Uma série temporal é estacionária quando suas propriedades estatísticas — média, variância e a relação entre observações vizinhas — não mudam ao longo do tempo. Esse é o conceito que decide como modelar qualquer série: a maioria dos modelos de previsão só funciona quando a série é estacionária, porque eles supõem que o padrão do passado vai continuar valendo no futuro.
Este guia constrói o conceito do começo: o que é um processo estocástico, os componentes de uma série, os processos que servem de exemplo (ruído branco e passeio aleatório), a definição formal de estacionariedade e como testá-la na prática. No fim, aplicamos os testes a três séries reais da economia brasileira — inflação, juros e câmbio — e mostramos como ler cada resultado.
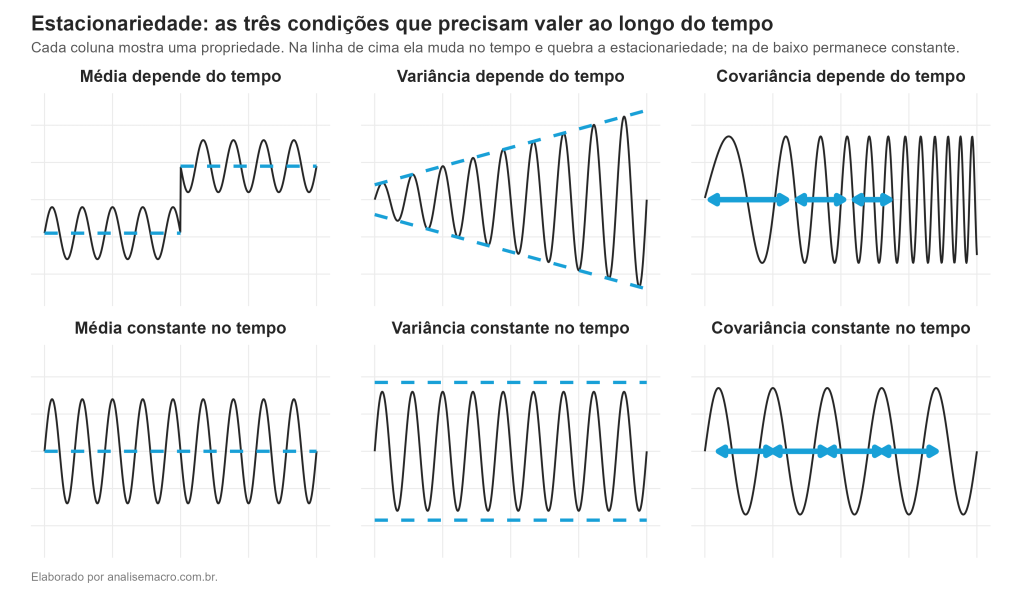
A figura resume o conceito inteiro. Uma série é estacionária só quando os três painéis de baixo valem ao mesmo tempo: o nível médio não sobe nem desce, a dispersão em torno dele não se abre e o ritmo dos ciclos não muda. Basta uma dessas condições falhar, como nos painéis de cima, para a série ser não estacionária.
Receba análises como esta toda semana
O Boletim AM é a newsletter gratuita da Análise Macro. Toda semana, conteúdos sobre economia, séries temporais e análise de dados direto no seu e-mail. Assine e acompanhe.
Processo estocástico: de onde vem uma série temporal
Um processo estocástico é uma coleção de variáveis aleatórias ordenadas no tempo. Cada ponto da série poderia ter assumido outro valor, a depender do ambiente daquele instante, e o que observamos é apenas uma das trajetórias possíveis.
Pense no PIB trimestral. O valor de um trimestre qualquer dependeu do clima econômico e político daquele período; poderia ter sido diferente. A série histórica que temos em mãos é, então, uma realização particular do processo, ou seja, uma amostra. Assim como usamos uma amostra para inferir sobre uma população, aqui usamos a trajetória observada para inferir sobre o processo gerador dos dados que está por trás dela. Esse processo é desconhecido, e todo o trabalho de análise consiste em caracterizá-lo a partir do pouco que conseguimos ver.
Os componentes de uma série temporal
Para entender o processo gerador, é útil separar a série em partes. Cada uma tem um papel próprio, e reconhecê-las já indica se a série tende a ser estacionária.
📈
🗓️
🔄
🎲
Na prática, juntamos tendência e ciclo num componente só e pensamos na série como a soma de três partes. Na decomposição aditiva, escrevemos a série como:
A decomposição aditiva cabe quando a amplitude da sazonalidade não muda com o nível da série. Quando a flutuação sazonal cresce junto com o nível (algo comum em séries econômicas), usa-se a decomposição multiplicativa, em que os componentes se multiplicam em vez de somar:
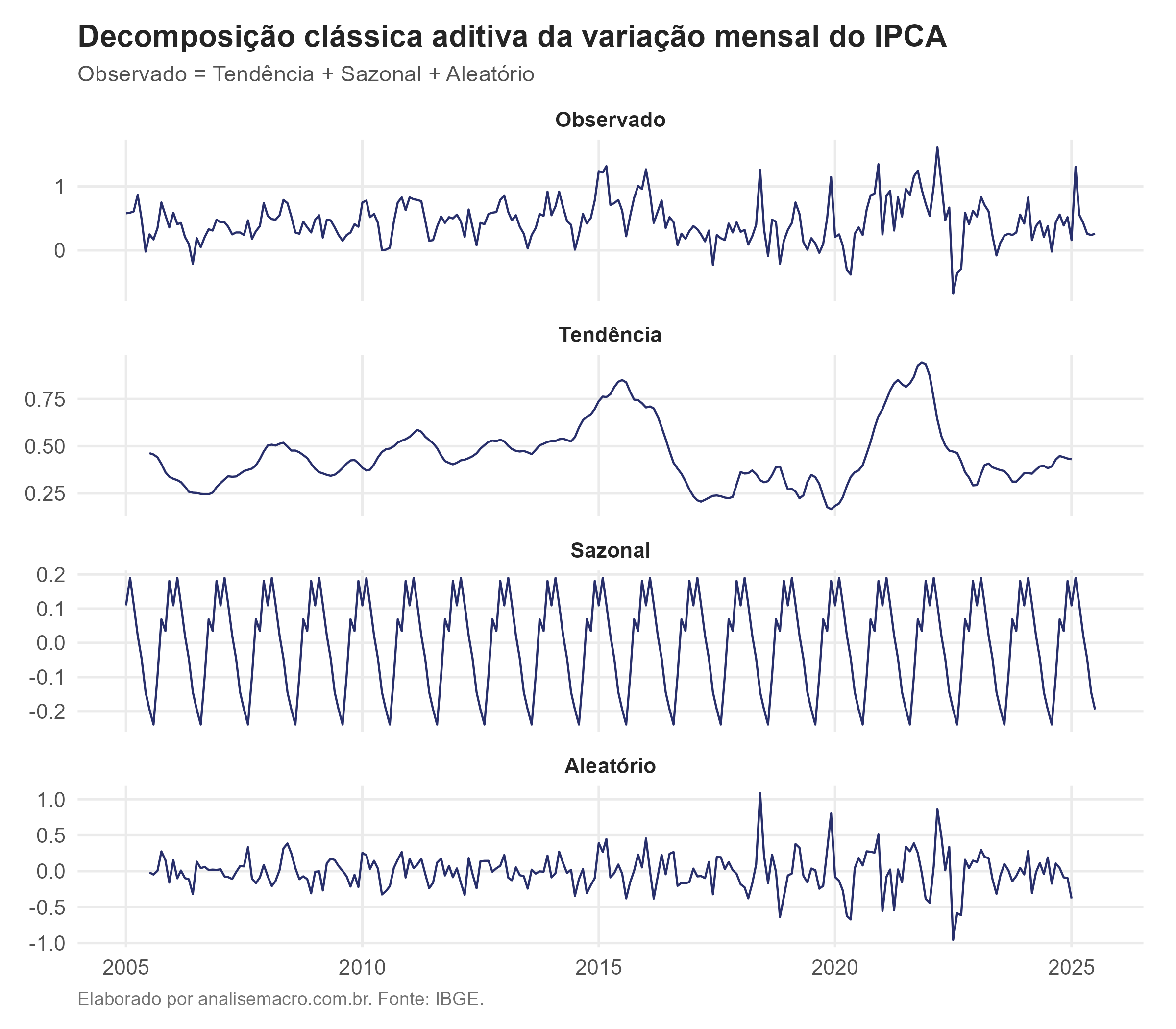
A variação mensal do IPCA separada nos quatro painéis: o observado, a tendência (a inflação "de fundo", filtrada do ruído), o padrão sazonal que se repete todo ano e o resíduo. Repare que a série observada oscila em torno de um nível, sem subir indefinidamente. É uma primeira pista visual de estacionariedade, que os testes vão confirmar mais adiante.
As três funções que descrevem o comportamento
Como raramente observamos muitas trajetórias de uma série econômica, olhamos para três funções que resumem seu comportamento no tempo. São elas que a estacionariedade exige que fiquem constantes.
Com base nessas funções, os processos se dividem em dois tipos. Um processo é estacionário quando as três não mudam com o tempo: a série tem a mesma estrutura estatística em qualquer janela que você observe. É não estacionário quando alguma delas varia, seja por tendência, sazonalidade ou mudança estrutural. Séries não estacionárias são mais difíceis de modelar, porque suas características não param quietas.
Ruído branco: o processo estacionário mais simples
O ruído branco é o exemplo puro de série estacionária. Uma série é ruído branco quando suas observações são independentes, com média zero e variância constante. Em termos de resíduos (a diferença entre o valor observado e o previsto), ele exige três coisas: média zero, sem viés para cima ou para baixo; variância constante, com a dispersão sempre igual; e independência, em que um valor não carrega informação sobre o próximo. Quando a distribuição também é normal, temos ruído branco gaussiano.
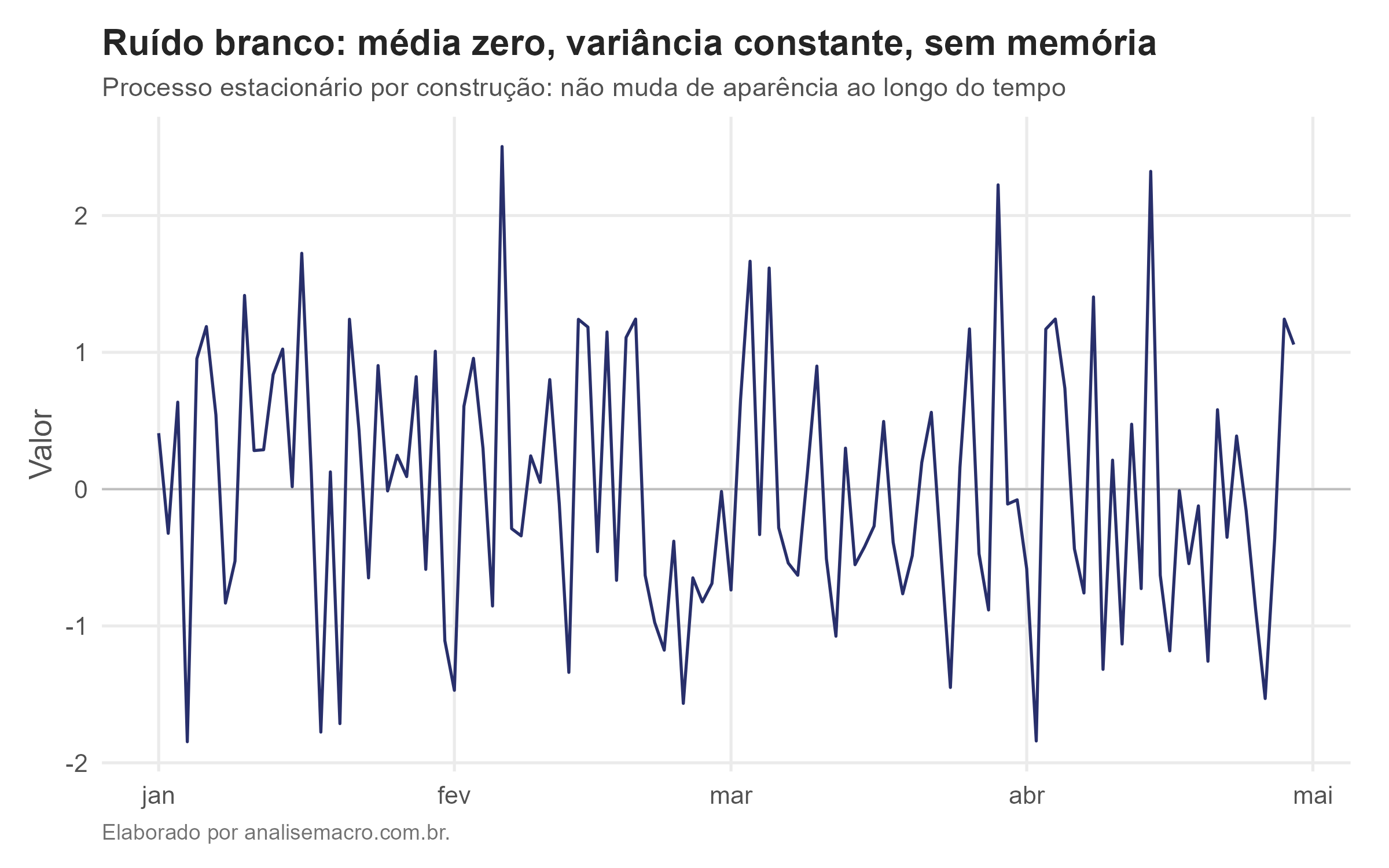
Qualquer trecho da série se parece com qualquer outro: não há tendência, a dispersão é a mesma do início ao fim e nenhum valor prevê o seguinte. É estacionariedade em estado puro.
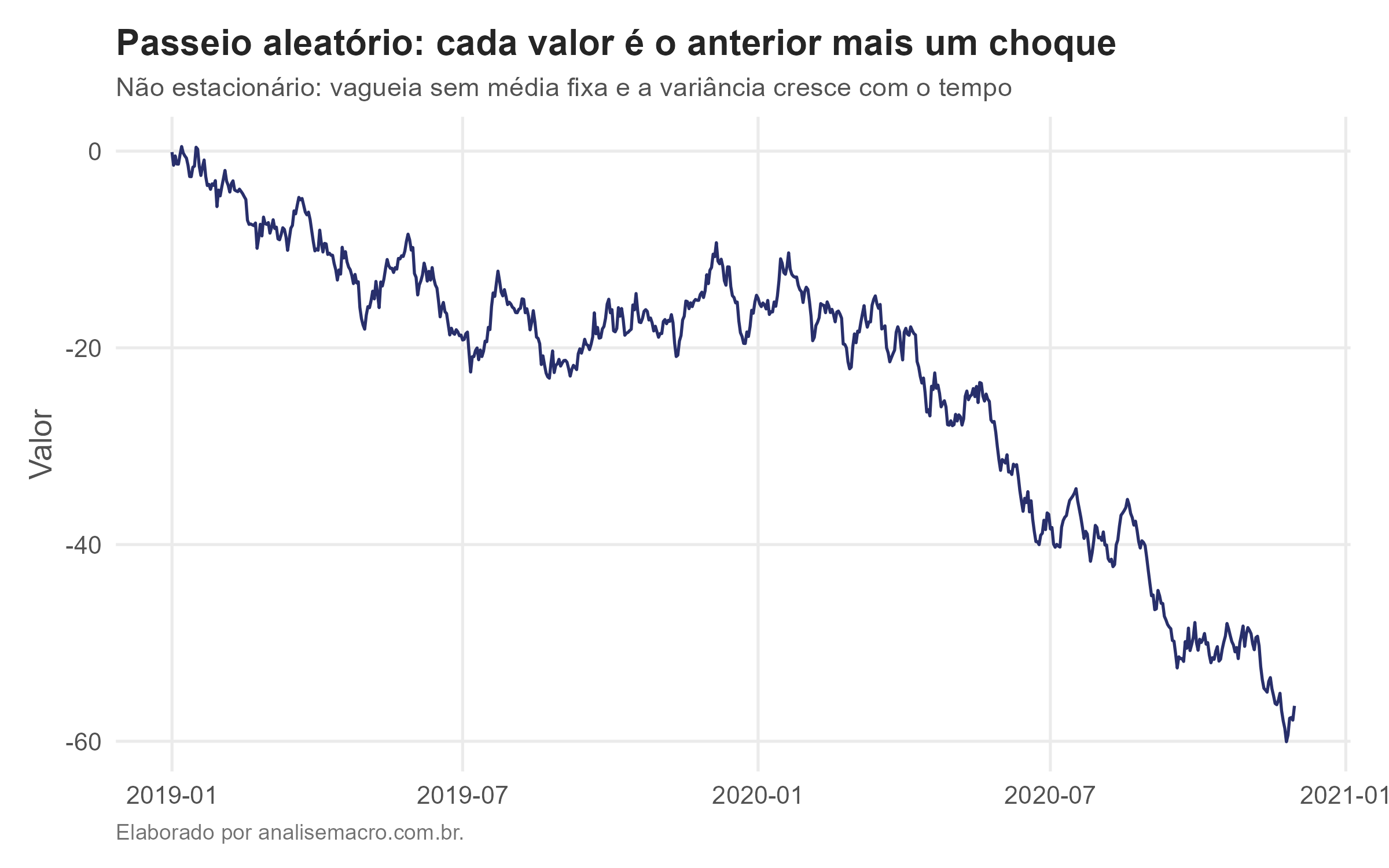
Passeio aleatório: o exemplo canônico de não estacionariedade
O passeio aleatório (random walk) é o oposto. Cada valor é o valor anterior mais um choque aleatório:
Substituindo essa relação para trás, período a período, a série vira a soma acumulada de todos os choques passados:
Isso tem uma consequência decisiva: a variância cresce com o tempo, porque cada novo choque se soma aos anteriores e fica guardado no nível para sempre. A série vagueia sem se prender a uma média fixa. Preços de ações costumam se comportar assim.
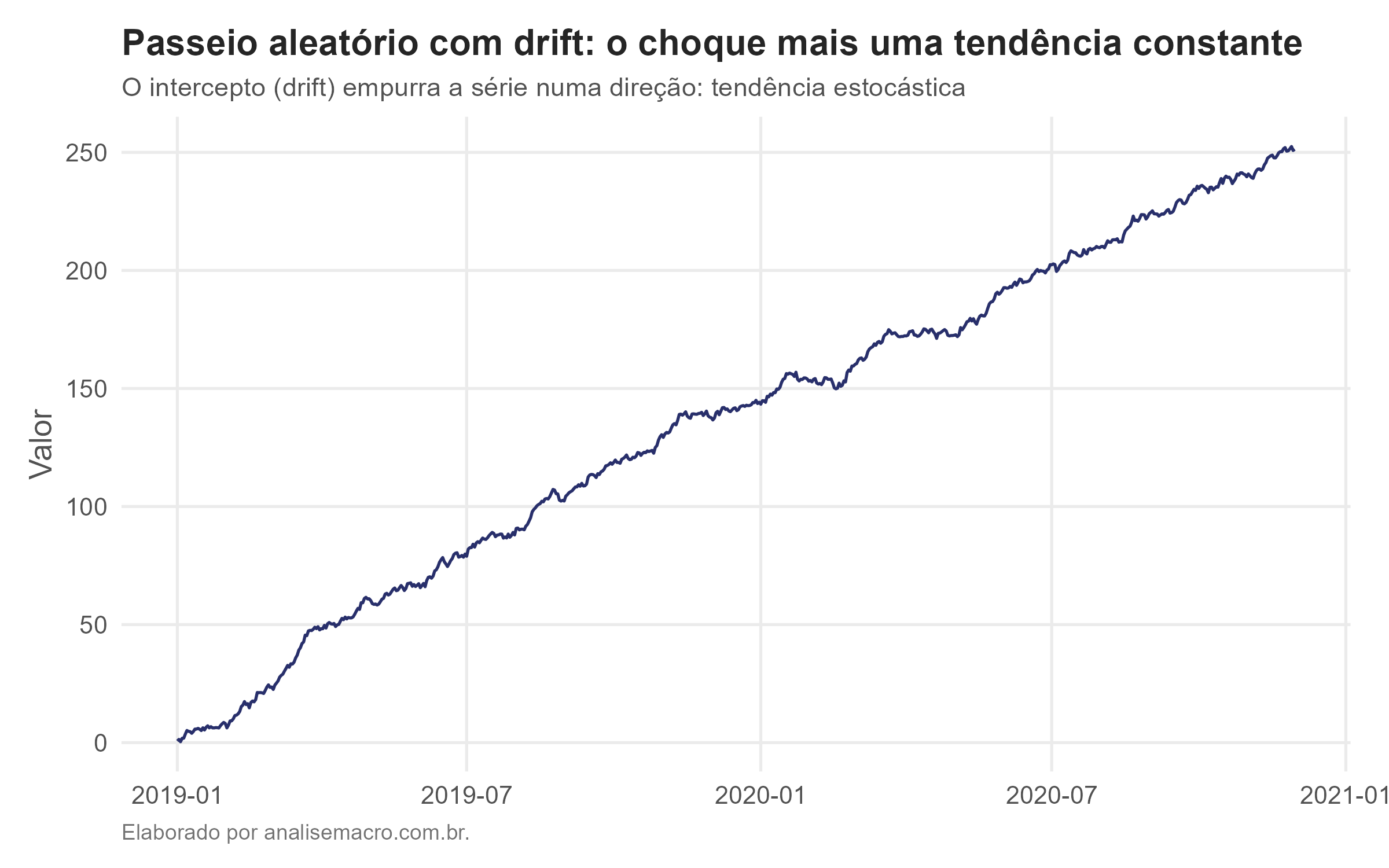
Acrescentar uma constante ao passeio aleatório cria um drift, um empurrão sistemático numa direção:
Agora, além do vaguear aleatório, a série ganha uma tendência. Essa tendência é estocástica: vem da acumulação dos choques mais a constante, não de uma função fixa do tempo. É exatamente esse tipo de comportamento que os testes de raiz unitária foram criados para detectar.
A definição de estacionariedade
Uma série temporal é estacionária (no sentido amplo) quando suas propriedades estatísticas independem do momento em que a série é observada. Três condições precisam valer ao longo de todo o tempo:
- Média constante. O nível médio não sobe nem desce ao longo da série.
- Variância constante. A dispersão em torno da média não se abre nem se fecha com o tempo.
- Covariância independente do tempo. A relação entre duas observações depende só da distância entre elas, não de onde estão na série.
Existe também a estacionariedade estrita, que exige que amostras de mesmo tamanho tenham distribuições idênticas. Como é uma condição restritiva e rara, na prática trabalhamos com a estacionariedade no sentido amplo. Séries com tendência ou sazonalidade não são estacionárias; o ruído branco é. Já uma série cíclica sem período fixo pode ser estacionária, porque, sem saber onde ficarão os próximos picos e vales, não há padrão previsível de longo prazo.
Como verificar a estacionariedade
Há duas abordagens: uma visual e uma estatística.
A abordagem visual divide a série mentalmente ao meio e compara as duas metades. Se a média, a amplitude e o comprimento dos ciclos forem parecidos na primeira e na segunda metade, a série tem cara de estacionária. Serve como primeiro filtro, mas é subjetiva.
A abordagem estatística usa testes de raiz unitária. Uma raiz unitária é justamente uma tendência estocástica: o passeio aleatório é o caso típico. A presença de raiz unitária indica série não estacionária; a ausência, série estacionária. O teste confronta duas hipóteses e decide entre elas por dois caminhos: o valor-p, que se compara ao nível de significância de 5%, e o valor crítico, em que a estatística de teste é comparada a um valor de referência. O valor crítico ajuda quando o valor-p fica na fronteira.
O teste ADF: como funciona e como ler
No teste de Dickey-Fuller Aumentado (ADF), a hipótese nula é de que a série tem raiz unitária, ou seja, é não estacionária. Rejeitar a nula é a boa notícia: significa concluir pela estacionariedade.
- Hipótese nula (H0): a série tem raiz unitária (não estacionária).
- Hipótese alternativa (H1): a série não tem raiz unitária (estacionária).
- Como ler: a estatística do ADF é negativa. Quanto mais negativa ela for, ou seja, mais abaixo do valor crítico, mais forte a evidência a favor da estacionariedade. Se a estatística fica abaixo do valor crítico (ou o valor-p ≤ 0,05), rejeita-se H0 e a série passa como estacionária.
O teste KPSS: a hipótese nula invertida
No teste KPSS (Kwiatkowski–Phillips–Schmidt–Shin), a hipótese nula é o oposto da do ADF: parte de que a série é estacionária. Aqui, rejeitar a nula é a má notícia: significa concluir pela não estacionariedade.
- Hipótese nula (H0): a série é estacionária.
- Hipótese alternativa (H1): a série não é estacionária.
- Como ler: a estatística do KPSS é positiva. Se ela fica acima do valor crítico (valor-p ≤ 0,05), rejeita-se H0 e a série é considerada não estacionária. Se fica abaixo do valor crítico, não se rejeita, e a série passa como estacionária.
O detalhe que mais confunde é este: como as hipóteses nulas são espelhadas, a mesma regra de "rejeitar quando o valor-p é baixo" leva a conclusões opostas nos dois testes. Por isso ADF e KPSS são usados em conjunto. O resultado mais confiável aparece quando os dois concordam: o ADF rejeitando a raiz unitária e o KPSS não rejeitando a estacionariedade apontam, juntos, para uma série estacionária.
Testando três séries da economia brasileira
Para fixar a leitura dos testes, aplicamos ADF e KPSS a três séries com comportamentos bem diferentes: a variação mensal do IPCA, a taxa Selic e o câmbio (reais por dólar), de 2005 a 2025. Os dados vêm do Banco Central do Brasil.
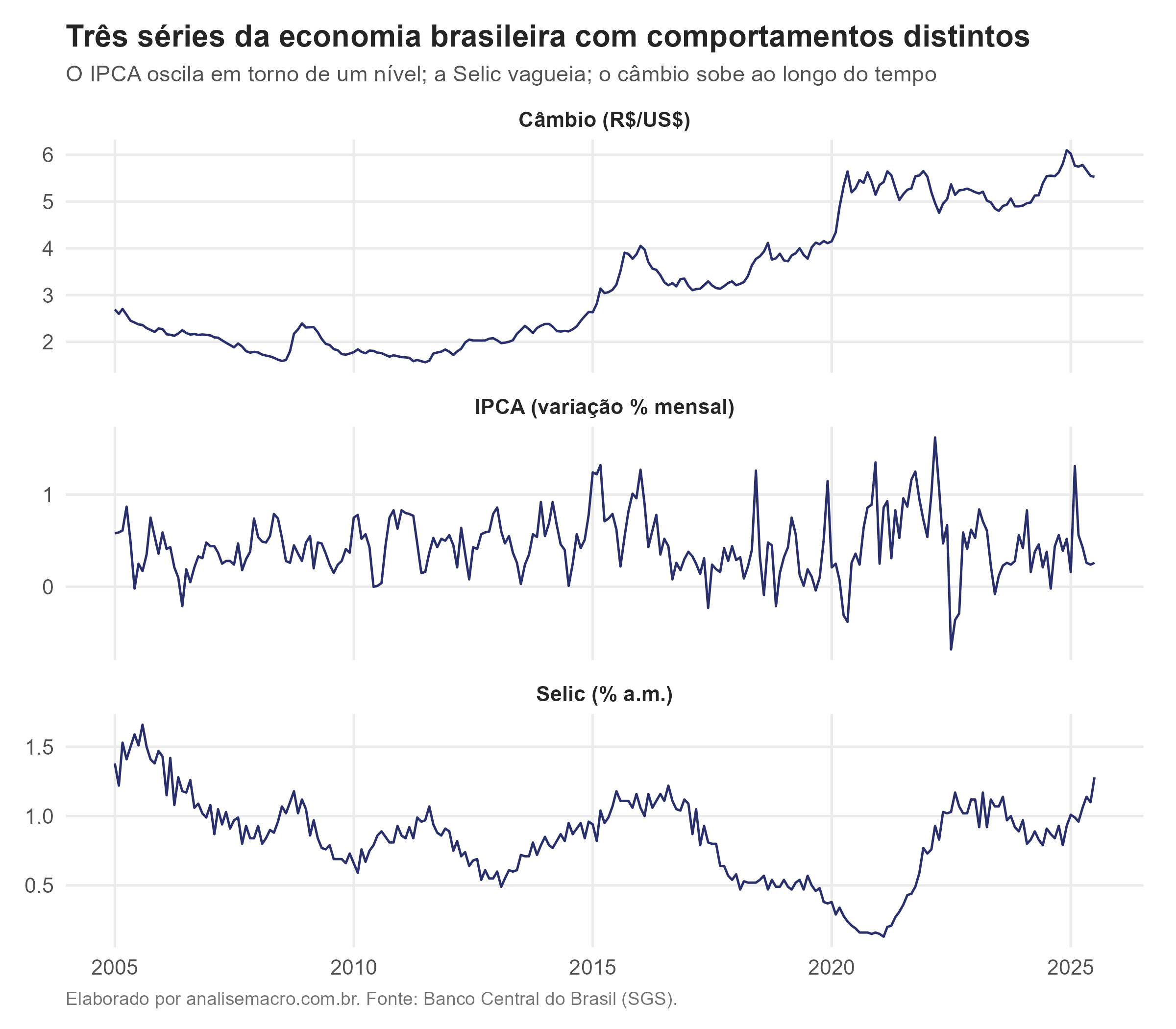
O gráfico já antecipa a resposta. O câmbio sobe ao longo do período, com uma tendência clara de alta. O IPCA fica preso a um nível baixo, oscilando sem rumo definido. A Selic vagueia lentamente, com trechos longos acima e abaixo. A intuição diz: IPCA estacionário, câmbio e Selic não. Agora confirmamos com os números.
Lendo a tabela de resultados
A tabela reúne as estatísticas dos dois testes para cada série. Lembre da regra de leitura: no ADF, estatística mais negativa que o valor crítico indica estacionariedade; no KPSS, estatística abaixo do valor crítico indica estacionariedade.
| Série | ADF (estatística) | Crítico 5% (ADF) | KPSS (estatística) | Crítico 5% (KPSS) | Veredito |
|---|---|---|---|---|---|
| IPCA | −6,97 | −2,88 | 0,10 | 0,463 | Estacionária |
| Selic | −1,54 | −2,88 | 0,93 | 0,463 | Não estacionária |
| Câmbio | −0,30 | −2,88 | 3,70 | 0,146 | Não estacionária |
Testes ADF e KPSS, séries de 2005 a 2025. Fonte: Banco Central do Brasil.
Agora a leitura, série por série:
- IPCA — estacionária. O ADF dá −6,97, bem abaixo do crítico de −2,88, então rejeita a raiz unitária. O KPSS dá 0,10, abaixo de 0,463, então não rejeita a estacionariedade. Os dois testes concordam.
- Selic — não estacionária. O ADF dá −1,54, acima de −2,88, então não rejeita a raiz unitária. O KPSS dá 0,93, acima de 0,463, então rejeita a estacionariedade. Os dois concordam no sentido oposto.
- Câmbio — não estacionária. O ADF dá −0,30, muito acima do crítico, então não rejeita a raiz unitária. O KPSS dá 3,70, muito acima de 0,146, e rejeita com folga. É o caso mais nítido de não estacionariedade, coerente com a tendência de alta no gráfico.
E o que fazer com uma série não estacionária? Em geral, diferenciá-la: em vez de modelar o nível, modelar a variação de um período para o outro. O câmbio em nível é não estacionário, mas a variação mensal do câmbio já passa nos testes. É por isso que tantos modelos econômicos trabalham com variações (retornos, taxas de crescimento) em vez de níveis.
Considerações finais
A estacionariedade é o conceito que decide como tratar uma série temporal antes de qualquer modelo. Verificar se média, variância e covariância ficam constantes no tempo, e testar isso com ADF e KPSS lidos em conjunto, é o passo que define se você modela a série em nível ou precisa diferenciá-la primeiro. Errar aqui compromete toda a previsão que vem depois.
O alcance vai além deste exemplo. O mesmo raciocínio — reconhecer os componentes, checar as condições, testar a raiz unitária — se repete em quase todo problema de análise de séries econômicas e financeiras. O que muda é a aplicação por área:
- Economista e analista macro: tratar PIB, inflação e juros antes de estimar modelos de previsão e relações de longo prazo.
- Analista de mercado e trader: distinguir uma série que reverte à média de uma que segue passeio aleatório, o que muda toda a estratégia.
- Gestor de risco e atuário: modelar volatilidade e retornos, que exigem séries estacionárias para estimativas confiáveis.
- Cientista de dados: preparar séries para modelos de previsão, em que a estacionariedade é pré-requisito de boa parte deles.
Dominar o conceito e os testes é o que sustenta todo o restante da análise de séries temporais.
Aprenda análise de dados econômicos do zero
Você viu o conceito de estacionariedade e como testá-lo. Para aprender a fazer isso na prática, do zero, a Análise Macro tem a formação Do Zero à Análise de Dados Econômicos e Financeiros, disponível nas duas linguagens mais usadas na área — Python e R. Quem quer acesso a todas as formações tem o AM Black, a assinatura anual.
Leia também:

