Funções de importação e coleta de dados são pontos críticos de qualquer script, e é esperado que erros e falhas sejam gerados em algum momento. Neste texto iremos mostrar como melhorar essas funções usando o purrr para lidar com possíveis erros que podem ser uma dor de cabeça pro usuário de R.
Se você costuma coletar dados de bases públicas, seja através de uma API ou um link para um arquivo, provavelmente já ficou no vácuo aguardando sua requisição de dados ser concluída ou, pior, obteve um erro na requisição. Isso é muito comum ao se utilizar pacotes de R para coleta de dados via API's, mas também pode acontecer com links diretamente para arquivos. As origens dessas falhas podem ser diversas: sua conexão de internet instável, API de dados com instabilidade, site/link fora do ar, você está fazendo muitas requisições sucessivas, sua sessão de R está com conexões abertas conflitantes, etc.
Exemplo: importar planilha de dados através de um link
Como exemplo, vamos supor que você esteja (no pior cenário) tentando coletar dados de uma planilha de Excel disponibilizada através de um link de um determinado site. Este link as vezes funciona, as vezes demora a carregar e as vezes falha completamente, mas você precisa desses dados para rodar um relatório diariamente. Portanto, sua missão é tornar seu script de coleta desses dados mais resistente a essas possíveis falhas.
Neste contexto, uma estratégia possível é continuar tentando a requisição dos dados pelo link por um número x de vezes até, definitivamente, falhar. Com o pacote purrr podemos criar essa estratégia de forma muito fácil usando a função insistently. Ainda é possível determinar um valor de retorno padrão (por exemplo, um texto "Falha da requisição") para caso a falha aconteça, bastando combinar a função anterior com a função possibly. Vamos aos exemplos!
Os pacotes utilizados neste exercício estão descritos a seguir. Você pode instalar os mesmos a partir do CRAN.
library(purrr) # CRAN v0.3.4 library(rio) # CRAN v0.5.27
Neste exemplo definimos um link para uma planilha de dados do Banco Central do Brasil (BCB) que possivelmente pode estar indisponível ou instável em algum momento. Então criamos uma configuração (purrr::rate_delay) de número de tentativas para a importação da planilha e tempo de espera em segundos entre cada tentativa.
Em seguida usamos a função rio::import() para importar a planilha para o R com a diferença de que modificaremos a função incluindo a configuração criada anteriormente (pausa & tentativas). Para incluir essa modificação usamos a função insistently, bastando especificar uma função a ser modificada (f), um configuração de pausa & tentativas (rate) e, opcionalmente, indicar se devem ser exibidas mensagens no Console (quiet). No final teremos uma nova função chamada insist_import no Environment e usamos ela para coletar os dados da planilha.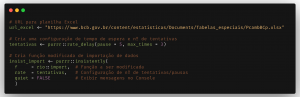 Perceba que todos os possíveis argumentos da função original (rio::import) são preservados e podemos usá-los na função modificada (insist_import).
Perceba que todos os possíveis argumentos da função original (rio::import) são preservados e podemos usá-los na função modificada (insist_import).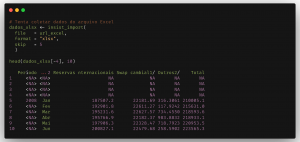 Podemos ir um passo além e determinar o que deve ser retornado caso a importação dos dados falhe nas 3 tentativas. Para isso usamos a função purrr::possibly(), que retorna um valor padrão quando a falha acontece na função que criamos.
Podemos ir um passo além e determinar o que deve ser retornado caso a importação dos dados falhe nas 3 tentativas. Para isso usamos a função purrr::possibly(), que retorna um valor padrão quando a falha acontece na função que criamos.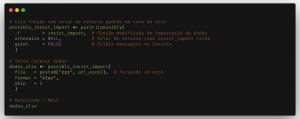 O mesmo procedimento pode ser feito para qualquer outra função de importação e coleta de dados, seguindo a mesma lógica.
O mesmo procedimento pode ser feito para qualquer outra função de importação e coleta de dados, seguindo a mesma lógica.
Espero que esses exemplos amenizem suas possíveis dores de cabeça com coleta de dados no R!
________________________
(*) Para entender mais sobre a linguagem R e suas ferramentas, confira nosso Curso de Introdução ao R para análise de dados.

