A inflação foi o tema recorrente no Blog essa semana. Para fechar a discussão sobre isso, imagine que você estivesse interessado em ver a contribuição dos 9 grupos do IPCA para a inflação cheia ao longo do tempo. De modo a construir um gráfico como esse, podemos usar o R, de modo a baixar com o pacote sidrar as variações e os pesos desses nove grupos do IPCA diretamente do site do SIDRA/IBGE, conforme o código abaixo - saiba mais em nosso Curso de Análise de Conjuntura usando o R.
## Carregar pacotes library(sidrar) ## Baixar e tratar os dados tab1 = get_sidra(api='/t/2938/n1/all/v/63,66/p/all/c315/7170,7445,7486,7558,7625,7660,7712,7766,7786/d/v63%202,v66%204') tab2 = get_sidra(api='/t/1419/n1/all/v/63,66/p/all/c315/7170,7445,7486,7558,7625,7660,7712,7766,7786/d/v63%202,v66%204')
Uma vez que tenhamos baixado os dados, é preciso organizá-los, transformando-os em uma matriz legível. Para isso, nós podemos utilizar um loop de modo a não ter de pegar um a um os dados de variação e peso para cada mês. Isso é feito com o código a seguir.
series = c(7170, 7445, 7486, 7558, 7625, 7660,
7712, 7766, 7786)
names = c('Alimentos', 'Habitação', 'Art de Resid',
'Vestuário', 'Transporte', 'Saúde e cuid pessoais',
'Despesas Pessoas', 'Educação', 'Comunicação')
var1 = matrix(NA, ncol=length(series),
nrow=nrow(tab1)/length(series)/2)
peso1 = matrix(NA, ncol=length(series),
nrow=nrow(tab1)/length(series)/2)
var2 = matrix(NA, ncol=length(series),
nrow=nrow(tab2)/length(series)/2)
peso2 = matrix(NA, ncol=length(series),
nrow=nrow(tab2)/length(series)/2)
for(i in 1:length(series)){
var1[,i] <- tab1$Valor[tab1$`Variável (Código)`==63&
tab1$`Geral, grupo, subgrupo, item e subitem (Código)`==series[i]]
var2[,i] <- tab2$Valor[tab2$`Variável (Código)`==63&
tab2$`Geral, grupo, subgrupo, item e subitem (Código)`==series[i]]
peso1[,i] <- tab1$Valor[tab1$`Variável (Código)`==66&
tab1$`Geral, grupo, subgrupo, item e subitem (Código)`==series[i]]
peso2[,i] <- tab2$Valor[tab2$`Variável (Código)`==66&
tab2$`Geral, grupo, subgrupo, item e subitem (Código)`==series[i]]
}
variacao = ts(rbind(var1, var2), start=c(2006,07), freq=12)
peso = ts(rbind(peso1, peso2), start=c(2006,07), freq=12)
colnames(variacao) = names
colnames(peso) = names
Pronto! Agora, temos uma matriz que contém a variação dos nove grupos, desde julho de 2006; e outra que contém os pesos desses grupos para o mesmo período. Agora, nós podemos construir um gráfico que ilustre a contribuição desses grupos em cada um dos meses, bem como adicionamos a esse gráfico a inflação mensal cheia. O código a seguir implementa.
contribuicao = variacao*peso/100
colnames(contribuicao) = names
time = as.Date(time(contribuicao))
data_bar = xts(contribuicao, order.by = time)
data_bar = data.frame(time=index(data_bar),
melt(as.data.frame(data_bar)))
colnames(data_bar) = c('time', 'tipo', 'value')
ipca = ts(round(rowSums(variacao*peso/100),2),
start=c(2006,07), freq=12)
data_ipca = xts(ipca, order.by = time)
data_ipca = data.frame(time=index(data_bar),
melt(as.data.frame(data_ipca)))
img <- readPNG('logo.png')
g <- rasterGrob(img, interpolate=TRUE)
ggplot(data_bar, aes(x=time, y=value))+
geom_col(aes(fill=tipo))+
geom_line(data=data_ipca, aes(x=data_bar$time, y=value),
colour='black', size=.8)+
theme(legend.position = 'bottom',
legend.key.size = unit(0.3, "cm"),
legend.title = element_blank())+
scale_x_date(breaks = date_breaks("1 year"),
labels = date_format("%Y"))+
labs(x='', y='p.p.',
title='Contribuição dos grupos para a inflação medida pelo IPCA',
caption='Fonte: analisemacro.com.br')+
annotation_custom(g,
xmin=as.Date('2006-06-01'),
xmax=as.Date('2010-01-01'),
ymin=0.7, ymax=1.6)
E o gráfico...
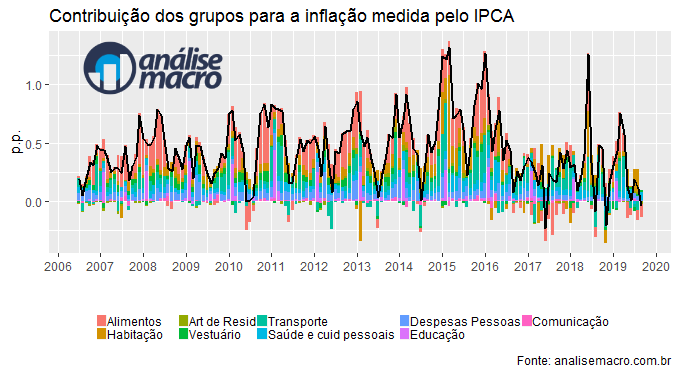 Temos então um gráfico com a contribuição de cada um dos 9 grupos do IPCA construído de forma automática. Da próxima vez, é só rodar o script com o último dado disponível.
Temos então um gráfico com a contribuição de cada um dos 9 grupos do IPCA construído de forma automática. Da próxima vez, é só rodar o script com o último dado disponível.
________________________


