A coleta de dados constitui em uma importante etapa do processo de análise de dados, incluindo dados financeiros. Além da possibilidade de coletar dados, vejamos como uma simples aplicação construída no Python pode nos auxiliar a analisar os preços de ativos listados na bolsa de valores.
A coleta/importação de dados é a primeira etapa do processo de análise de dados e para obtê-los existem diversas fontes e instituições que os disponibilizam e que podem ser coletados via Web Scrapping, downloads de arquivos .csv, .xlsm, .tsv, conexão com APIs e diversas outras formas.
E se estamos no contexto de analisar variáveis financeiras, é necessário conhecer os principais métodos de extração de dados.
Com o uso do Python, é possível retirar esses dados rapidamente, de forma relativamente simples, por meio das bibliotecas pandas-datareader e yfinance.
A biblioteca pandas-datareader é uma biblioteca do Python criada com o propósito de importar dados de diversas fontes por meio do pandas. Entre as fontes mais conhecidas:
- Tiingo
- Alpha Vantage
- Quandl
- St.Louis FED (FRED)
- World Bank
- OECD
- Yahoo Finance
E a biblioteca yfinance é conhecida por permitir o acesso a dados da API do Yahoo Finance.
Agora que entendemos as fontes e as bibliotecas que serão utilizadas, vamos entender como funciona a operacionalização da extração por meio do Yahoo Finance.
Para obter os dados é necessário conhecer o ticker da empresa que se deseja obter os dados. Esse ticker é conhecido como o código da ação listada na bolsa de valores, definida de acordo com quatro letra, usualmente referenciando uma abreviação do nome da companhia e mais um número, este de acordo com o tipo da ação (3 para ações ordinárias e 4 para ações preferenciais). Outro ponto importante reside no fato de que índices usualmente não possuem números, bem como utilizar o símbolo ^ no início do código.
Exemplo:
- VALE3
- PETR4
- ^BVSP
Esses tickers são obtidos por meio do site do Yahoo Finance por meio da barra de pesquisa e na página do ativo. Uma vez encontrado a página, é possível obter todos os dados da mesma. E o ticker? Ele é obtido de acordo com a imagem abaixo, após o nome da companhia, com o código PETR4.SA.
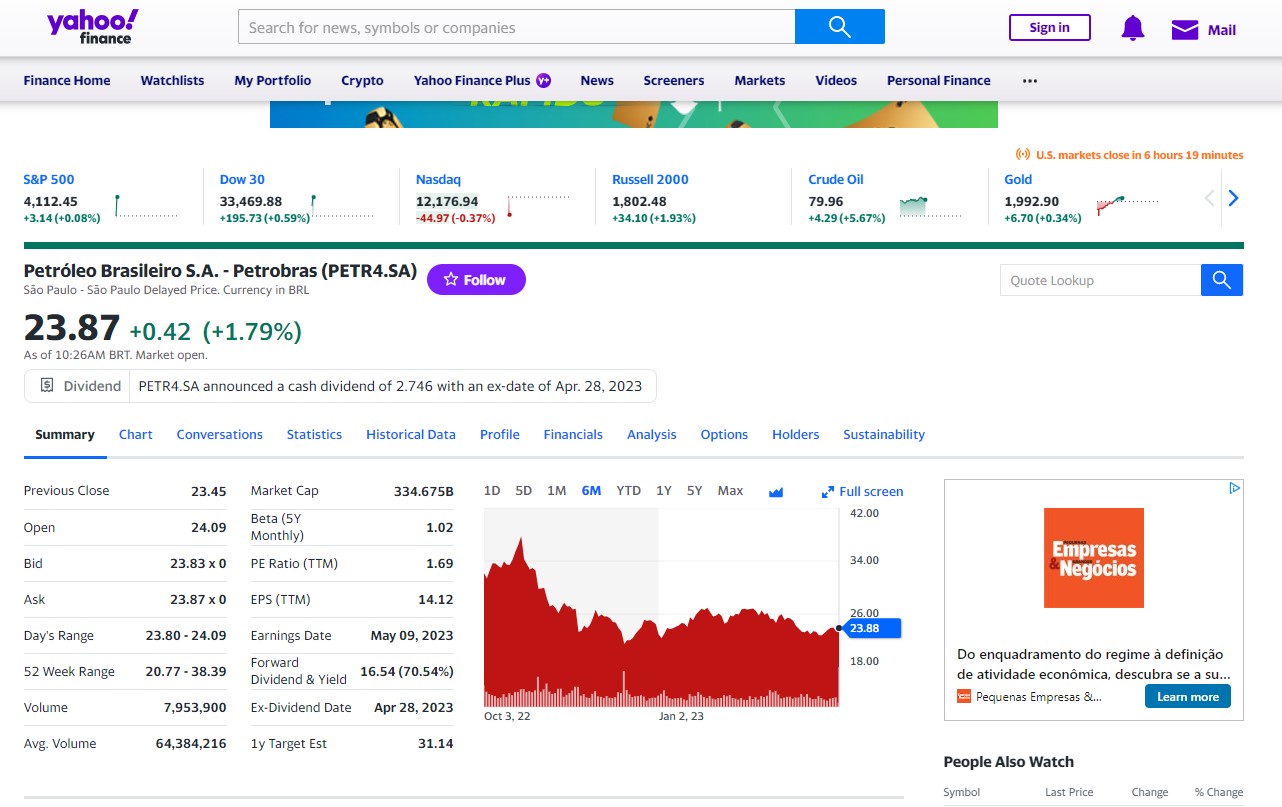
E o que é o padrão OHLC?
O padrão OHLC refere-se as palavras Open, High, Low, Close (Preço de abertura, preço máximo, preço mínimo e preço de fechamento do dia). Além dessas três variáveis, também são importados os dados de fechamento ajustado por eventos corporativos (dividendos, juros sobre capital próprio, split, inplits), Adj Close e o Volume, que refere-se ao volume de contratos transacionados no dia.
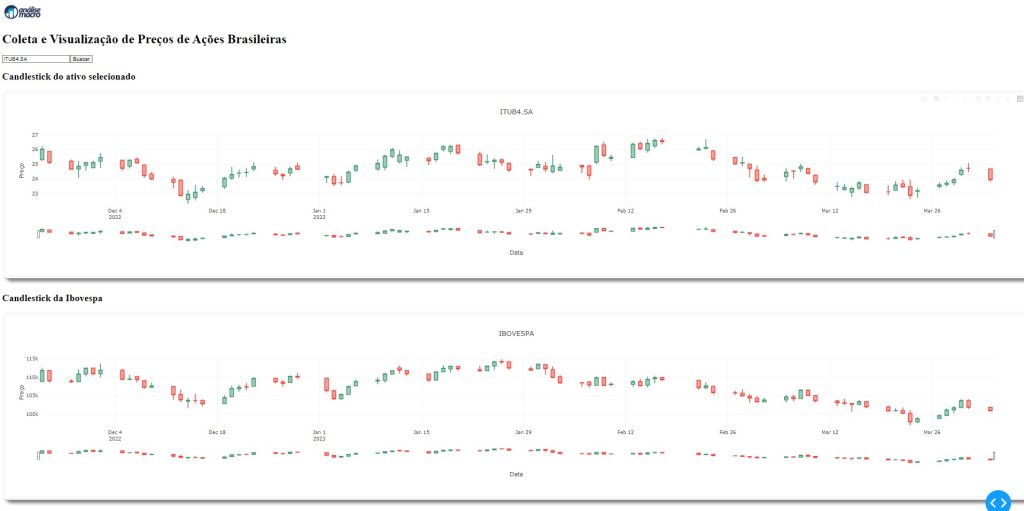
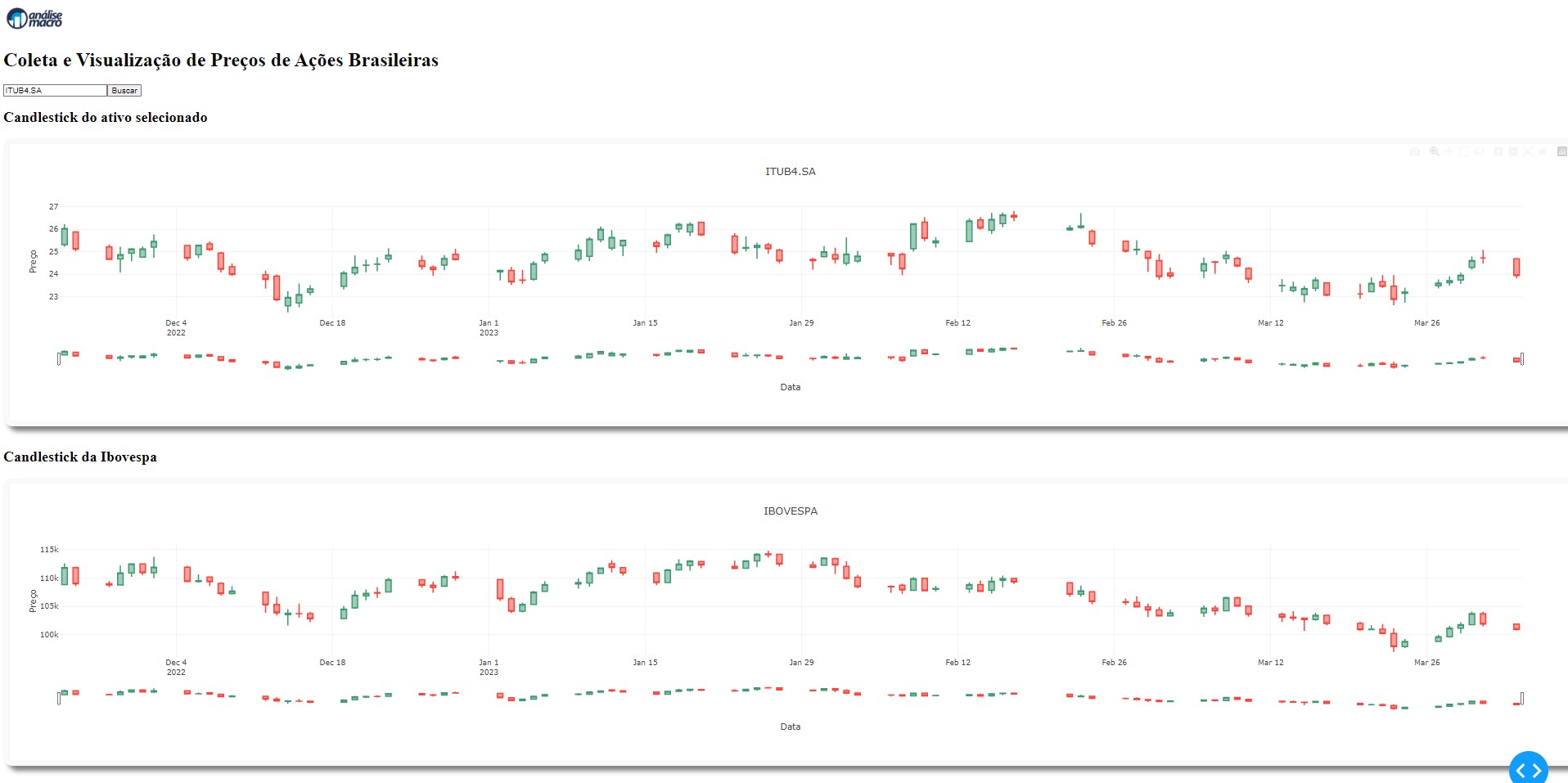
Coletando dados OHLC e Construindo um Dashboard no Python: um simples exemplo
É possível automatizar todo o processo de coleta e visualização de dados construindo um Dashboard no Python. O processo de coleta é feito por meio da biblioteca yfinance. O Dashboard é construído no ambiente da biblioteca Dash e os gráficos construídos por meio do Plotly.
O Dashboard uma barra de pesquisa que permite buscar a ação que o usuário desejar. O gráfico interativo construído no Dashboard com o Plotly é um gráfico de candlestick, possibilitando verificar o preço máximo, mínimo, de abertura e fechamento do dia do ativo e da Ibovespa.
Para obter o código do Dashboard abaixo, faça parte do Clube AM, o repositório de códigos da Análise Macro, contendo exercícios semanais de R e Python.
Abaixo, temos o Dashboard com os dois gráficos de Candlestick. Veja que é um Dashboard bem simples, e que tem como principal objetivo ser um exemplo introdutório para os iniciantes no Python com aplicações em Finanças.
_____________________
Quer saber mais?
Veja nossa trilha de cursos de Finanças Quantitativas

