O acompanhamento de variáveis econômicas permite avaliar a conjuntura econômica de uma país. É possível realizar essa tarefa através de um método extremamente produtivo, sem perder tempo coletando os dados, realizando a construção de cálculos, gráficos e tabelas de forma manual: por meio da construção de um Dashboard automatizado. No post de hoje, vamos ensinar a como construir um Dashboard de Indicadores Macroeconômicos com o R.
Análise de Conjuntura e Variáveis Macroeconômicas
O objetivo de lidar com dados Macroeconômicos é verificar o comportamento e o ciclo econômico de um determinado país em um dado período tempo, afim de realizar comparações com a Teoria Macroeconômica, bem como analisar o efeito de políticas econômicas e eventos extremos.
A Variáveis Econômicas construídas por meio de estatísticas oficiais de entidades de países ou instituições permitem avaliar os dados necessários para se ter um Análise de Conjuntura.
Portanto, instituições financeiras, empresas e policymakers, entre outros agentes, necessitam do uso de Análise de Conjuntura de forma a avaliar o presente e projetar o futuro.
Qual o beneficio de um Dashboard?
Um Dashboard permite manter diversos gráficos, tabelas entre outras formas de visualização de gráficos em um único ou mais painel de forma interativa e dinâmica. A construção desse tipo de painel permite que o analista construa um sistema em que não somente tenha pronto de forma automática a construção de visualizações para realizar Análise de Conjuntura, bem como haja a coleta automática de dados por meio deste sistema.
Conheça nosso Curso de Análise de Conjuntura usando o R e aprenda a construir esse tipo de análise.
Construindo um Dashboard de Mercado de trabalho com o R
Mas como construir um Dashboard? Aqui na Análise Macro ensinamos nossos alunos a construírem Dashboard de diversas variáveis Macroeconômicas, seja do Mercado de Trabalho, Mercado de Crédito, Inflação, Política Fiscal, Política Monetária, Setor Externo, Economia Internacional e Nível de Atividade. Tudo isso é encontrado no curso Análise de Conjuntura com o R.
No post de hoje, vamos ensinar a construir um Dashboard de Mercado de Trabalho. Os passos seguiram abaixo, o objetivo será construir um projeto no R, um arquivo .R, e um arquivo {flexdashboard}.
Arquivo .R contendo a Coleta e Tratamento de Dados
O arquivo .R será utilizado para definir toda a base de coleta de dados do Dashboard. A separação do back com o front (coleta, tratamento e cálculo com a parte visual) é útil não somente como forma de organização, como também é útil para a utilização do Github Actions para tornar o Dashboard automatizado, com coletas de dados programadas, mas isso fica para outro post.
Vamos começar criando o arquivo .R. Vejamos o processo de coleta abaixo.
library(PNADcIBGE)
library(dplyr)
library(tidyr)
library(sidrar)
library(rvest)
library(xml2)
library(httr)
library(openssl)
### Funções e objetos úteis
# Manter atualização automática de dados diária?
atualiza <- TRUE
# Tratar dados da PNADC-Mensal
clean_pnadcm <- function(data, id) {
data %>%
dplyr::select(
date = "Trimestre M\u00f3vel (C\u00f3digo)",
value = "Valor"
) %>%
dplyr::mutate(
date = lubridate::ym(date),
variable = id
) %>%
dplyr::as_tibble()
}
# Criar função para coletar, tratar e salvar dados
get_data <- function(update_data) {
if (update_data) {
## Parâmetros e códigos para coleta de dados
parametros <- list(
# Pessoas de 14+ anos (Mil pessoas): ocupados/desocupados na Força de trabalho
api_ocupados_desocupados = "/t/6318/n1/all/v/1641/p/all/c629/all",
# Taxa de Desocupação (%)
api_tx_desocupacao = "/t/6381/n1/all/v/4099/p/all/d/v4099%201",
# Nível de Ocupação (%)
api_nivel_ocupacao = "/t/6379/n1/all/v/4097/p/all/d/v4097%201",
# Taxa de Participação na Força de trabalho (%)
api_tx_participacao = "/t/5944/n1/all/v/4096/p/all/d/v4096%201",
# Ocupação por Categorias (Mil pessoas): posição na ocupação e categoria do emprego
api_categorias = "/t/6320/n1/all/v/4090/p/all/c11913/31722,31723,31724,31727,31731,96170,96171",
# Grupos de Atividades (Mil pessoas)
api_grupos = "/t/6323/n1/all/v/4090/p/all/c693/allxt",
# Rendimento médio real e nominal de todos os trabalhos habitualmente recebidos por mês (R$)
api_rendimento = "/t/6390/n1/all/v/5929,5933/p/all",
# Massa de rendimento, real e nominal, de todos os trabalhos habitualmente recebidos por mês (R$ milhões)
api_massa = "/t/6392/n1/all/v/6288,6293/p/all",
# Saldo do Novo CAGED (pessoas)
api_caged = "http://ipeadata.gov.br/api/odata4/ValoresSerie(SERCODIGO='CAGED12_SALDON12')",
# Microdados da PNADC-T (último trimestre disponível)
api_pnadc_dates = xml2::read_html("https://sidra.ibge.gov.br/home/pnadct/brasil") %>%
rvest::html_nodes(".titulo-aba") %>%
rvest::html_text() %>%
stringr::str_extract("(Divulgação Trimestral) - \\d{1}. trimestre \\d{4}") %>%
dplyr::lst(
quarter = stringr::str_extract(., "\\d{1}") %>% as.numeric(),
year = stringr::str_extract(., "\\d{4}") %>% as.numeric()
),
# Query variables
api_pnadc_variables = c("Ano", "Trimestre", "UF", "V1028", "VD4002")
)
## Coleta dos dados
# Pessoas de 14+ anos (Mil pessoas): ocupados/desocupados na Força de trabalho
raw_ocupados_desocupados <- sidrar::get_sidra(api = parametros$api_ocupados_desocupados)
# Taxa de Desocupação (%)
raw_tx_desocupacao <- sidrar::get_sidra(api = parametros$api_tx_desocupacao)
# Nível de Ocupação (%)
raw_nivel_ocupacao <- sidrar::get_sidra(api = parametros$api_nivel_ocupacao)
# Taxa de Participação na Força de trabalho (%)
raw_tx_participacao <- sidrar::get_sidra(api = parametros$api_tx_participacao)
# Ocupação por Categorias (Mil pessoas)
raw_categorias <- sidrar::get_sidra(api = parametros$api_categorias)
# Grupos de Atividades (Mil pessoas)
raw_grupos <- sidrar::get_sidra(api = parametros$api_grupos)
# Rendimento médio real e nominal de todos os trabalhos habitualmente recebidos por mês (R$)
raw_rendimento <- sidrar::get_sidra(api = parametros$api_rendimento)
# Massa de rendimento, real e nominal (R$ milhões)
raw_massa <- sidrar::get_sidra(api = parametros$api_massa)
# Saldo do Novo CAGED
#raw_caged <- ipeadatar::ipeadata(code = parametros$api_caged)
raw_caged <- httr::GET(parametros$api_caged)
## Tratamento dos dados
# Pessoas de 14+ anos (Mil pessoas): ocupados/desocupados na Força de trabalho
ocupados_desocupados <- raw_ocupados_desocupados %>%
dplyr::select(
date = "Trimestre M\u00f3vel (C\u00f3digo)",
variable = "Condi\u00e7\u00e3o em rela\u00e7\u00e3o \u00e0 for\u00e7a de trabalho e condi\u00e7\u00e3o de ocupa\u00e7\u00e3o",
value = "Valor"
) %>%
dplyr::mutate(
date = lubridate::ym(date),
variable = dplyr::recode(
variable,
"Total" = "Popula\u00e7\u00e3o total (PIA)",
"For\u00e7a de trabalho" = "For\u00e7a de trabalho (PEA)",
"For\u00e7a de trabalho - ocupada" = "Ocupados",
"For\u00e7a de trabalho - desocupada" = "Desocupados",
"Fora da for\u00e7a de trabalho" = "Fora da for\u00e7a (PNEA)"
),
value = value / 1000 # converter em milhões de pessoas
) %>%
dplyr::as_tibble()
# Taxa de Desocupação (%)
tx_desocupacao <- raw_tx_desocupacao %>%
clean_pnadcm(id = "Taxa de Desocupa\u00e7\u00e3o")
# Nível de Ocupação (%)
nivel_ocupacao <- raw_nivel_ocupacao %>%
clean_pnadcm(id = "N\u00edvel de Ocupa\u00e7\u00e3o")
# Taxa de Participação na Força de trabalho (%)
tx_participacao <- raw_tx_participacao %>%
clean_pnadcm(id = "Taxa de Participa\u00e7\u00e3o")
# Juntar dados: Ocupados/Desocupados, Tx. Desocupação, Nível e Tx. Participação
resumo_pnadcm <- purrr::map_dfr(
.x = list(ocupados_desocupados, tx_desocupacao, nivel_ocupacao, tx_participacao),
~dplyr::bind_rows(.x)
) %>%
dplyr::mutate(variable = forcats::as_factor(variable))
# Ocupação por Categorias (Mil pessoas)
categorias <- raw_categorias %>%
dplyr::select(
date = "Trimestre M\u00f3vel (C\u00f3digo)",
variable = "Posi\u00e7\u00e3o na ocupa\u00e7\u00e3o e categoria do emprego no trabalho principal",
value = "Valor"
) %>%
dplyr::mutate(
date = lubridate::ym(date),
variable = stringr::str_remove_all(
variable,
"Empregado no setor privado, exclusive trabalhador dom\u00e9stico - "
) %>% dplyr::recode(
"com carteira de trabalho assinada" = "Empregado com carteira",
"sem carteira de trabalho assinada" = "Empregado sem carteira"
) %>%
forcats::as_factor(),
value = value / 1000 # converter em milhões de pessoas
) %>%
dplyr::as_tibble()
# Grupos de Atividades (Mil pessoas)
grupos <- raw_grupos %>%
dplyr::select(
date = "Trimestre M\u00f3vel (C\u00f3digo)",
variable = "Grupamento de atividades no trabalho principal - PNADC",
value = "Valor"
) %>%
dplyr::mutate(
date = lubridate::ym(date),
variable = forcats::as_factor(variable),
value = value / 1000 # converter em milhões de pessoas
) %>%
dplyr::as_tibble()
# Rendimento médio real e nominal de todos os trabalhos habitualmente recebidos por mês (R$)
rendimento <- raw_rendimento %>%
dplyr::select(
date = "Trimestre M\u00f3vel (C\u00f3digo)",
variable = "Vari\u00e1vel",
value = "Valor"
) %>%
dplyr::mutate(
date = lubridate::ym(date),
variable = forcats::as_factor(variable) %>%
forcats::fct_recode(
"Rendimento nominal" = "Rendimento m\u00e9dio nominal de todos os trabalhos, habitualmente recebido por m\u00eas, pelas pessoas de 14 anos ou mais de idade, ocupadas na semana de refer\u00eancia, com rendimento de trabalho",
"Rendimento real" = "Rendimento m\u00e9dio real de todos os trabalhos, habitualmente recebido por m\u00eas, pelas pessoas de 14 anos ou mais de idade, ocupadas na semana de refer\u00eancia, com rendimento de trabalho"
)
) %>%
dplyr::as_tibble()
# Massa de rendimento, real e nominal (R$ milhões)
massa <- raw_massa %>%
dplyr::select(
date = "Trimestre M\u00f3vel (C\u00f3digo)",
variable = "Vari\u00e1vel",
value = "Valor"
) %>%
dplyr::mutate(
date = lubridate::ym(date),
value = value / 1000, # converter em R$ bilhões
variable = forcats::as_factor(variable) %>%
forcats::fct_recode(
"Massa de rendimento nominal" = "Massa de rendimento nominal de todos os trabalhos, habitualmente recebido por m\u00eas, pelas pessoas de 14 anos ou mais de idade, ocupadas na semana de refer\u00eancia, com rendimento de trabalho",
"Massa de rendimento real" = "Massa de rendimento real de todos os trabalhos, habitualmente recebido por m\u00eas, pelas pessoas de 14 anos ou mais de idade, ocupadas na semana de refer\u00eancia, com rendimento de trabalho"
)
) %>%
dplyr::as_tibble()
# Saldo do Novo CAGED
# caged <- raw_caged %>%
# dplyr::select(date, value) %>%
# dplyr::mutate(value = value / 1000) %>% # converter em milhares
# dplyr::as_tibble()
caged <- httr::content(raw_caged)[[2]] %>%
dplyr::bind_rows() %>%
dplyr::select(
"date" = `VALDATA`,
"value" = `VALVALOR`
) %>%
dplyr::mutate(
date = lubridate::as_date(date),
value = value / 1000 # converter em milhares
)
# Criar lista de nomes dos estados do Brasil para gráfico
states <- tibble(
states = c(
"Rondônia", "Acre", "Amazonas", "Roraima", "Pará", "Amapá",
"Tocantins", "Maranhão", "Piauí", "Ceará", "Rio Grande do Norte",
"Paraíba", "Pernambuco", "Alagoas", "Sergipe", "Bahia",
"Minas Gerais", "Espírito Santo", "Rio de Janeiro", "São Paulo",
"Paraná", "Santa Catarina", "Rio Grande do Sul",
"Mato Grosso do Sul", "Mato Grosso", "Goiás", "Distrito Federal"
),
code = c(
"RO", "AC", "AM", "RR", "PA", "AP", "TO", "MA", "PI",
"CE", "RN", "PB", "PE", "AL", "SE", "BA", "MG", "ES",
"RJ", "SP", "PR", "SC", "RS", "MS", "MT", "GO", "DF"
)
)
## Salvar dados
# Remover objetos desnecessários
rm(
list = c(lsf.str()),
envir = environment()
)
# Salvar
save(
list = ls(),
file = file.path("dados.Rdata"),
envir = environment()
)
}
}
get_data(update_data = atualiza)
O código permite coletar diversas variáveis úteis para avaliar o Mercado de Trabalho Brasileiro, isso tudo controlado por meio de uma função que salva os dados dentro de um arquivo .Rdata, que será carregado no arquivo .Rmd para criação de gráficos.
Arquivo .Rmd criado com flexdashboard para construir o visual do Dashboard
A tarefa agora será criar um arquivo .Rmd para constituir o Dashboard. Aqui utilizaremos o {flexdashboard}. Para aqueles que não possuem o pacote, é necessário instalar e criar um arquivo por meio de New File -> R Markdown -> From Template -> Flex Dashboard.
Conheça nosso Curso de Análise de Conjuntura usando o R e aprenda a construir esse tipo de análise.
Uma vez instalado segue-se o código abaixo. Cada bloco representa um chunk do arquivo .Rmd.
# Carregar pacotes library(rmarkdown) library(flexdashboard) library(shiny) library(dplyr) library(ggplot2) library(lubridate) library(scales) library(rsconnect)
### Funções e objetos úteis # Cores para gráficos e tabelas colors <- c( blue = "#282f6b", red = "#b22200", yellow = "#eace3f", green = "#224f20", purple = "#5f487c", orange = "#b35c1e", turquoise = "#419391", green_two = "#839c56", light_blue = "#3b89bc", gray = "#666666" ) # Fonte para gráficos e tabelas foot_ibge <- "Fonte: analisemacro.com.br com dados do Sidra/IBGE."
# Carrega dados salvdos
load("dados.Rdata", envir = .GlobalEnv)
Visão Geral {data-icon="fa-signal"} ===================================== Row {.sidebar data-width=200} -------------------------------------
# Texto informativo na barra lateral
shiny::strong(shiny::h3("Sobre"))
shiny::h5("Essa dashboard permite o monitoramento do Mercado de Trabalho brasileiro usando o ecossistema Shiny para a criação de aplicações web dinâmicas, com dados do IBGE.")
shiny::h5("Desenvolvimento: Análise Macro.")
Row
-------------------------------------
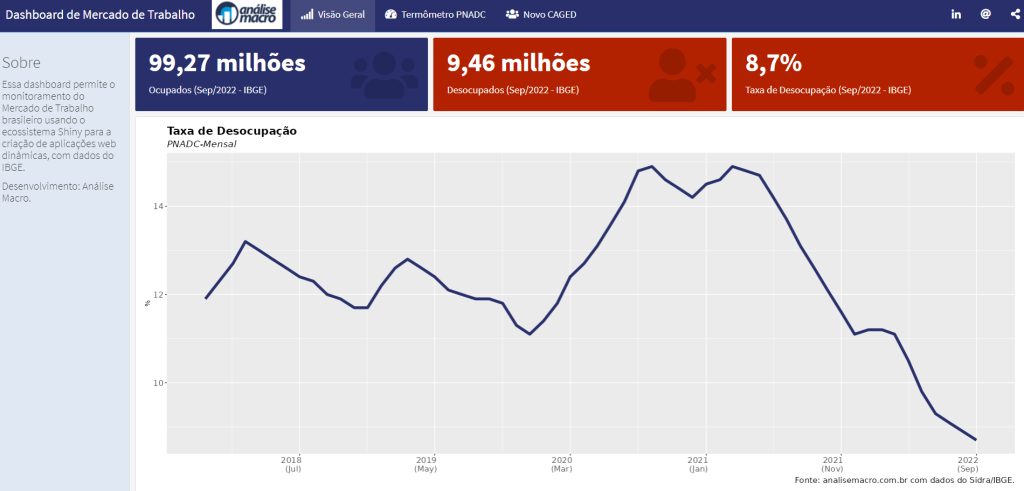
### Ocupados (`r format(max(ocupados_desocupados$date), "%b/%Y")` - IBGE)
# Criar Value Box ocupados_desocupados %>% dplyr::filter(variable == "Ocupados" & date == max(date)) %>% dplyr::mutate(value = paste0(format(round(value, 2), decimal.mark = ","), " milhões")) %>% dplyr::pull(value) %>% flexdashboard::valueBox( value = ., icon = "fa-users", color = colors["blue"] )
### Desocupados (`r format(max(ocupados_desocupados$date), "%b/%Y")` - IBGE)
# Criar Value Box ocupados_desocupados %>% dplyr::filter(variable == "Desocupados" & date == max(date)) %>% dplyr::mutate(value = paste0(format(round(value, 2), decimal.mark = ","), " milhões")) %>% dplyr::pull(value) %>% flexdashboard::valueBox( value = ., icon = "fa-user-times", color = colors["red"] )
### Taxa de Desocupação (`r format(max(tx_desocupacao$date), "%b/%Y")` - IBGE)
tx_desocupacao %>%
dplyr::filter(date == max(date)) %>%
dplyr::mutate(value = format(value, decimal.mark = ",") %>% paste0("%")) %>%
