A rotatividade de clientes ocorre quando clientes ou assinantes param de fazer negócios com uma empresa ou serviço, também conhecido como atrito com clientes. Também é referido como perda de clientes ou simplesmente churn. Um setor no qual as taxas de cancelamento são particularmente úteis é o setor de telecomunicações. Na Edição 56 do Clube do Código, vamos prever a rotatividade de clientes usando um conjunto de dados de telecomunicações disponível no site da IBM, com base em modelos de regressão logística e Árvore de Decisão.
Os dados foram transferidos por download do IBM Sample Data Sets. Cada linha representa um cliente, cada coluna contém os atributos desse cliente:
churn = read.csv('Telco-Customer-Churn.csv')
As variáveis contidas no *dataset* são:
- customerID
- gender (female, male)
- SeniorCitizen (Whether the customer is a senior citizen or not (1, 0))
- Partner (Whether the customer has a partner or not (Yes, No))
- Dependents (Whether the customer has dependents or not (Yes, No))
- tenure (Number of months the customer has stayed with the company)
- PhoneService (Whether the customer has a phone service or not (Yes, No))
- MultipleLines (Whether the customer has multiple lines r not (Yes, No, No phone service)
- InternetService (Customer’s internet service provider (DSL, Fiber optic, No)
- OnlineSecurity (Whether the customer has online security or not (Yes, No, No internet service)
- OnlineBackup (Whether the customer has online backup or not (Yes, No, No internet service)
- DeviceProtection (Whether the customer has device protection or not (Yes, No, No internet service)
- TechSupport (Whether the customer has tech support or not (Yes, No, No internet service)
- streamingTV (Whether the customer has streaming TV or not (Yes, No, No internet service)
- streamingMovies (Whether the customer has streaming movies or not (Yes, No, No internet service)
- Contract (The contract term of the customer (Month-to-month, One year, Two year)
- PaperlessBilling (Whether the customer has paperless billing or not (Yes, No))
- PaymentMethod (The customer’s payment method (Electronic check, Mailed check, Bank transfer (automatic), Credit card (automatic)))
- MonthlyCharges (The amount charged to the customer monthly)
- TotalCharges (The total amount charged to the customer)
- Churn ( Whether the customer churned or not (Yes or No))
Os dados brutos contém 7043 linhas (clientes) e 21 colunas (recursos). A coluna *Churn* é o nosso alvo. Usamos todas as outras colunas como variáveis explicativas do nosso modelo. Uma grande parte do trabalho, contudo, é de limpeza dos dados, isto é, torná-los prontos para a parte de modelagem. Talvez por isso, escolhi o exercício para essa edição do Clube.
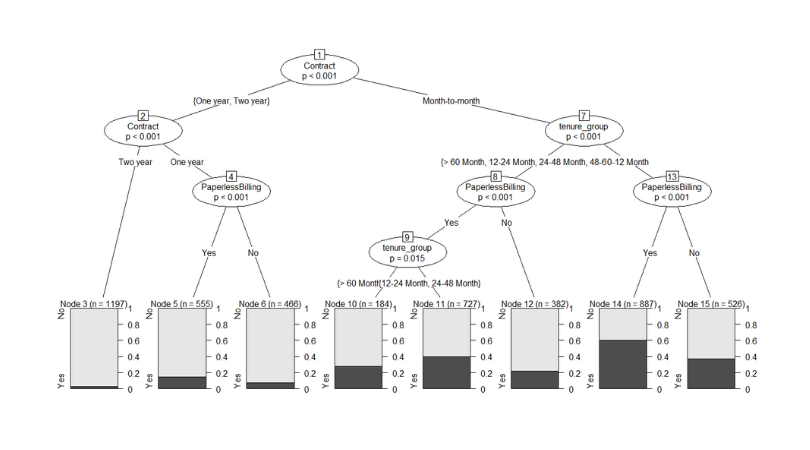
Uma vez que os dados estejam limpos, é possível dividir a amostra em subamostras de treino e teste, estimando uma regressão logística e construindo uma árvore de decisão. Ambos os modelos tem uma acurácia acima de 70%. Isto é, dentro da amostra de teste, eles conseguem performar corretamente em 70% dos casos - lembrando que a variável de interesse é uma variável binária.
O exercício estará disponível para os membros do Clube do Código na próxima semana.
______________________________________
(***) A ideia do exercício foi obtida em [towardsdatascience.com], um site bastante interessante para quem quer aprender Data Science.

