Dá para ler as atas do Copom com um modelo de linguagem e virar cada reunião em um número: um índice de tom que mede se a comunicação do Banco Central está mais hawkish (inclinada a subir juros) ou dovish (inclinada a cortar). Neste tutorial, montamos esse índice em Python com o Gemini do Google e o calibramos em pontos percentuais da própria Selic.
O ponto de partida é o texto das atas, denso e cheio de nuance, que analistas de mercado leem palavra por palavra para antecipar a Selic. O resultado é um indicador quantitativo que acompanha os ciclos de política monetária de 2020 a 2026, construído com dados públicos do Banco Central.
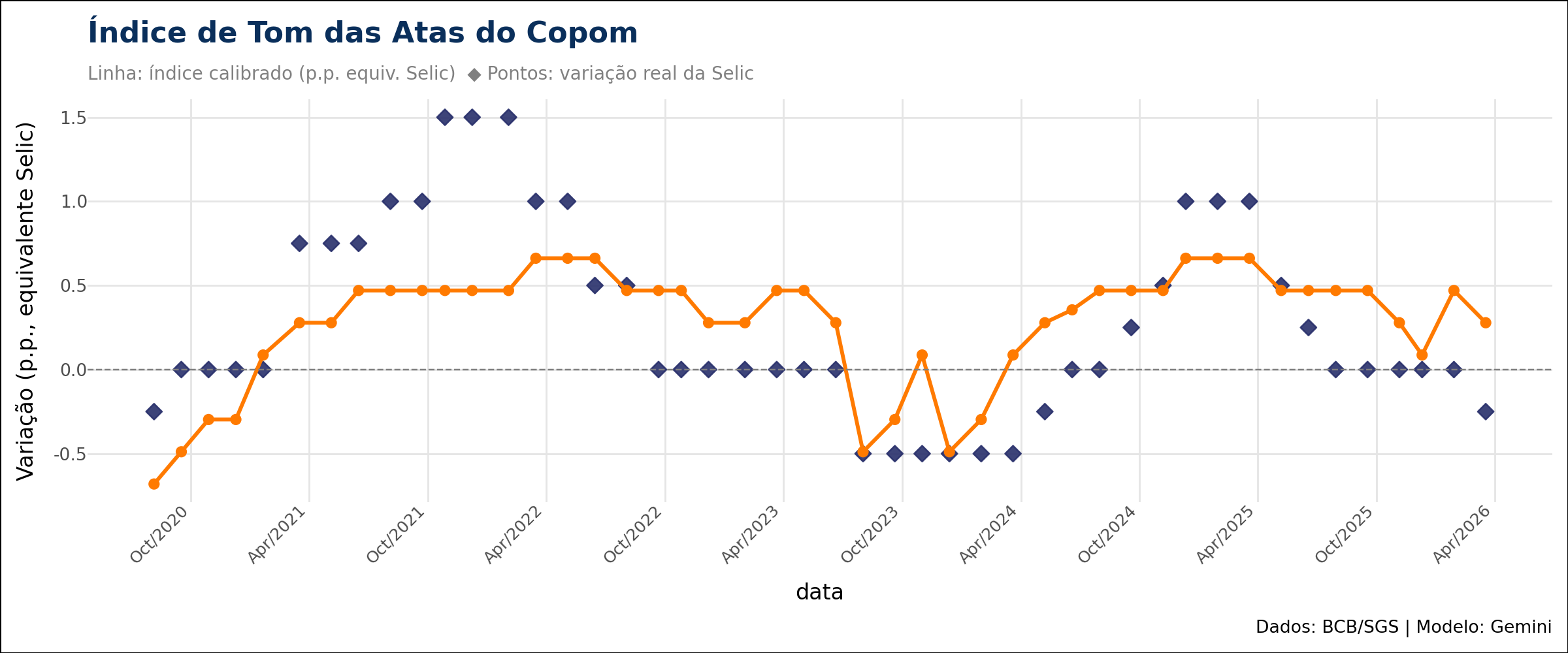
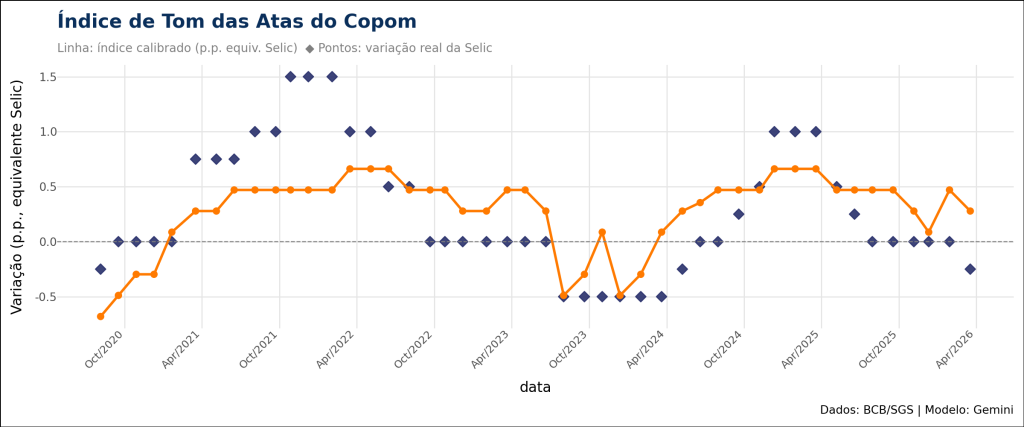
A linha laranja é o tom das atas convertido em pontos da Selic; os losangos são a variação efetiva da taxa em cada reunião. As duas séries andam juntas nos grandes ciclos: a queda de 2020, o aperto de 2021-2022 e o novo aperto a partir de 2024.
Quer construir este índice?
O código completo em Python (coleta das atas e da Selic via API do BCB, pontuação de tom com o Gemini via LangChain e calibração OLS) vai para os assinantes do Boletim AM. Assine, é gratuito, e receba no seu e-mail o notebook pronto para rodar no Colab.
Por que ler o tom das atas do Copom
A comunicação de um banco central é, por si só, um instrumento de política monetária. A escolha de palavras como "cautela", "parcimônia" e "vigilância" sinaliza a direção futura dos juros antes mesmo de qualquer decisão de taxa.
Termos como hawkish e dovish resumem esse tom. Uma comunicação hawkish (do inglês hawk, falcão) trata a inflação como ameaça e prepara o terreno para juros mais altos; uma dovish (de dove, pomba) enfatiza a atividade fraca e abre espaço para cortes. Ler esse tom cedo é o que permite antecipar o rumo da Selic.
Métodos anteriores contavam palavras a partir de dicionários de termos hawkish e dovish, como o de Loughran e McDonald. Um modelo de linguagem vai além da contagem: interpreta contexto e semântica, o que aproxima a leitura automática da interpretação econômica que um analista faria.
Como o índice foi construído
O pipeline tem três etapas, todas em Python, do texto bruto ao indicador calibrado. Cada uma resolve um problema distinto: obter e enxugar o texto, extrair o tom e traduzir esse tom em unidades da Selic.
1. Coleta e limpeza dos dados
O primeiro passo baixa todas as atas do Copom desde a reunião 232 (agosto de 2020) e a série histórica da meta Selic, direto das APIs públicas do Banco Central. O texto vem em HTML, então uma limpeza remove tags, notas de rodapé e espaços excessivos, deixando texto puro para o modelo ler.
Nem toda a ata carrega o mesmo sinal. O diagnóstico da conjuntura (Seção A) e o balanço de riscos (Seção B) concentram a informação sobre o tom; as seções seguintes apenas anunciam a decisão já conhecida. O código isola A e B, o que reduz em cerca de metade o texto enviado ao modelo sem perder o que importa para o índice.
2. Score de tom com o Gemini
Esta é a etapa central. O modelo gemini-flash-lite-latest recebe a persona de um economista sênior do Banco Central e uma escala de pontuação de -3.0 (fortemente dovish) a +3.0 (fortemente hawkish). O prompt traz âncoras explícitas para cada faixa, o que mantém os scores consistentes entre atas com linguagem parecida.
Uma instrução é decisiva: avaliar apenas o tom implícito no texto e ignorar a decisão de taxa já anunciada na ata. Sem isso, o modelo tenderia a "ler a resposta" em vez de medir a comunicação. O foco fica na linguagem sobre inflação, na ancoragem de expectativas e na sinalização prospectiva.
Para o resultado ser utilizável, o modelo é forçado a devolver uma saída estruturada: um JSON com um único número, validado por um schema. Isso elimina a leitura frágil de texto livre e garante que cada ata vire um score numérico pronto para a próxima etapa.
3. Calibração em pontos da Selic
O score de -3 a +3 é qualitativo. Para dar-lhe significado econômico, uma regressão linear (OLS) liga o score bruto à variação efetiva da Selic em cada reunião. O índice calibrado passa a ser expresso em pontos percentuais equivalentes da taxa, na mesma unidade que o mercado acompanha.
| Parâmetro da regressão | Valor | Leitura |
|---|---|---|
| β (sensibilidade) | +0,38 p.p. | cada ponto no score de tom equivale a ~0,38 p.p. de Selic |
| α (intercepto) | -0,11 | viés da taxa com tom neutro |
| R² | 0,386 | o tom explica ~39% da variação da Selic entre reuniões |
Calibração OLS do índice de tom sobre a variação da Selic (46 reuniões, 2020-2026). Fonte: BCB/SGS.
Um R² de 0,39 diz que o tom das atas, sozinho, dá conta de cerca de 39% do movimento da taxa entre reuniões. A decisão depende de outros fatores, mas a linguagem, isolada, já carrega sinal econômico mensurável.
O que os resultados revelam
O índice calibrado acompanha os ciclos de política monetária do período. O tom despenca para o campo dovish em 2020, sobe forte no aperto de 2021-2022, recua no início do ciclo de cortes e volta a subir a partir de 2024, no novo aperto.
Um segundo corte olha para a surpresa da comunicação. O gráfico abaixo mostra, para as reuniões mais recentes, o quanto o tom de cada ata se afastou da média histórica, em desvios padrão (z-score).
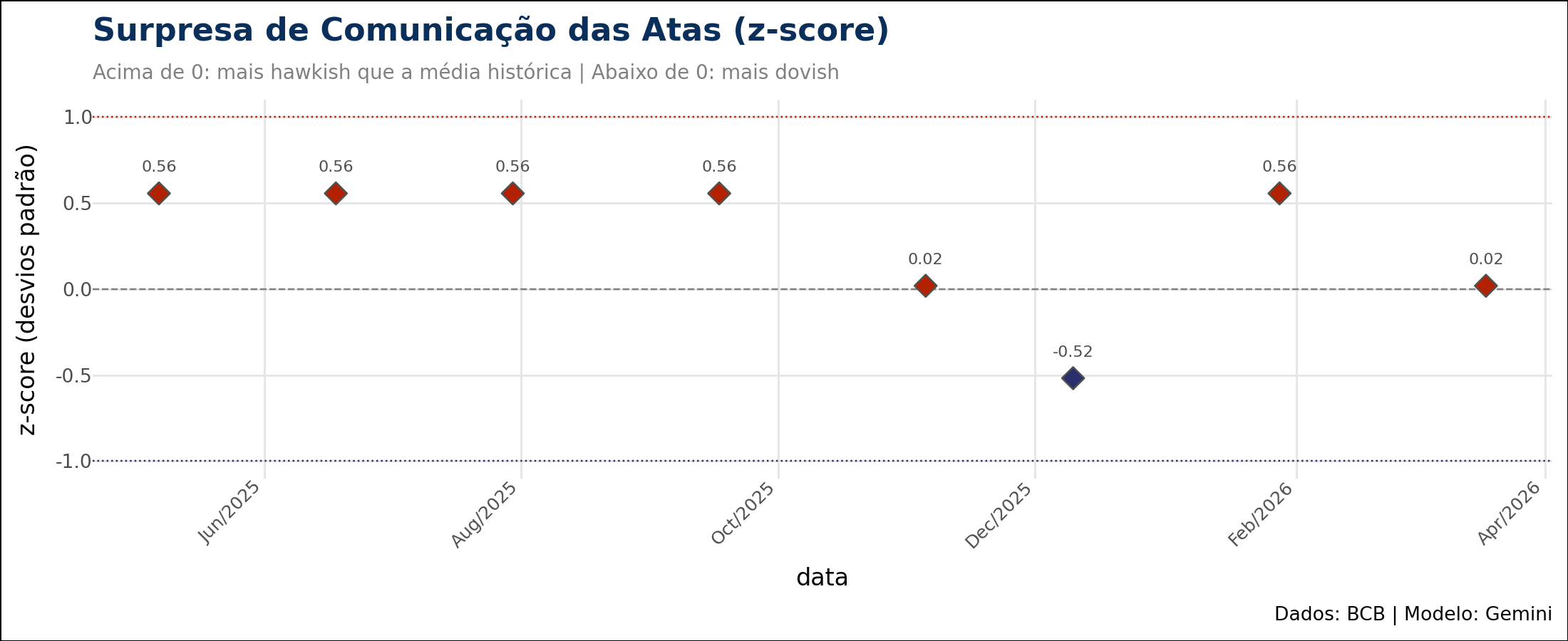
Pontos acima de zero marcam uma comunicação mais hawkish que o usual; abaixo de zero, mais dovish. É a leitura que ajuda a identificar reuniões em que o Copom sinalizou uma mudança de rota, o tipo de sinal que costuma mexer com o mercado.
As ferramentas por trás
requests para as APIs e plotnine para os gráficos.
Considerações finais
Com algumas dezenas de linhas de Python e dados públicos, você reproduziu uma leitura que, até pouco tempo, dependia de horas de trabalho manual sobre o texto das atas. A comunicação do Copom virou um indicador quantitativo, na mesma unidade que o mercado usa para falar da Selic.
Python é a ferramenta certa para isso porque reúne, num só ambiente, a coleta via API, a chamada ao modelo de linguagem e a modelagem estatística. O mesmo caminho — coletar, tratar, extrair sinal e visualizar — se repete em quase todo problema de análise econômica e financeira. O que muda é a aplicação:
- Analista de mercado: transforma comunicados e relatórios em indicadores de sentimento para antecipar decisões de juros.
- Economista: mede de forma sistemática a comunicação de bancos centrais e testa seu poder preditivo sobre a política monetária.
- Gestor e trader: monta sinais de tom para incorporar a leitura das atas em cenários e estratégias.
- Risco: monitora surpresas de comunicação que podem antecipar mudanças de rota do comitê.
Aprender a linguagem é o que abre a porta para todas essas frentes.
Você viu como funciona; aprenda a construir do zero
A Formação Do Zero à Análise de Dados Econômicos e Financeiros usando Python e IA ensina, sem pré-requisito, o caminho completo que este exercício usa: coletar dados públicos, aplicar modelos de linguagem e visualizar resultados em Python. Quem quer acesso a todas as formações tem o AM Black, a assinatura anual.
Leia também: