Quando estamos lidando com banco de dados relacionais, também trabalhamos com banco de dados normalizados, isto é, tabelas que possuem colunas chaves que remetem a outras tabelas. Com isso, podemos utilizar uma das principais funcionalidades do SQL: os JOINS.
Os JOINS são comandos que permitem juntar duas ou mais tabelas diferentes, quase como se fosse o PROCV do Excel, entretanto, mais poderoso.
Chamamos de JOINS no plural pois há diferentes tipos de JOINS, com cada comando permitindo executar uma forma de juntar os dados. Vamos começar falando sobre o INNER JOIN.
INNER JOIN
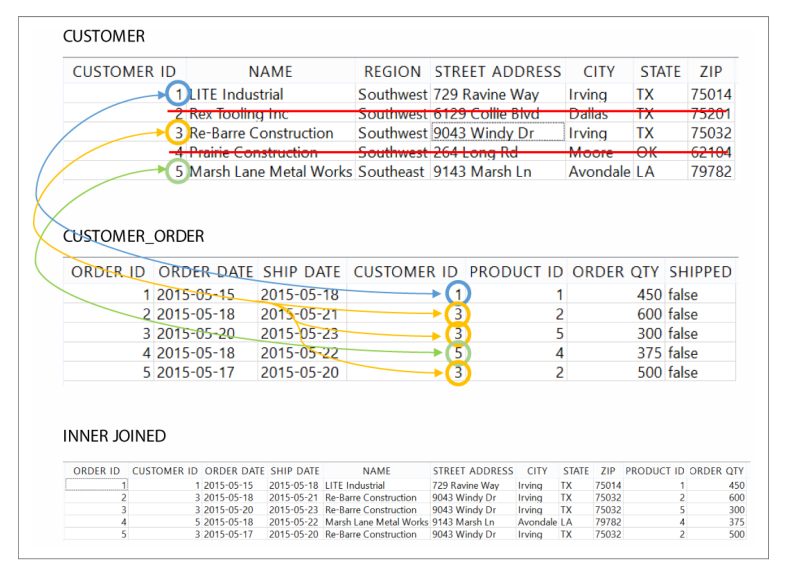
O INNER JOIN basicamente junta todas as observações em comum das duas colunas das duas tabelas.
Vamos abrir o arquivo rexon_metals e utilizar o comando no SQL editor.
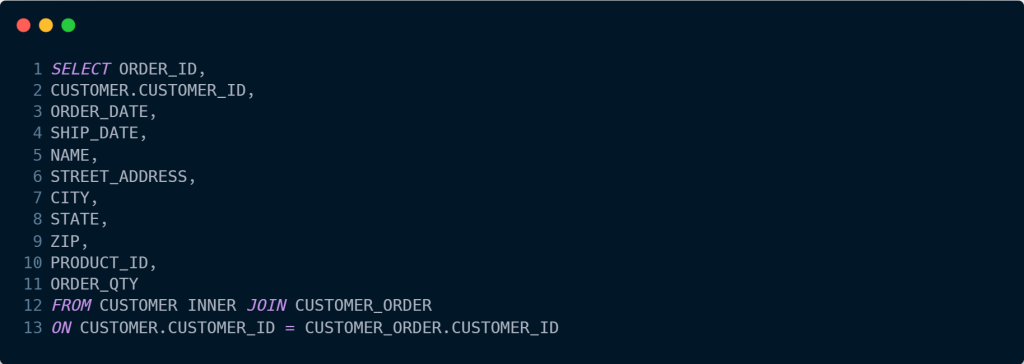
 No código acima, consultamos os campos das tabelas CUSTOMER e CUSTOMER_ORDER, isso ocorre pois estamos realmente selecionando todas as colunas a partir de uma união das duas tabelas.
No código acima, consultamos os campos das tabelas CUSTOMER e CUSTOMER_ORDER, isso ocorre pois estamos realmente selecionando todas as colunas a partir de uma união das duas tabelas.
Primeiro, ao selecionar as colunas de ambas as tabelas, temos apenas uma única diferença: como há duas colunas com o mesmo nome, devemos referenciar de qual estamos utilizando, portanto, o uso de CUSTOMER.CUSTOMER_ID.
A questão principal aqui é de onde executamos a união, no caso, sendo em conjunto com o comando FROM, referenciando a tabela principal e em seguida a tabela a ser juntada com INNER JOIN.
O resultado será que todas as observações em comum das duas tabelas nas duas colunas serão juntadas. E se houver uma observação em uma tabela e na outra não? Ela será excluída da query!
Nós devemos especificar que queremos igualar as duas colunas de ambas as tabelas, por isso, utilizamos ON CUSTOMER.CUSTOMER_ID = CUSTOMER_ORDER.CUSTOMER_ID.
LEFT JOIN
Se analisarmos os resultados da junção por meio do INNER JOIN, veremos que algumas chaves foram excluídas, obviamente. Entretanto, caso não queiramos que isso tenha acontecido, poderíamos utilizar outros tipos de JOINS, como no caso, o LEFT JOIN.
A diferença do LEFT JOIN é que ao invés de juntar dados iguais em ambas as tabelas, a junção se dá inteiramente pelos dados da tabela referenciada à esquerda do comando.
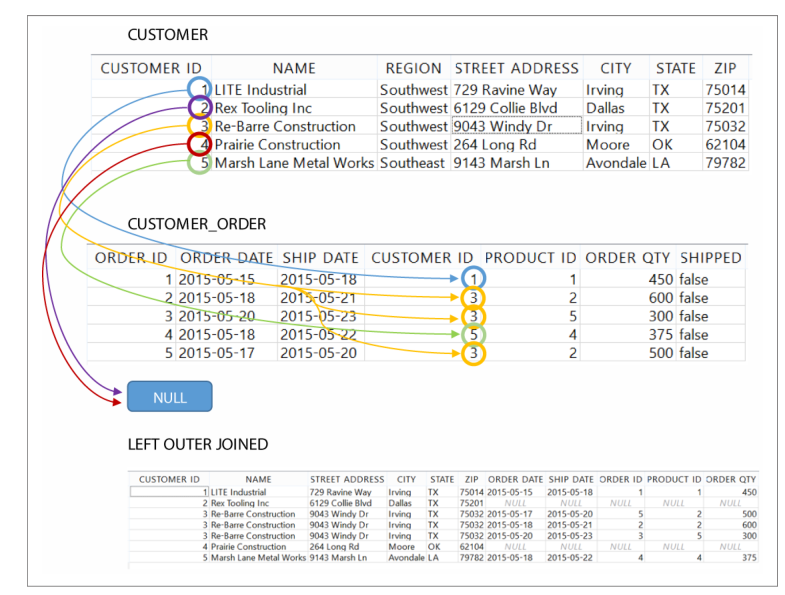 O resultado será a junção com base em CUSTOMER, e suas chaves agora aparecerão na query, entretanto, os valores de CUSTOMER_ID que não possuem uma chave igual apareceram como NULL.
O resultado será a junção com base em CUSTOMER, e suas chaves agora aparecerão na query, entretanto, os valores de CUSTOMER_ID que não possuem uma chave igual apareceram como NULL.
RIGHT JOIN
O RIGHT JOIN é semelhante ao LEFT JOIN, a única diferença é que há uma mudança da direção de qual tabela utilizar no comando. Ao invés da esquerda, como no LEFT JOIN, utiliza a da direita.
OUTER JOIN
Permite incluir todos os registros de ambos as tabelas em uma junção, como se fosse a operação de LEFT e RIGHT JOIN simultaneamente.
*Tanto RIGHT quanto OUTER não são suportados pelo SQLite.
Juntando múltiplas tabelas
Até então tivemos relações entre duas tabelas: CUSTOMER e CUSTOMER_ORDER, entretanto, é possível relacionar mais uma tabela, PRODUCT, que contém a coluna PRODUCT_ID possibilitando relacionar também com CUSTOMER_ORDER.
Agora temos não somente os dados dos clientes, mas também possuímos os dados dos produtos. Por esse motivo os JOINS são extremamente poderosos com um banco de dados relacional: permitem que haja diferentes tabelas em sistemas gerenciadores de bancos de dados que podem ser juntadas por meio dos comandos.
____________________________________________________
Quer aprender mais?
Veja nosso curso de SQL para Economia e Finanças, onde ensinamos todo o processo para aqueles que desejam entrar na área. O curso faz parte da trilha Ciência de Dados para Economia e Finanças.
_________________________________________
Referências
Nield, Thomas. Getting Started with SQL: A Hands-On Approach for Beginners. O'Reilly Media, Inc., 2016.

