O Censo Demográfico é a maior operação de recenseamento no país, produzindo dados demográficos, econômicos e sociais sobre a população brasileira. Através dos microdados, menor nível de desagregação da pesquisa, podemos construir análises, fazer cruzamentos, realizar estudos e pesquisas de interesse. Neste exercício mostramos como dar o primeiro (e difícil) passo: importar os arquivos de texto formatados em ASCII no R.
Dado a complexidade e volume dos microdados, os arquivos de download são sempre acompanhados de uma documentação auxiliar que fornece os nomes, os códigos e as descrições das variáveis e suas categorias, complementada, quando necessário, dos elementos necessários para o cálculo dos erros amostrais. Ambos estes elementos, microdados e documentação, são essenciais para a correta leitura e análise de dados.
Dessa forma, neste exercício iremos exemplificar a importação dos microdados do Censo 2010, referente ao estado do Rio Grande do Sul. Para saber mais sobre os detalhes e informações do Censo, consulte o site do IBGE.
Pacotes
Para reproduzir o exercício a seguir você precisará dos seguintes pacotes:
library(lodown) # [github::ajdamico/lodown] v0.1.0 library(magrittr) # CRAN v2.0.1 library(dplyr) # CRAN v1.0.7 library(stringr) # CRAN v1.4.0 library(fs) # CRAN v1.5.0 library(SAScii) # CRAN v1.0 library(readr) # CRAN v2.0.2
Baixar dados
Existem algumas opções de acesso aos microdados do Censo Demográfico: diretamente no site, através de pacotes, de consultas em banco de dados, arquivos offline, etc. Em todos os casos, é necessário especial cuidado devido a complexidade e dimensão dos dados. Neste exemplo focaremos em reprodutibilidade, portanto, usaremos o pacote lodown que facilita o download dos arquivos de microdados e sua documentação.
A função get_catalog nos fornece diversas informações sobre os microdados abrangidos atualmente pelo pacote. Na posse dessas informações, aplicamos filtros para o Censo de 2010 referente ao estado Rio Grande do Sul e, por fim, baixamos os microdados com a função lodown:
# Buscar catálogo de microdados, aplicar filtros e baixar arquivos catalog <- lodown::get_catalog(data_name = "censo", output_dir = "data") %>% dplyr::filter(year == 2010, stringr::str_detect(state, "rs")) %>% lodown::lodown(data_name = "censo") # Arquivos baixados fs::dir_tree(path = "data") # data # \-- 2010 # \-- RS # +-- Amostra_Domicilios_43.txt # +-- Amostra_Emigracao_43.txt # +-- Amostra_Mortalidade_43.txt # \-- Amostra_Pessoas_43.txt
Importar dados
Com os arquivos disponíveis localmente, podemos prosseguir agora para a importação. Nesta etapa é importante definir quais variáveis serão de fato utilizadas - já que há um grande volume de observações que podem causar lentidão no computador por restrição de memória -, fazemos isso no objeto vars_censo. Em seguida, convertemos as instruções de importação (layout) do arquivo Amostra_Pessoas_43.txt para o formato de um data.frame, visando usar estas instruções - de largura e tipo de colunas - na importação através da função read_fwf:
# Variáveis a serem importadas
vars_censo <- c("v0001", "v0601", "v6036", "v0010", "v0011", "v0300")
# Converte arquivo de instruções de importação SAS para o R
sas_input <- SAScii::parse.SAScii(catalog$pes_sas) %>%
dplyr::mutate(varname = stringr::str_to_lower(varname))
# Importar arquivo TXT
raw_censo <- readr::read_fwf(
file = catalog$pes_file,
col_positions = readr::fwf_widths(
widths = abs(sas_input$width),
col_names = sas_input$varname
),
col_types = paste0(
ifelse(
!(sas_input$varname %in% vars_censo),
"_",
ifelse(sas_input$char, "c", "d")
),
collapse = ""
)
)
Estrutura dos dados importados:
dplyr::glimpse(raw_censo) # Rows: 1,388,443 # Columns: 6 # $ v0001 <chr> "43", "43", "43", "43", "43", "43", "43", "43", "43", "43", "43"~ # $ v0011 <chr> "4300034001001", "4300034001001", "4300034001001", "430003400100~ # $ v0300 <dbl> 60085, 60085, 65479, 65479, 65479, 81979, 81979, 81979, 81979, 8~ # $ v0010 <dbl> 2.814269e+13, 2.814269e+13, 2.842956e+13, 2.842956e+13, 2.842956~ # $ v0601 <chr> "1", "2", "2", "2", "1", "2", "2", "1", "1", "2", "1", "2", "2",~ # $ v6036 <dbl> 31, 74, 8, 39, 39, 16, 13, 11, 9, 38, 7, 10, 31, 47, 2, 8, 6, 38~
Próximos passos
Com os dados brutos em mãos, o recomendável é usar um framework que suporte a construção de objetos que representem um desenho amostral complexo. Para essa tarefa, recomendamos o uso do pacote survey, que traz diversas facilidades e é usado amplamente, inclusive pela equipe do IBGE.
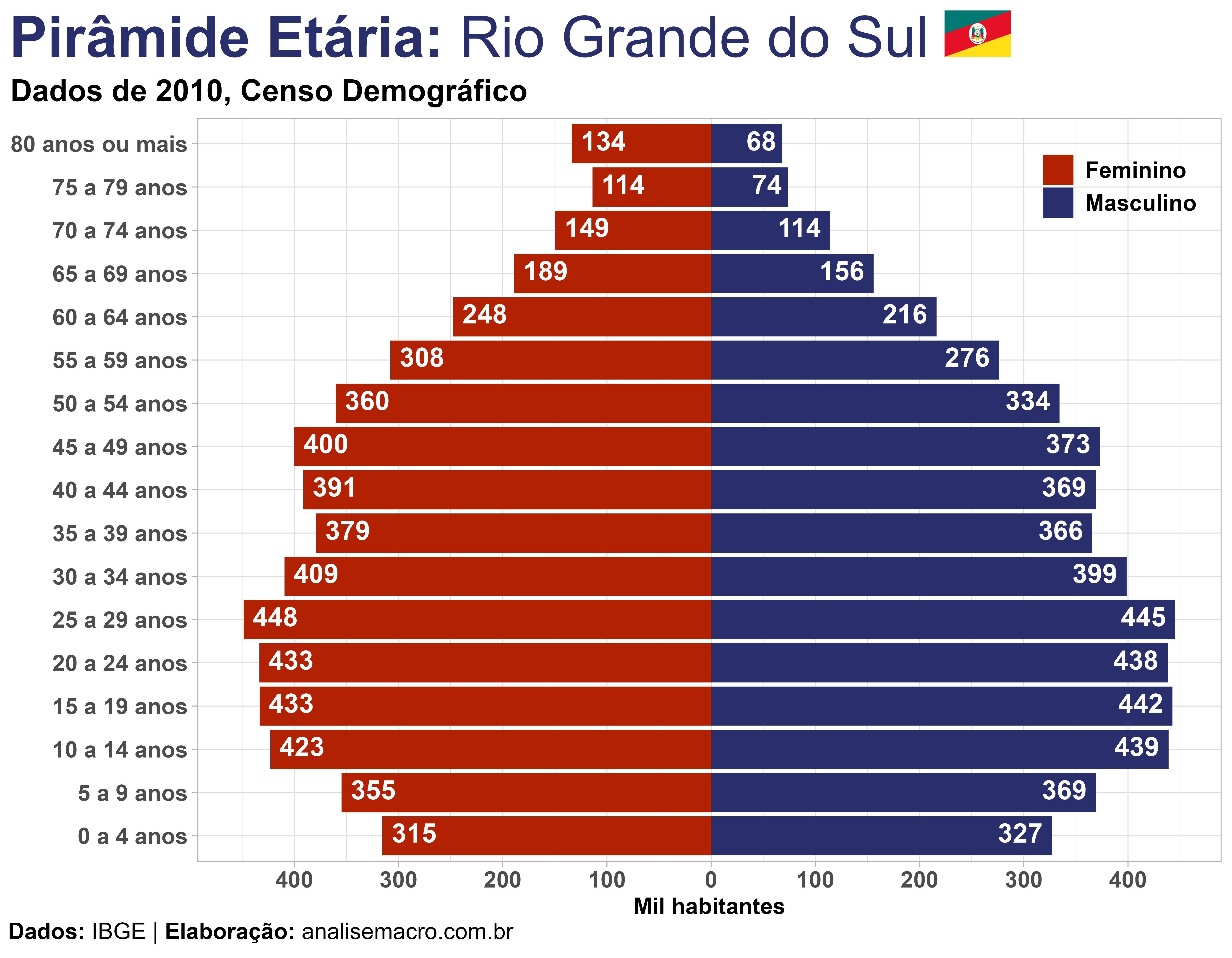
Seguindo este procedimento podemos chegar, por exemplo, a análises como essa:
Referências
Analyze Survey Data for Free: Brazilian Censo Demografico (Djalma Pessoa)


