Um tema que os economistas sempre estudam é a inflação. A inflação é conhecida como a taxa de crescimento do nível geral de preços entre dois períodos distintos. No post de hoje, iremos aprender passo a passo a como construir uma análise de dados do zero do indicador, iniciando pela etapa de importação, seguindo para limpeza e tratamento, exploração e visualização e iremos finalizar criando um modelo de regressão de forma a entender a inflação com a ajuda da teoria econômica.
Averiguar a inflação de um país é uma tarefa dificultosa, imagine, medir o preços de todos os produtos? Apesar disso, o IBGE realiza uma árdua tarefa que visa tentar replicar o valor da inflação através do Índice de Preço dos Consumidor Amplo - IPCA , criando pesquisas que visam entender o consumo dos brasileiros, ponderando os produtos e calculando as variações dos mesmos ao longo do tempo.
E o interessante é que o instituto disponibiliza os dados do indicador através de sua plataforma: SIDRA.
Conseguimos acessar os dados do SIDRA através de uma API disponibilizada pelo instituto, entretanto, seria um pouco dificultoso aprender a como utilizar a API e consultar os dados, não?
Por isso, a comunidade do R fez a questão de criar um pacote que auxilia no processo: {sidrar}. Vamos utilizar o pacote para buscar os dados.
Para buscar os dados do SIDRA, devemos acessar a plataforma, encontrar a tabela dos dados do IPCA que desejamos, selecionar os parâmetros (as informações que desejamos importar) e em seguida copiar a chave API. Para mais detalhes veja os posts de como importar os dados: Como importar dados do Banco Central, IPEADATA e Sidra no R? e Coletando dados do SIDRA com o Python.
Vamos utilizar a tabela 1737, referente aos dados do IPCA Acumulado em 12 meses. O objetivo de utilizar o acumulado é que desta forma podemos entender a variação em um período de maior longo prazo e que possibilita tirar informações mais interessante sobre a conjuntura se comparado com a variação mensal ou mesmo o número índice.
Com a chave API em mãos, podemos utilizar a função do pacote {sidrar}, get_sidra(), e salvar o resultado da consulta em um objeto.
Coleta
Agora já temos uma forma de importar os dados do IPCA direto no R! Entretanto, vamos analisar o que importamos:
Limpeza e Tratamento
Há diversas colunas, com dados que não possuem importância para a nossa análise, bem como possuem colunas em que os tipos de dados estão totalmente errados! Devemos criar uma forma do R conseguir ler corretamente. Partimos para o processo de limpeza e tratamento.
Veja o código acima, parece um pouco complicado, certo? Vamos explicar um pouco o que está acontecendo.
Em primeiro lugar, colocamos o nome do objeto ipca_raw, em seguida um símbolo |> e depois uma função. O que aconteceu aqui? Estamos utilizando o operador pipe do R, que permite colocarmos tudo o que está do lado esquerdo (isto é, o resultado) dentro do primeiro argumento da função da próxima linha.
O primeiro argumento da função select() é um argumento que especifica qual o objeto com dados deverá ser utilizado, no caso, ipca_raw. O operador ajuda a criarmos uma sequência de códigos limpa e fácil de ler.
Seguindo o processo, iremos utilizar a função select() do pacote dplyr, que vai permitir escolhermos quais as colunas que queremos selecionar do data frame importado. No caso, selecionamos 2 colunas: Mês (Código) e Valor, veja que selecionamos utilizando aspas e também colocando "data" e "ipca" como valores iguais as colunas. Utilizamos isso para encurtar o caminho: estamos alterando o nome das colunas selecionadas para data e ipca, ou seja, além de selecionar colunas a função select permite alterar o nome das mesmas.
Em seguida, utilizamos pipe novamente, colocando o resultado da linha dentro da função da próxima linha: mutate(). A função mutate() permite alterar as observações das colunas do data frame. Aqui, utilizaremos a função ym do pacote lubridate para alterar os dados da coluna data para o tipo date (está em formato character).
Logo após, vamos aplicar um filtro de dados no data frame com a função filter(). Queremos dados a partir de 2004-01-01, que está salvo no objeto data_inicio. Para isso, dentro da função filter() colocamos que queremos os valores da coluna data >= (maior e igual) que data_inicio (2004-01-01).
Por fim, utilizamos a função as_tibble para alterar a estrutura de dados (a classe) do objeto para tibble, que é uma classe similar ao data frame usual, entretanto com mais informações.
Exploração dos Dados
Agora que realizamos a limpeza dos dados, podemos realizar a exploração dos dados.
Devemos começar com algumas perguntas para a nossa análise:
Como a inflação se comportou no Brasil?
Qual o período com menores e maiores taxas de inflação?
Qual o valor médio da inflação do Brasil e como é a distribuição de seus valores?
O que afeta a inflação? Com qual variável ela se relaciona?
Vamos começar com a função summary(), que permite calcular os cinco números dos valores do IPCA. Vemos que o valor mínimo do IPCA Acumulado em 12 meses foi de 1,880%, enquanto o valor máximo foi de 12,13%. A mediana dos valores durante o período está em 5,832%.
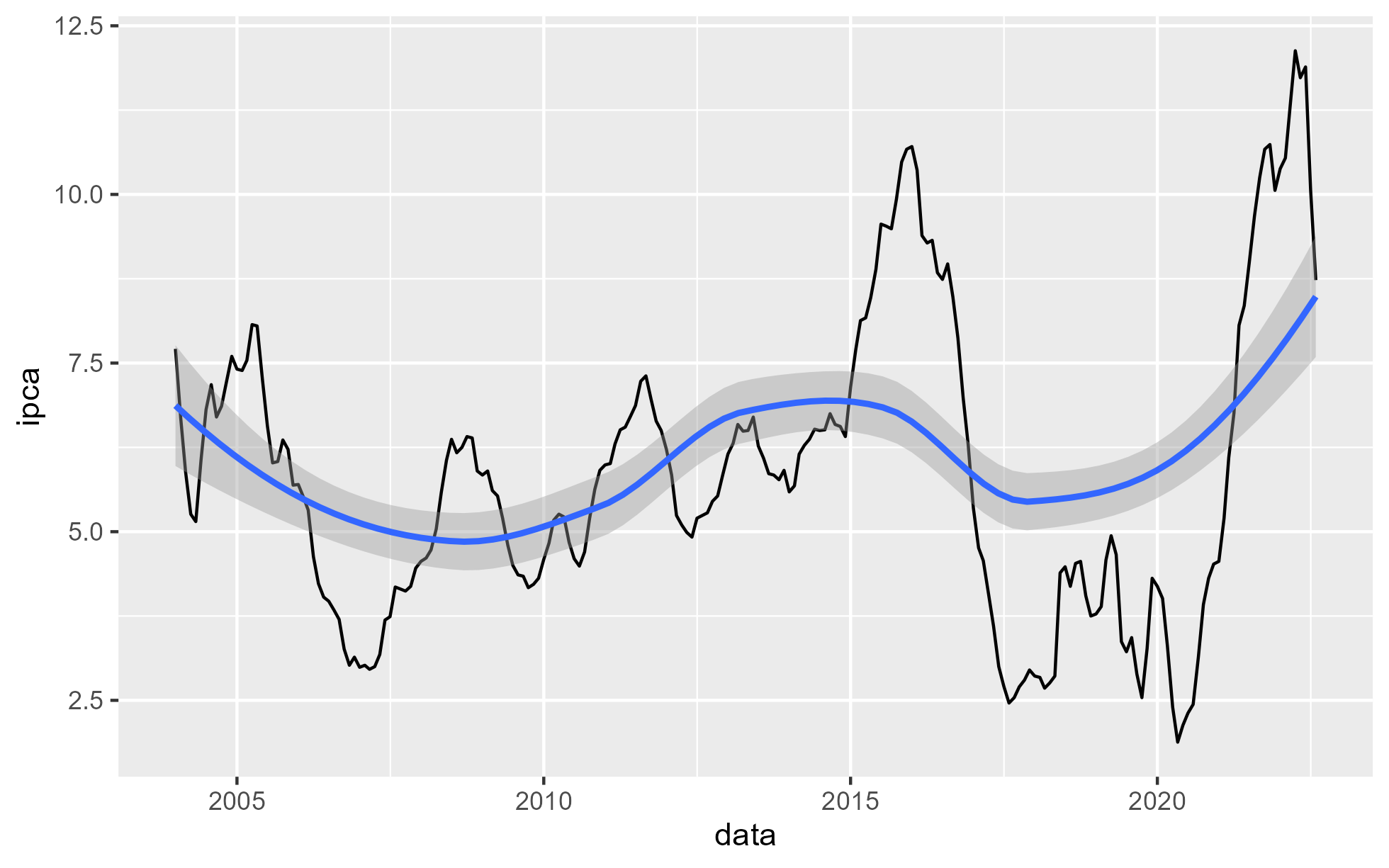
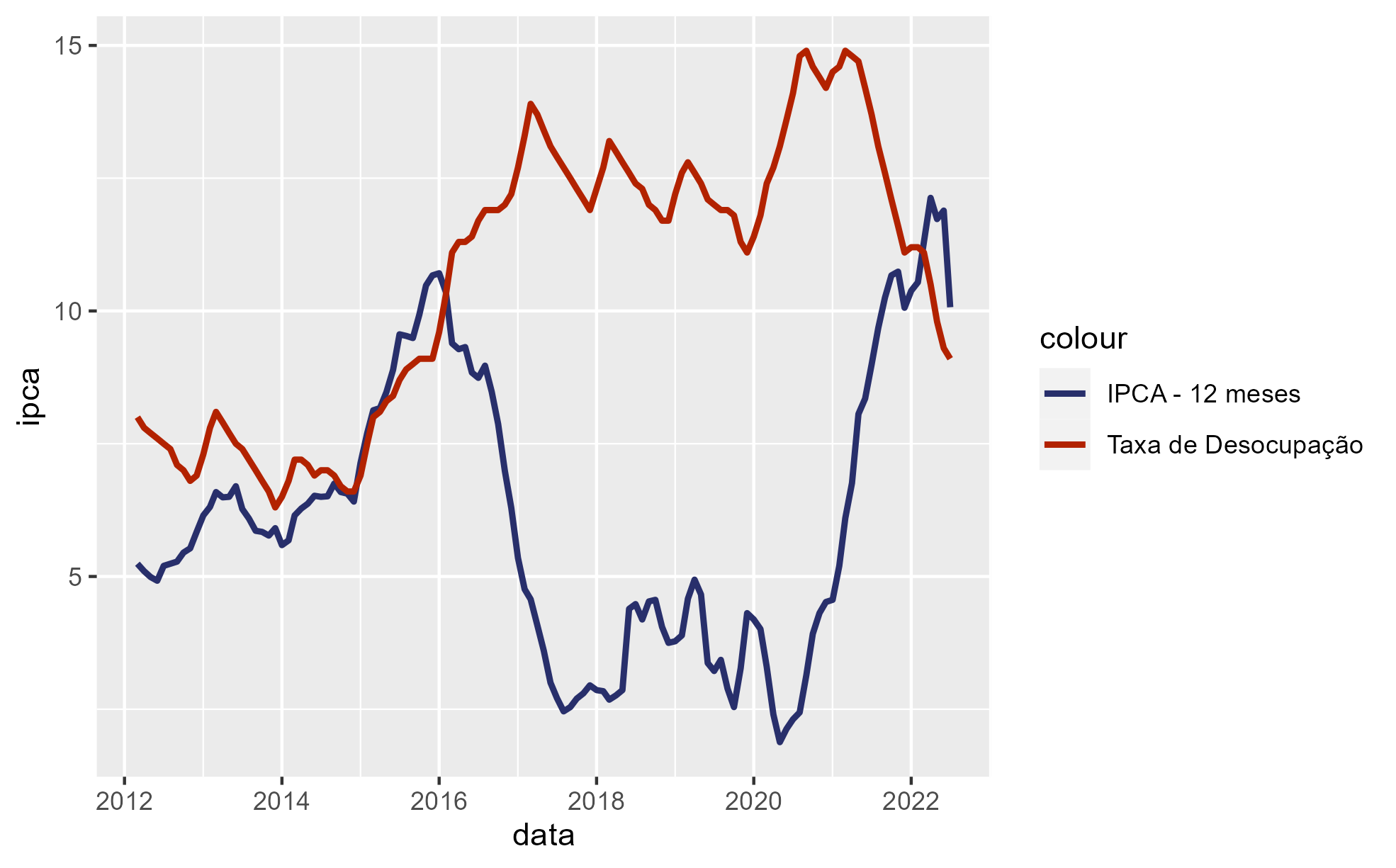
Podemos entender o comportamento do indicador ao longo do tempo através de uma gráfico de linha, com a data no eixo x e o IPCA no eixo y. Para construir, utilizamos o pacote {ggplot2}, com as suas funções. Primeiro criamos a camada do gráfico com ggplot(), em seguida, criamos a camada das coordenadas dos dados do gráfico com aes(), depois construído o gráfico de linha com geom_line(), e por fim, adicionamos geom_smooth() para criar uma linha que mensura a tendência do indicador ao longo da série.
Veja que no gráfico podemos entender os período em que houveram maior e menor inflação.
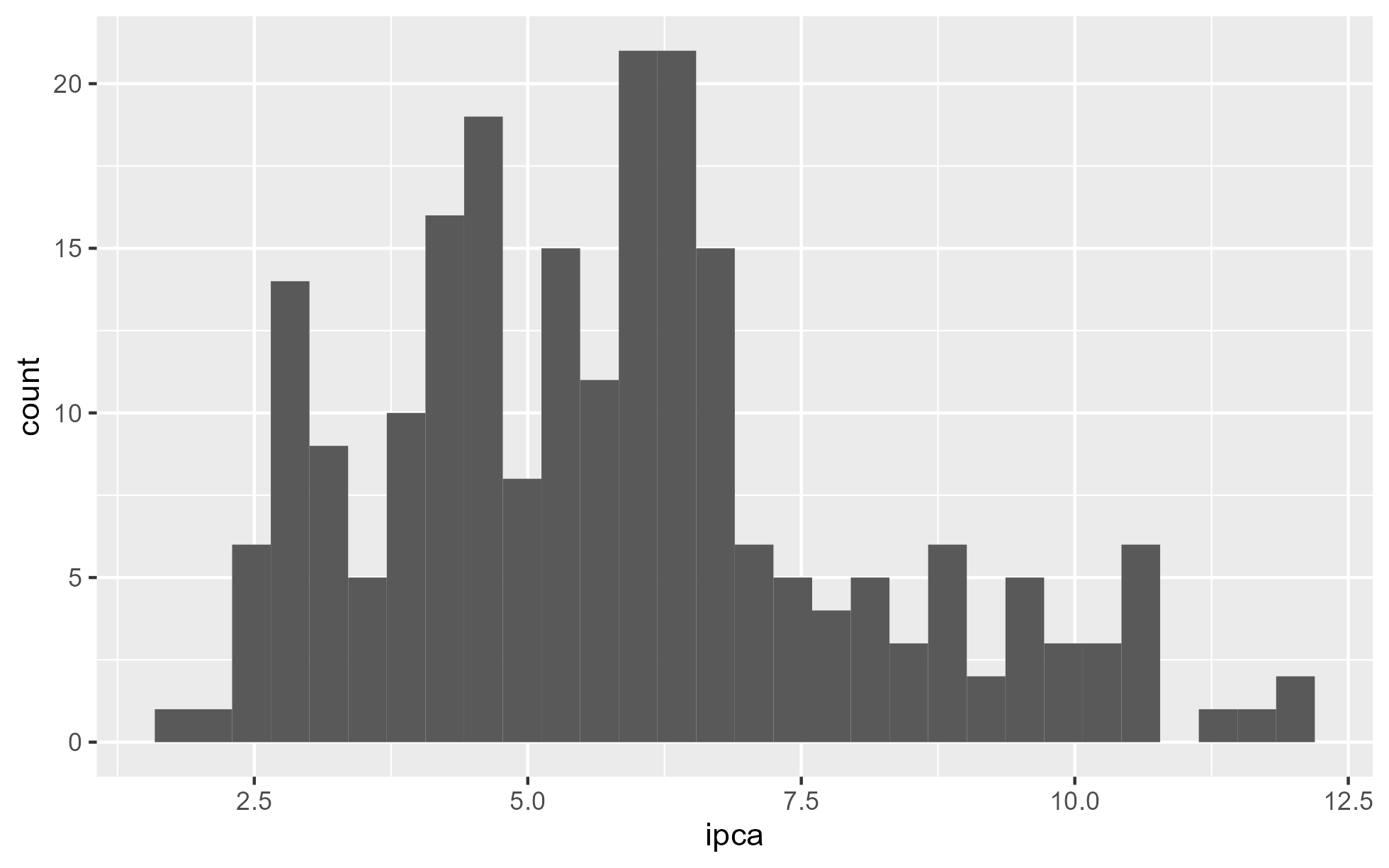
 Com o Histograma podemos analisar a distribuição dos dados. Vemos que os valores se encontram próximo do valor 5% e 6%, com uma cauda alongada para a direita, com pontos extremos positivos, significando menores frequências de acontecimento.
Com o Histograma podemos analisar a distribuição dos dados. Vemos que os valores se encontram próximo do valor 5% e 6%, com uma cauda alongada para a direita, com pontos extremos positivos, significando menores frequências de acontecimento.
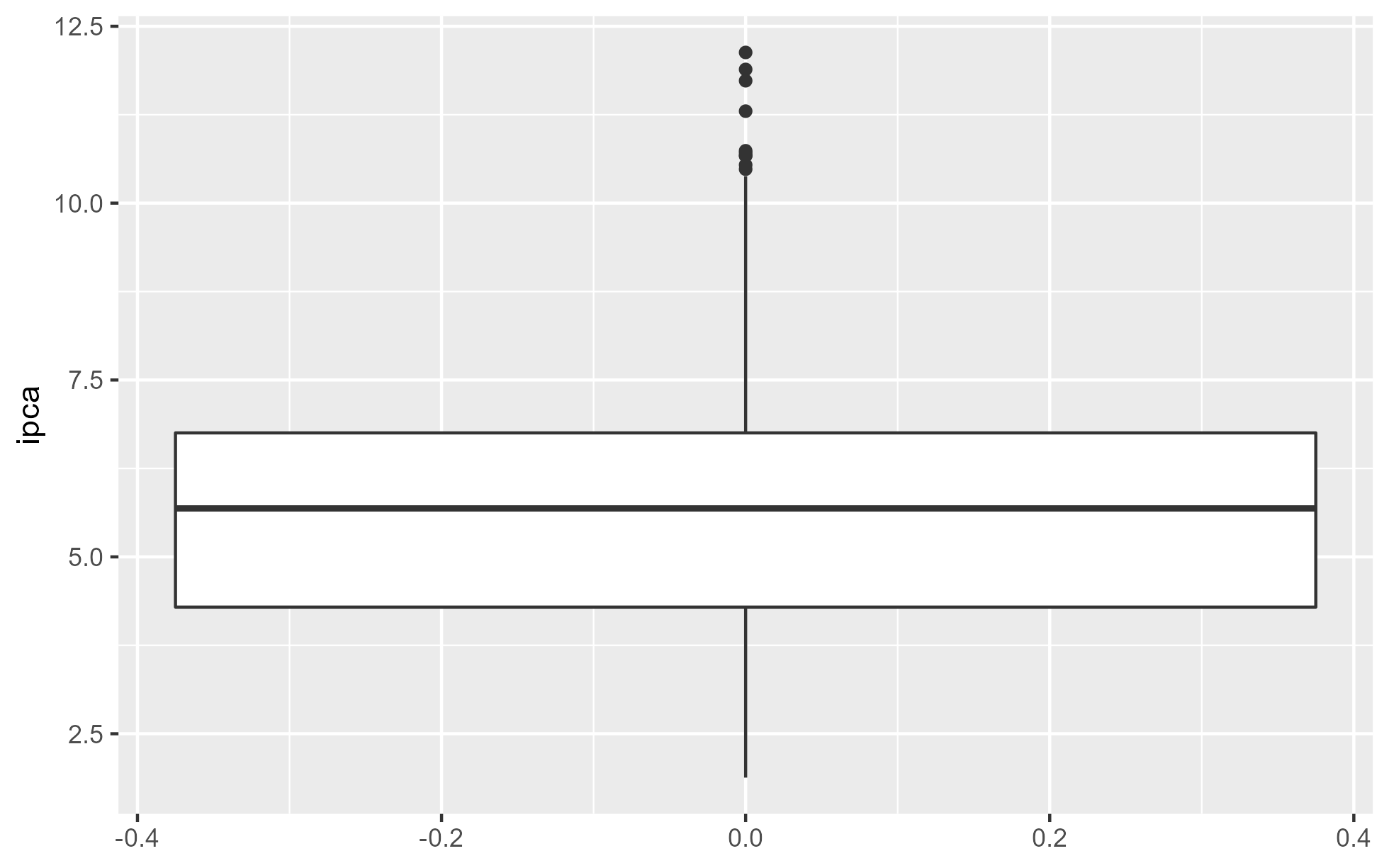
 E por fim, os cinco número em forma de gráfico: boxplot. Exibe exatamente o que temos na função summary().
E por fim, os cinco número em forma de gráfico: boxplot. Exibe exatamente o que temos na função summary().
Modelagem
Agora, vamos tentar entender algo sobre a inflação, o que afeta ela? Vamos recapitular a teoria econômica para isso.
Curva de Phillips
Em 1958, A. W. Phillips traçou um diagrama que mostrava a relação entre a taxa de inflação e a taxa de desemprego no Reino Unido para cada ano de 1861 a 1957. Logo após o trabalho de Phillips, Paul Samuelson e Robert Solow repetiram o exercício para o Estados Unidos e batizaram de curva de Phillips.
Rapidamente se tornou fundamental para o pensamento macroeconômico e para a política macroeconômica. Ela parecia implicar que os países poderiam escolher entre combinações diferentes de desemprego e inflação. Um país poderia ter um índice baixo de desemprego se estivesse disposto a tolerar uma inflação mais alta, ou atingir a estabilidade do nível de preços — inflação zero — se estivesse disposto a tolerar um desemprego mais alto.
A Curva de Phillips se tornou uma forma quase definitiva de entender a inflação em um país, entretanto, sofrendo diversas modificações ao longo do tempo, sendo aprimorada pela teoria econômica e por trabalhos empíricos.
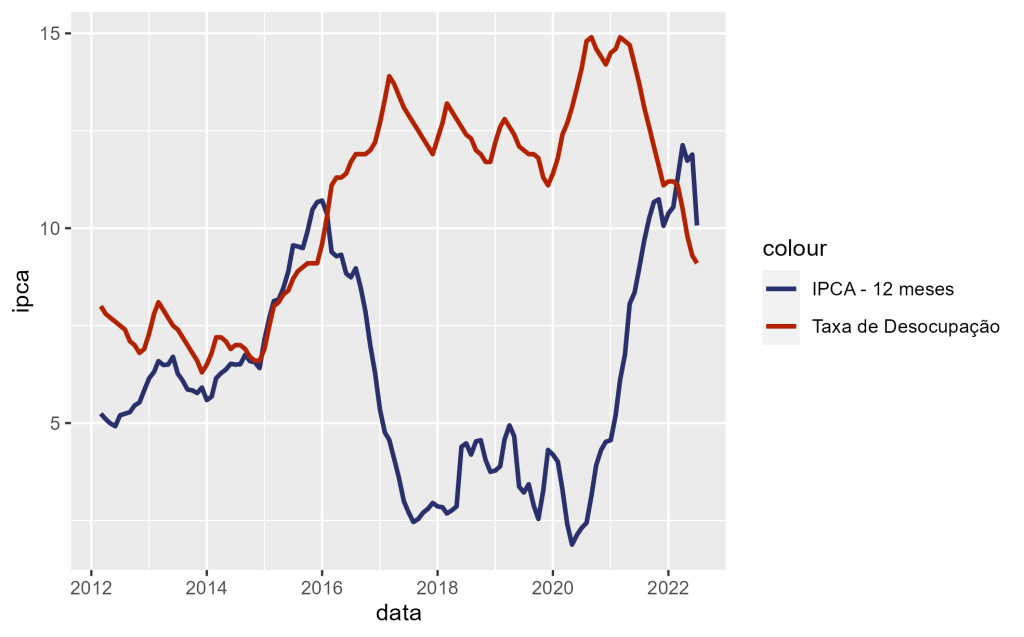
Para manter a análise simples, vamos utilizar a Curva de Phillips original, traçando a relação entre Inflação e Desemprego no Brasil. Para isso, devemos obter os dados da Taxa de Desocupação do Brasil através do SIDRA. Repetimos o mesmo código de coleta e tratamento, entretanto, utilizando a chave API do indicador da tabela 6381.
Juntamos os dois indicadores através da função inner_join(), que permite que os dados da coluna 'data' sejam 'colados' e que os dois data frames se juntem.
Por fim, podemos entender a relação dos dois indicadores através de um gráfico. Vejam abaixo, podemos entender que há uma relação.
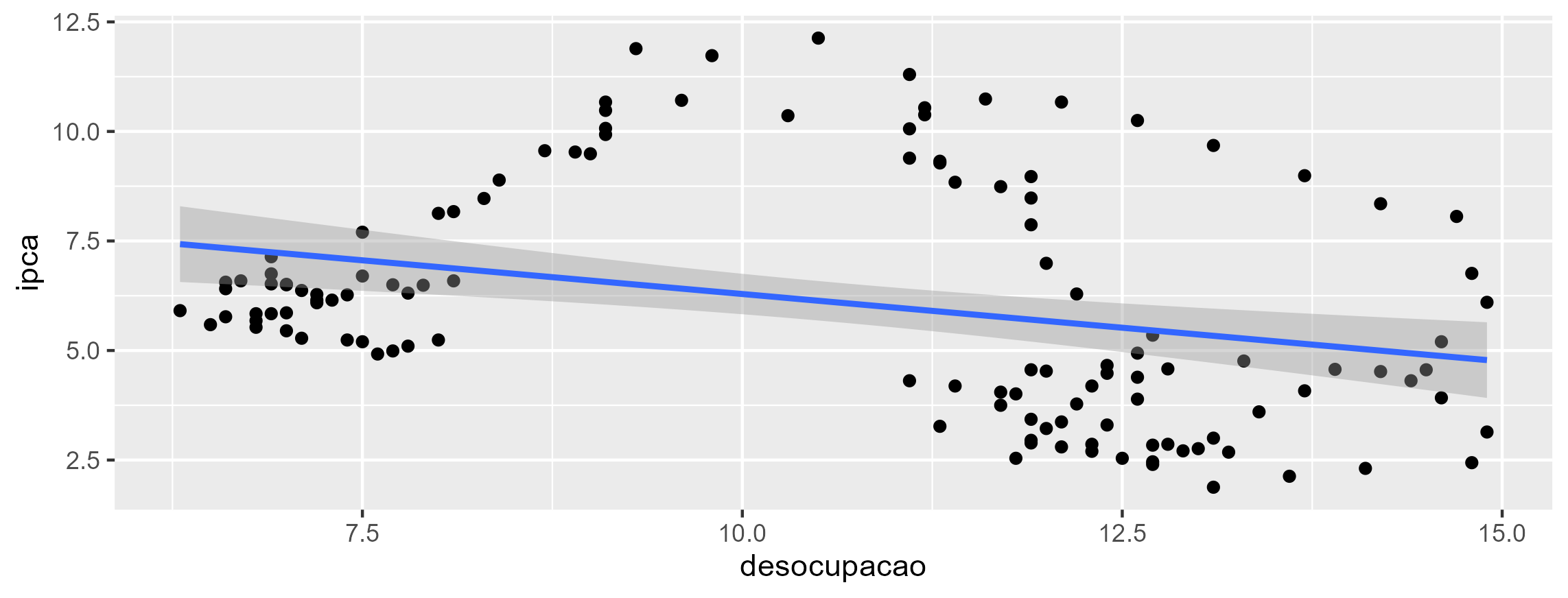
Utilizar gráficos podem nos ajudar a estabelecer a relação entre os dois indicadores, entretanto, podemos evoluir a análise utilizando uma regressão simples, em que a variável independente é a desocupação e variável dependente é o IPCA. O resultado vemos abaixo: o coeficiente é negativo, expressando a relação negativa entre os dois indicadores; temos uma relação estatística significante; e apesar disso, há pouca explicação da desocupação em relação a inflação, de acordo com o R²: apenas 0.09302..
Por fim, podemos entender a relação dos dois indicadores por meio de um gráfico de dispersão.
____________________________________________________
Quer aprender mais?
Veja nosso curso de Fundamentos de Análise de Dados, onde ensinamos todo o processo para aqueles que desejam entrar na área. O curso faz parte da trilha Ciência de Dados para Economia e Finanças.
___________________________________________________
Referências
BLANCHARD, Olivier. Macroeconomia. Pearson, 2017.
DORNBUSCH, Rudiger; FISCHER, Stanley; STARTZ, Richard. Macroeconomia. Bookman Editora, 2013.

