Expectativas ancoradas, significando a manutenção da inflação em torno de um valor próximo da meta, inclusive após a ocorrência de choques relevantes, tornam menos custosa a ação do Banco Central no combate a pressões inflacionárias. No post de hoje, verificamos a ancoragem de expectativas para diferentes horizontes utilizando o Python como ferramenta para a construção do exercício.
O Boletim Focus permite extrair as expectativas de agentes para diferentes horizontes de diferentes indicadores, incluindo o IPCA, medida oficial de inflação no Brasil. A cada período de tempo, os agentes divulgam os valores que entendem que será o indicador no futuro em diferentes horizontes, e que tal valor, obviamente se altera, devido a mudanças de condições da economia.
Expectativas Ancoradas significam que o valor dessas expectativas estejam, no horizonte relevante, próximo da meta de inflação ou mesmo constantes durante o período de referência, principalmente a do ano corrente, que tem efeito sobre os horizonte futuros. Entretanto, quando há a ocorrência de mudanças súbitas nos valores das expectativas de IPCA, temos portanto, surpresas inflacionárias, e consequentemente a desancoragem de expectativas.
Para estimar uma medida de sensibilidade a surpresas inflacionárias, devemos verificar o impacto que variações nas expectativas para o ano corrente provocam sobre as expectativas para prazos mais longos. Na presença de expectativas bem ancoradas, deve haver baixa relação (co-movimento) entre as expectativas de inflação de longo prazo e as de curto prazo, em que estas últimas capturariam surpresas inflacionárias.
Em termos econométricos, essa sensibilidade é calculada a partir do coeficiente  , de acordo com a equação abaixo:
, de acordo com a equação abaixo:
![\[\Delta \pi_t^{e,h} = \alpha + \beta^h \Delta \pi_t^{e,0} + \epsilon_t\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-5dede8263757ecc4f9295e8018b8912e_l3.png "Rendered by QuickLaTeX.com")
onde  é o horizonte (em anos) para o qual foram formadas as expectativas.
é o horizonte (em anos) para o qual foram formadas as expectativas.
Portanto, quanto maior o coeficiente menos ancoradas as expectativas, ou seja, maior a resposta das expectativas de longo prazo a surpresas inflacionárias. Como o interesse é na evolução deste coeficiente ao longo do tempo, as estimações são realizadas a partir de janelas móveis de 60 meses.
Construção do modelo econométrico no Python
Para a construção do exercício utilizamos o Python, seguindo etapas relativas ao processo de análise de dados. Estas etapas são:
1. Carregamento das bibliotecas do Python;
2. Coleta e tratamento dos dados das expectativas de inflação anuais;
3. Especificação e ajuste do modelo econométrico em janelas deslizantes de 60 meses;
4. Visualização do coeficiente extraído do modelo.
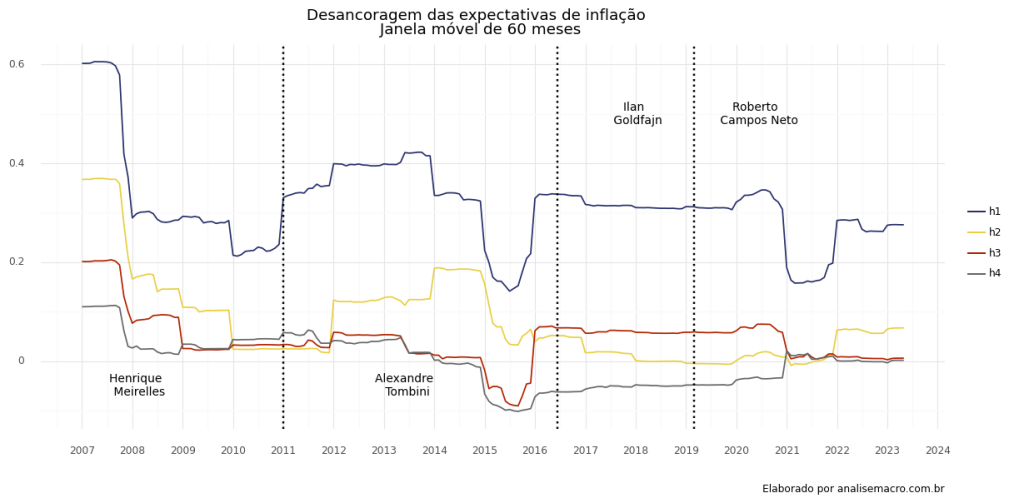
A partir das etapas acima, temos como resultado o gráfico abaixo, que demonstra o coeficiente estimado, ou seja, medida de sensibilidade a surpresas inflacionárias.
Veja que para facilitar o entendimento das surpresas, foi extraído o coeficiente para diferentes horizontes, bem como foi elencado no gráfico os mandatos de cada presidente do Banco Central após 2007: Henrique Meirelles, Tombini, Ilan Goldafajn e RCN, permitindo a comparação e o entendimento da ancoragem em diferentes períodos.
A partir dos resultados, é possível realizar a análise que se deseja para diferentes horizontes e tomar conclusões sobre os acontecimentos da conjuntura do período, bem como as decisões dos presidentes na época.
_____________________________________
Quer aprender mais?
Seja um aluno da nossa trilha de Macroeconomia Aplicada e aprenda a criar projetos voltados para a Macroeconomia.

