Imagine-se na seguinte situação: você cria uma estratégia de investimentos, baseadas em diversos fatores de risco de um conjunto de ações, bem como uma análise acurada de diversas outras classes de ativos. Porém, ainda falta uma forma de conseguir evidenciar se a estratégia pode de fato dar certo. Para isso, é possível realizar um Backtest através do Python.
Existem diversas métricas e indicadores possíveis de se utilizar para obter o conhecimento de o quanto uma estratégia de investimentos se comportou no passado. Dentre elas, as mais importantes seguem como:
- Retorno Acumulado
- Comparação com um benchmark
- Drawdown - isto é - os períodos de queda do valor da ação
- Distribuição do Retorno
- Índice de Sharpe, entre outros índices
- Volatilidade dos retornos
- Beta
Existem diversos outros tipos de métricas, que seriam muito bem utilizadas para o propósito, sendo cada uma melhor atendendo os gostos de cada investidor a depender da estratégia.
Mas como podemos realizar todos estes testes utilizando o Python? É possível utilizar a biblioteca vectorbt, que oferece uma gama de funções para conseguir criar o Backtest.
Antes de continuar com o backtest, importaremos os dados para criar um estratégia da qual possamos analisar. Com a biblioteca PyPortfolioOpt, iremos criar um portfólio de fronteira eficiente de forma que consigamos criar uma estratégia e possamos avaliá-la com o vectorbt.
vectorbt
O vectorbt é um pacote do Python que permite realizar análises quantitativas, montagem de estratégias de investimentos e backtesting. O ponto do forte do pacote é justamente pela sua operação com outros pacotes para análises de dados do Python.
Abaixo, demonstraremos através do cálculo da fronteira eficiente de um portfólio de três ativos algumas funções úteis para obter métricas de backtesting utilizando o vectorbt.
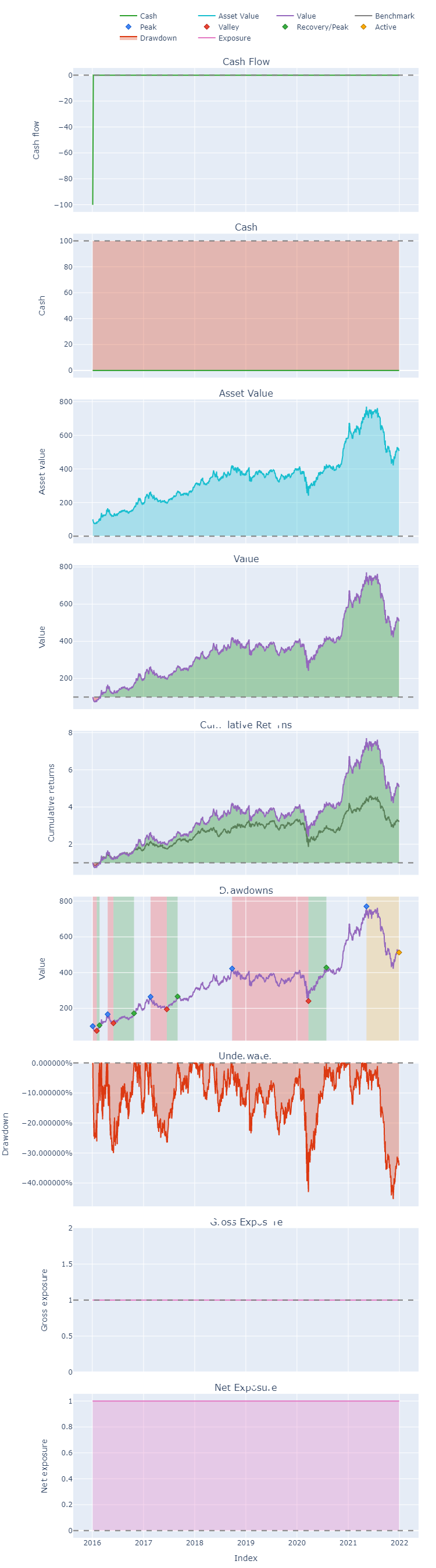
Veja que após criar os pesos ótimos, utilizamos eles para realizar a alocação somente em um primeiro momento do portfólio, sem rebalanceamento. Em seguida, com o método stats, verificamos os principais indicadores e a comparação do benchmark (Ibovespa). É possível alterar diversas configurações dos indicadores utilizando o argumento settings.
Para os gráficos, vemos o plot para todos os subplots possíveis da função. Por óbvio, devido a estratégia montada, alguns não fariam sentido, apesar de serem úteis para diversas outras.
Quer saber mais?
Veja nossos cursos de Python aplicado: R e Python para Economistas, Econometria usando R e Python e Estatística usando R e Python

