1 Introdução
1.1 Por que automatizar análises econômicas?
Quase todo economista aplicado convive com a mesma rotina: a cada divulgação do IBGE, do BCB ou do FRED, é preciso atualizar boletins, revisar números, recalcular indicadores e reenviar relatórios. Muitos desses processos envolvem abrir um script antigo, ajustar datas, rodar código, exportar gráficos, copiar valores para um documento e publicar.
Esse trabalho repetitivo tem três problemas:
- É lento — cada divulgação consome horas que poderiam ir para análise.
- É frágil — scripts esquecidos quebram quando pacotes são atualizados ou APIs mudam de formato.
- É difícil de reproduzir — ao passar o trabalho para outro pessoa (ou para você mesmo meses depois), falta contexto.
Uma análise automatizada resolve isso: um único comando baixa dados, trata, gera visualizações e produz o relatório final. Feito com cuidado, o fluxo é reproduzível, documentado e estável ao longo do tempo.
1.2 O que muda com o Claude Code
Na aula anterior vimos que o Claude Code opera dentro do seu projeto: ele lê arquivos, executa comandos e modifica código com contexto completo. Para análises econômicas isso se traduz em três ganhos concretos:
- Menor custo para escrever pipelines reproduzíveis — o agente sabe estruturar um projeto Quarto, separar coleta de tratamento, escrever funções com docstrings e gerar
.gitignoreadequado. - Iteração rápida em visualizações — ajustar cores, escalas, temas e anotações de gráficos vira uma conversa.
- Documentação junto com o código — narrativa econômica e scripts vivem no mesmo arquivo
.qmd.
Dica: quanto mais explícito você for sobre fontes de dados, séries, transformações e formato de saída, mais eficiente será o Claude Code. Um CLAUDE.md bem escrito substitui dezenas de prompts ao longo da semana.
2 O fluxo de uma análise automática
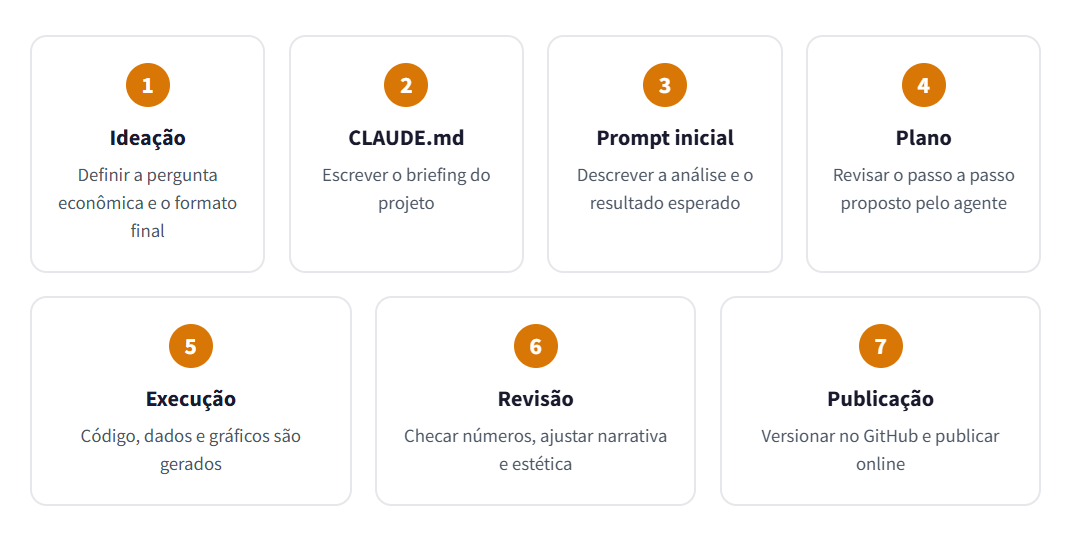
Antes de entrar no passo a passo do relatório do IPCA, vale fixar o fluxo geral de uma análise feita com o Claude Code. Ele tem sete etapas:
3 Estrutura de um projeto de análise reproduzível
Projetos que o Claude Code entende bem são projetos organizados de forma previsível. Uma separação simples entre coleta, tratamento, visualização e relatório já traz ganhos relevantes.
meu-projeto/
├── CLAUDE.md ← briefing automático do agente
├── _quarto.yml ← config do projeto Quarto
├── relatorio.qmd ← documento final com narrativa
├── R/
│ ├── coleta.R ← funções de download (BCB, IBGE, FRED)
│ ├── tratamento.R ← limpeza, acumulados, sazonalidade
│ └── graficos.R ← funções ggplot2 reutilizáveis
├── output/ ← HTML e imagens geradas
├── .gitignore
└── README.mdEssa estrutura traz quatro benefícios para o trabalho com IA:
- Contexto direcionado com @-mentions — você pode pedir “atualize apenas
@R/graficos.R” sem envolver o pipeline inteiro. - Menor consumo de tokens — o agente não precisa ler tudo em cada prompt.
- Trocas de linguagem fáceis — se amanhã você quiser migrar gráficos para Python, só a pasta
R/precisa mudar. - Git amigável — diffs pequenos e revisões mais claras.
coleta.R começar a desenhar gráficos, peça ao Claude para refatorar.4 CLAUDE.md para análises recorrentes
Na aula 01 vimos o CLAUDE.md como memória persistente. Em análises recorrentes ele ganha um papel ainda mais importante: evitar que cada rodada comece do zero.
Um bom CLAUDE.md para um projeto de análise contém:
- Objetivo do relatório — o que ele responde e para quem
- Periodicidade — mensal, trimestral, ad-hoc
- Fontes e séries — códigos exatos (IBGE/SIDRA, BCB/SGS, FRED)
- Transformações padrão — acumulado em 12 meses, dessazonalização, variação real
- Convenções visuais — cores da marca, escalas, fontes
- Formato de saída — Quarto HTML, PDF, slides
- Regras e não-fazer — nunca commitar dados brutos, nunca alterar séries históricas
Esse arquivo encurta o prompt inicial e, principalmente, reduz drasticamente o esforço de cada atualização mensal: você só pede “atualize o relatório com os dados mais recentes e comente o que chamou atenção”.
5 Padrões de prompt para análises
Alguns padrões são especialmente eficazes quando o objetivo é gerar análises econômicas:
Padrão 1 — Coleta estruturada
“Crie uma função
coletar_ipca_mensal()em R que baixa a série 433 do SGS/BCB usando o pacoterbcb, a partir de 2000. Retorne um tibble com colunasdata(Date) eipca_mm(numérico, em %).”
Padrão 2 — Transformação econômica
“Na tabela
ipca, calcule o acumulado em 12 meses pela regra do produtório:prod(1 + x/100) - 1. PreserveNAnas primeiras 11 observações.”
Padrão 3 — Visualização com identidade
“Gere um gráfico
ggplot2do IPCA acumulado em 12 meses com: linha principal azul-marinho (#282f6b), meta de 3% em verde tracejado, bandas de tolerância em cinza claro, tematheme_minimal(), título em negrito e fonte ‘BCB/SGS’ no rodapé.”
Padrão 4 — Relatório Quarto
“Monte um
relatorio_ipca.qmdcom YAML para HTML, chunkssetup,coleta,tratamentoe seções com gráficos intercalados por narrativa de 3-4 parágrafos cada. Useexecute: freeze: autopara não rebaixar a cada render.”
6 Passo a passo: Relatório do IPCA em Quarto
Esta seção apresenta a aplicação prática dos conceitos. O objetivo é construir um relatório mensal do IPCA em formato Quarto HTML, gerado com o auxílio do Claude Code, versionado no GitHub e publicado online na Posit Connect Cloud.
6.1 Passo 1 — Instalar o Quarto
O Quarto é uma ferramenta de publicação científica que gera HTML, PDF, Word e slides a partir de arquivos .qmd. Instalação:
- Baixe o instalador em https://quarto.org/docs/get-started/
- Instale seguindo o fluxo do seu sistema operacional
- No terminal, verifique:
quarto --versionNo VS Code, instale também a extensão Quarto (da editora “quarto-dev”) para ter highlight, preview e atalho de render com Ctrl+Shift+K.
Linguagem da análise: nesta aula usaremos R (com tidyverse, ggplot2, rbcb, sidrar). O mesmo fluxo funciona em Python — basta trocar os blocos e pacotes equivalentes.
6.2 Passo 2 — Criar a estrutura do projeto
Crie uma pasta vazia para o projeto e abra no VS Code.
6.3 Passo 3 — Escrever o CLAUDE.md real
Crie o arquivo CLAUDE.md com o conteúdo específico do projeto (caso já tenha um projeto com arquivos, use /init). Um exemplo que funciona bem:
# CLAUDE.md — Relatório Mensal do IPCA
## Objetivo
Produzir um relatório Quarto (.qmd) com análise do IPCA do Brasil, atualizado
mensalmente, publicado online via Posit Connect Cloud.
## Fontes e séries
- IPCA mensal: série 433 do SGS/BCB (via pacote `rbcb`)
- Meta de inflação: série 13521 do SGS/BCB
- IPCA por grupos: tabela 7060 do SIDRA/IBGE (via pacote `sidrar`)
## Estrutura do projeto
- `R/coleta.R` — funções de download
- `R/tratamento.R` — transformações (acumulados, contribuições, sazonal)
- `R/graficos.R` — funções ggplot2 reutilizáveis
- `relatorio_ipca.qmd` — relatório final com narrativa
## Convenções
- Nomes em snake_case, textos em português do Brasil
- Gráficos com título, subtítulo e fonte no rodapé
- Cor principal: #282f6b (azul Análise Macro)
- Meta de inflação: linha verde tracejada em 3%
## O que o relatório deve conter
- Panorama do IPCA mensal e acumulado em 12 meses
- Comparação com a meta e bandas de tolerância desde 2018
- Sazonalidade: variação mensal média por mês do ano
- Contribuição dos grupos na última leitura
- Interpretação curta ao longo do relatório
## Regras
- NUNCA commitar dados brutos em data/raw/
- NUNCA alterar séries históricas manualmente
- SEMPRE renderizar via `quarto render` antes de commitSalve. A cada nova sessão do Claude Code este arquivo será lido automaticamente.
6.4 Passo 4 — Prompt 1: Coleta de dados
Crie o arquivo R/coleta.R com três funções:
- coletar_ipca_mensal(inicio = "2000-01-01"): baixa a série 433 do SGS/BCB
via pacote rbcb e retorna um tibble com colunas data (Date) e ipca_mm
(numérico, em %).- coletar_meta_inflacao(): baixa a série 13521 do SGS/BCB e retorna tibble
com colunas data e meta.- coletar_ipca_grupos(): baixa a tabela 7060 do SIDRA/IBGE usando
sidrar::get_sidra() em DUAS chamadas separadas — uma para variação
(variável 63) e outra para peso mensal (variável 66). Em ambas as
chamadas, restrinja a classificação c315 aos 9 códigos dos grupos
do IPCA: 7170 (Alimentação e bebidas), 7445 (Habitação), 7486
(Artigos de residência), 7558 (Vestuário), 7625 (Transportes),
7660 (Saúde e cuidados pessoais), 7712 (Despesas pessoais), 7766
(Educação), 7786 (Comunicação). Junte os dois resultados em um
único tibble tidy (long) com colunas: data (Date), grupo (chr),
variacao (num, %), peso (num, %). NÃO filtre pelo mês mais recente
aqui — a função retorna a série histórica completa; o filtro por
mês é feito no tratamento. Use parse_date() no código da coluna
"Mês (Código)" com formato "%Y%m".Inclua roxygen-style docstrings em português. No fim do arquivo, NÃO execute
nada — o relatório chama as funções.
O Claude vai propor um plano (com Plan Mode ativo) ou executar direto. Revise, aceite as permissões para criar o arquivo e confira o conteúdo.
coletar_ipca_grupos() retornou tibble vazio. Investigue e ajuste."6.5 Passo 5 — Prompt 2: Tratamento
Com a coleta pronta, peça os cálculos: