona ferramentas
Até aqui o modelo era passivo: você manda um prompt, ele responde, fim. A virada foi dar a ele a capacidade de acionar ferramentas durante a resposta.
A mecânica é uma extensão direta do que já vimos: o modelo continua prevendo tokens, mas foi treinado para às vezes emitir uma sequência especial que o servidor interpreta como "quero chamar a ferramenta X com estes argumentos".
O servidor executa, devolve o resultado em forma de mais tokens no contexto, e o modelo continua. Esse ciclo de pensar, agir, observar e repetir é o agentic loop.
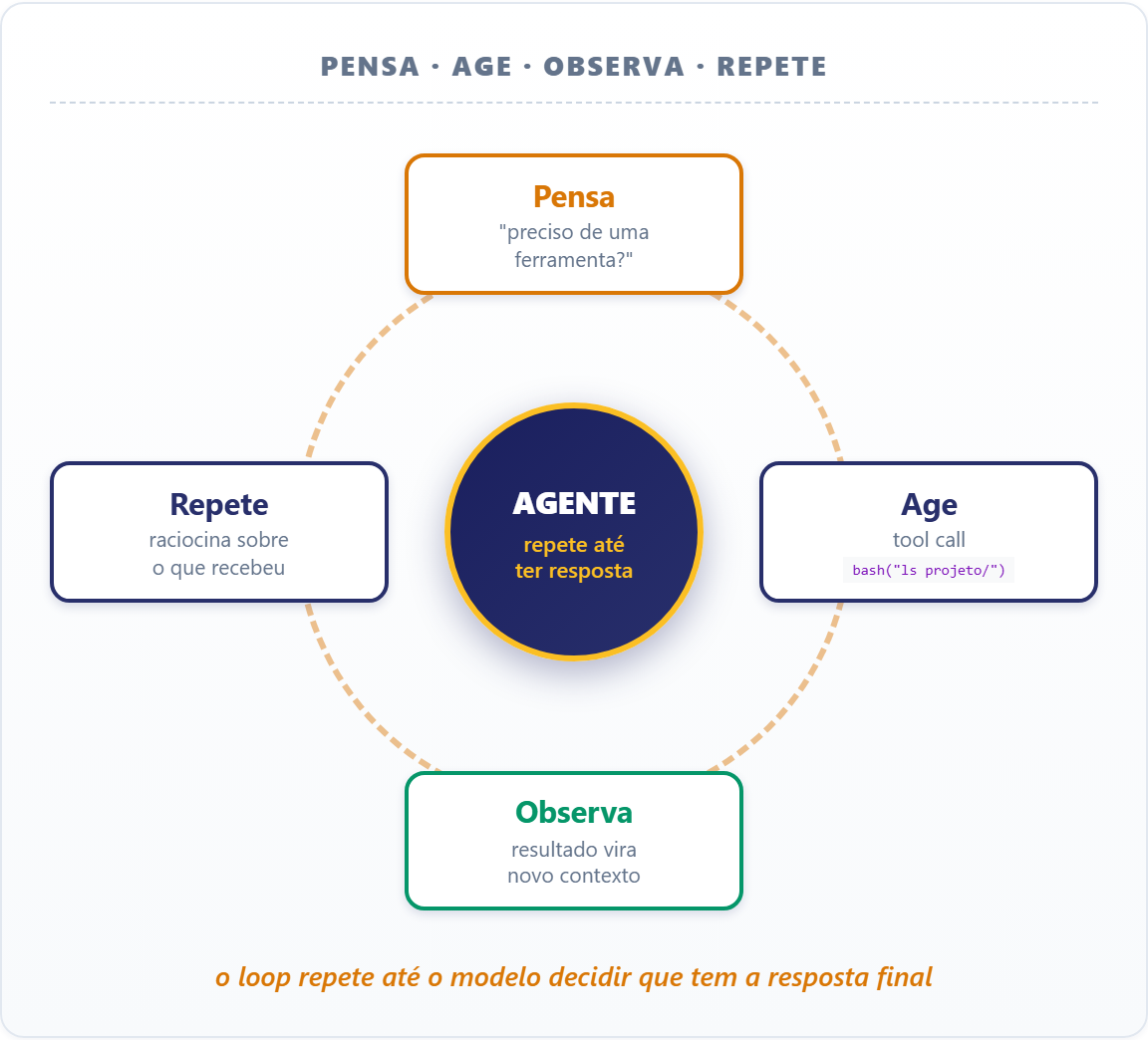
No Claude Code, uma ferramenta é uma tripla: nome, descrição do que faz e esquema dos argumentos. As built-in cobrem o trabalho local (Read lê arquivo, Bash roda comando, Grep busca por texto).
O MCP é o jeito padrão de ensinar ferramentas novas ao agente, ligando serviços como GitHub ou Notion sem integrar código a código. Cada tool call traz dados de volta para o contexto, e é o agente que decide qual chamar a cada turno.
Context engineering: escolher o que entra na janela
As peças se encaixam. O modelo só responde com base no contexto; o conhecimento dele congela no cutoff, então fatos atuais vêm pelo contexto; RAG injeta documentos no contexto; as ferramentas injetam resultados de ação no contexto; a memória persistente injeta conversas anteriores no contexto.
Ao longo de 2024 e 2025, a percepção que se consolidou na prática profissional é que escolher o que entra na janela de contexto a cada chamada é a habilidade central. O ofício ganhou nome próprio: context engineering, e o prompt engineering, que cuida só da última mensagem do usuário, virou um caso particular dele.
A janela funciona como uma pilha de fatias que compete por espaço, e cada chamada monta essa pilha de novo. A do Claude Sonnet hoje vai até 200 mil tokens (1 milhão na variante estendida), o que parece muito até você notar que um repositório médio de código estoura esse limite. Daí o trabalho real, que é decidir o que merece estar lá:
📌
🔍
🗜️
🚫
As alavancas de context engineering no Claude Code
Você provavelmente já usou várias destas sem dar o nome. Cada uma é uma decisão sobre o que entra na janela:
CLAUDE.md— sobe automaticamente como parte do system prompt; é onde você ensina o agente sobre o projeto. Densidade alta vale ouro porque entra em toda chamada.@arquivo— inclusão pontual de conteúdo no contexto da pergunta, mais preciso do que pedir "lê o projeto inteiro"./clear— zera o histórico ao mudar de tarefa, porque manter o que veio antes só polui a previsão de token./compact— resume o histórico em vez de jogar fora, quando você quer continuar mas o contexto começou a apertar.- MCP, skills e subagentes — ampliam as ferramentas e deixam tarefas específicas rodarem com contexto próprio, sem poluir a conversa principal.
Pensar a interação como context engineering muda a pergunta que você faz a si mesmo. Em vez de "como reformulo este prompt", a pergunta passa a ser "o que precisa estar no contexto para a resposta sair certa de primeira?". Quase sempre a resposta envolve colocar menos lixo e a informação certa, não polir a frase final.
O que a prática consolidou
- Prompt mágico não existe. Não há frase secreta que multiplique a inteligência do modelo; a maior parte do ganho vem da qualidade do contexto, não do floreio.
- Janela maior importa menos do que se pensava. Um modelo com 1 milhão de contexto mal-curado responde pior que um com 200 mil bem-curado.
- As ferramentas mudaram o jogo. A maior parte do trabalho útil hoje envolve o modelo agindo — buscando, executando, escrevendo arquivo — e não só respondendo.
- Alucinação não foi resolvida. Foi mitigada por RAG, ferramentas e modelos melhores, mas continua sendo o risco operacional número um em pipelines que dependem de fato.
Perguntas frequentes
O que é context engineering?
É o trabalho de decidir, organizar e otimizar tudo o que o modelo lê antes de responder: instruções do sistema, documentos buscados, histórico relevante, descrições de ferramentas, formato de saída e a pergunta do usuário. Como o modelo só responde com base no que está no contexto, escolher o que entra na janela a cada chamada é o que mais determina a qualidade da resposta.
Qual a diferença entre context engineering e prompt engineering?
Prompt engineering cuida da última mensagem do usuário — como formular a pergunta. Context engineering cuida de tudo o que entra na janela de contexto, sendo o prompt apenas uma das fatias.
A mudança de foco reflete a percepção de que o prompt é um pedaço pequeno do problema: antes dele já há system prompt, ferramentas, documentos buscados e histórico, e é a soma disso que o modelo lê.
Por que o LLM alucina?
Porque ele prevê o token mais provável dada a sequência, em vez de consultar uma base de dados. Quando o fato está fora do conhecimento congelado no treino (knowledge cutoff), é muito específico ou exige um cálculo, o modelo produz texto fluente e confiante que pode estar errado.
A alucinação é estrutural, e a defesa é alimentar o contexto com os fatos certos no momento do pedido, via RAG ou ferramentas.
O que é RAG?
RAG (Retrieval-Augmented Generation) é buscar os documentos relevantes antes de perguntar e colá-los no contexto junto com a pergunta. O modelo responde ancorado nesses trechos em vez de chutar com base na memória. Reduz bastante a alucinação, mas depende da qualidade da busca: trecho errado no contexto vira resposta errada.
Do conceito ao agente que roda no seu projeto
Entender context engineering é o primeiro passo; o seguinte é aplicar — montar o CLAUDE.md certo, ligar os MCPs, desenhar o loop e detectar o erro num agente que trabalha com dados econômicos reais. É isso que a imersão Claude Code para Economistas ensina, da instalação ao agente em produção.
Leia também:

