O IBGE divulgou hoje pela manhã o resultado da Produção Industrial referente a setembro. A coleta, tratamento e apresentação dos dados da pesquisa com o R é ensinada no nosso Curso de Análise de Conjuntura usando o R. A seguir, apresento uma parte do código que gera a apresentação disponível ao final do post.
O script começa carregando alguns pacotes:
library(tidyverse) library(lubridate) library(tstools) library(sidrar) library(zoo) library(scales) library(gridExtra) library(tsibble) library(timetk) library(knitr)
Na sequência, importamos os dados da indústria geral e das atividades da indústria de transformação diretamente do SIDRA/IBGE com o pacote sidrar. Tanto o número índice encadeado quanto o número índice ajustado sazonalmente.
# Produção Física por Seção e Atividades
## Número-Indice com ajuste sazonal
tabela_sa = get_sidra(api='/t/3653/n1/all/v/3134/p/all/c544/all/d/v3134%201') %>%
mutate(date = parse_date(`Mês (Código)`, format='%Y%m')) %>%
select(date, "Seções e atividades industriais (CNAE 2.0)", Valor) %>%
spread("Seções e atividades industriais (CNAE 2.0)", Valor) %>%
as_tibble()
## Número-Indice sem ajuste sazonal
tabela = get_sidra(api='/t/3653/n1/all/v/3135/p/all/c544/all/d/v3135%201') %>%
mutate(date = parse_date(`Mês (Código)`, format='%Y%m')) %>%
select(date, "Seções e atividades industriais (CNAE 2.0)", Valor) %>%
spread("Seções e atividades industriais (CNAE 2.0)", Valor) %>%
as_tibble()
Feito isso, podemos criar algumas métricas de crescimento com o código abaixo.
## Variação na Margem tabela_sa_ts = ts(tabela_sa[,-1], start=c(year(tabela_sa$date[1]), month(tabela_sa$date[1])), freq=12) margem = (tabela_sa_ts/stats::lag(tabela_sa_ts,-1)-1)*100 colnames(margem) <- colnames(tabela_sa[,-1]) margem = tk_tbl(margem, preserve_index = TRUE, rename_index = 'date') margem_long = margem %>% gather(variavel, valor, -date) ## Variação Interanual tabela_ts = ts(tabela[,-1], start=c(year(tabela$date[1]), month(tabela$date[1])), freq=12) interanual = (tabela_ts/stats::lag(tabela_ts,-12)-1)*100 colnames(interanual) <- colnames(tabela[,-1]) interanual = tk_tbl(interanual, preserve_index = TRUE, rename_index = 'date') interanual_long = interanual %>% gather(variavel, valor, -date) ## Variação acumulada em 12 meses anual = acum_i(tabela_ts,12) %>% as_tibble() %>% mutate(date = tabela$date) %>% drop_na() %>% select(date, everything()) anual_long = anual %>% gather(variavel, valor, -date)
Uma vez que conseguimos criar as métricas de crescimento, podemos apresentar as mesmas. Primeiro, em tabelas.
| Mês | Indústria Geral | Indústria Extrativa | Indústria de Transformação |
|---|---|---|---|
| abr 2020 | -19.52 | -0.46 | -23.41 |
| mai 2020 | 8.71 | -5.00 | 13.29 |
| jun 2020 | 9.59 | 5.02 | 10.41 |
| jul 2020 | 8.62 | 9.21 | 9.30 |
| ago 2020 | 3.61 | 3.09 | 3.65 |
| set 2020 | 2.55 | -3.73 | 3.87 |
Como se vê, a indústria geral tem apresentado seguidas variações positivas desde maio. O gráfico a seguir ilustra a retomada.
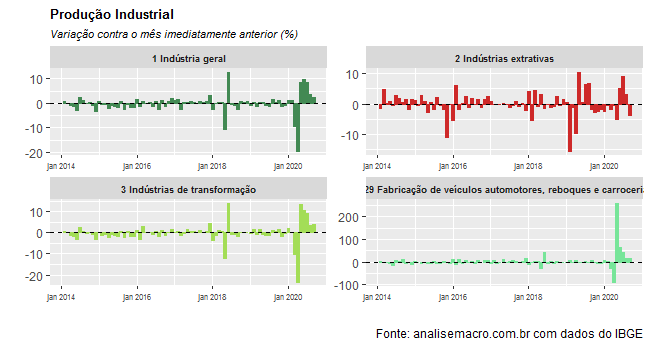
Essa retomada na margem, diga-se, aos poucos deve ser sentida nas outras métricas. Os gráficos abaixo mostram a recuperação quando se considera a variação interanual.
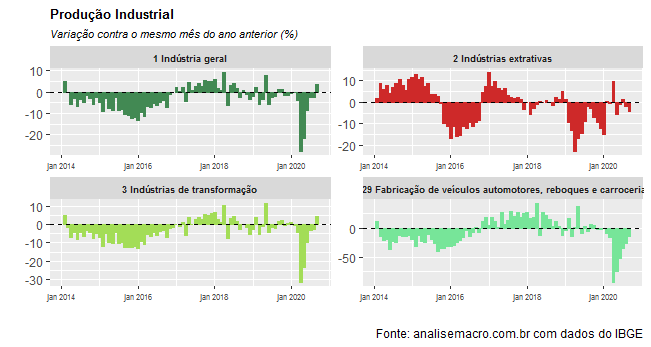
Mais lentamente, contudo, veremos uma recuperação sendo sentida na variação acumulada em 12 meses, como pode ser visto nos gráficos a seguir.
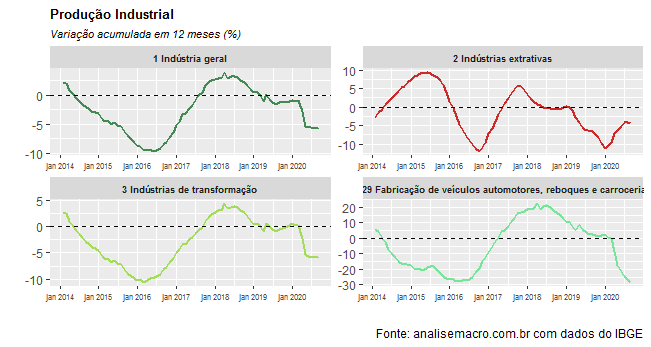
(*) A análise completa está disponível no nosso Curso de Análise de Conjuntura usando o R.