dplyr::pull(value) %>%
flexdashboard::valueBox(
value = .,
icon = "fa-percentage",
color = dplyr::case_when(
. < mean(tx_desocupacao$value) ~ colors["green"],
. > mean(tx_desocupacao$value) ~ colors["red"]
)
)
Row
-------------------------------------
### Gráfico da Taxa de Desocupação {.no-title}
# Gerar gáfico
shiny::renderPlot({
resumo_pnadcm %>%
dplyr::filter(
variable == "Taxa de Desocupação",
date >= Sys.Date() %m-% lubridate::years(5)
) %>%
ggplot2::ggplot(ggplot2::aes(x = date, y = value, colour = variable)) +
ggplot2::geom_line(size = 2) +
ggplot2::scale_x_date(
breaks = scales::date_breaks("10 months"),
labels = scales::date_format("%Y\n(%b)")
) +
ggplot2::scale_colour_manual(values = unname(colors)) +
ggplot2::theme(
legend.position = "none",
plot.title = ggplot2::element_text(size = 16, face = "bold"),
plot.subtitle = ggplot2::element_text(size = 14, face = "italic"),
axis.text.x = ggplot2::element_text(hjust = 0.9),
axis.text = ggplot2::element_text(size = 12),
plot.caption = ggplot2::element_text(size = 12)
) +
ggplot2::labs(
x = NULL,
y = "%",
title = "Taxa de Desocupação",
subtitle = "PNADC-Mensal",
caption = foot_ibge
)
})
Termômetro PNADC {data-icon="fa-tachometer-alt"}
=====================================
Row {.tabset}
-------------------------------------
### Principais indicadores da PNADC
# Gerar gáfico
shiny::renderPlot({
resumo_pnadcm %>%
dplyr::group_by(variable) %>%
dplyr::filter(date >= Sys.Date() %m-% lubridate::years(5)) %>%
dplyr::ungroup() %>%
dplyr::mutate(
labels = dplyr::if_else(
variable %in% unique(resumo_pnadcm$variable)[1:5], "Milhões de pessoas", "%"
)
) %>%
ggplot2::ggplot(ggplot2::aes(x = date, y = value, colour = variable)) +
ggplot2::geom_line(size = 2) +
ggplot2::facet_wrap(~variable~labels, scales = "free_y") +
ggplot2::scale_y_continuous(labels = scales::label_number(accuracy = 1)) +
ggplot2::scale_x_date(
breaks = scales::date_breaks("15 months"),
labels = scales::date_format("%Y\n(%b)")
) +
ggplot2::scale_colour_manual(values = unname(colors)) +
ggplot2::theme(
legend.position = "none",
strip.text = ggplot2::element_text(size = 14, face = "bold"),
plot.title = ggplot2::element_text(size = 16, face = "bold"),
plot.subtitle = ggplot2::element_text(size = 14, face = "italic"),
axis.text.x = ggplot2::element_text(hjust = 0.9),
axis.text = ggplot2::element_text(size = 12),
strip.text.x = ggplot2::element_text(margin = margin(1, 0, 1, 0)),
plot.caption = ggplot2::element_text(size = 12)
) +
ggplot2::labs(
x = NULL,
y = NULL,
title = "Visão Geral do Mercado de Trabalho",
subtitle = "Indicadores da PNADC-Mensal",
caption = foot_ibge
)
})
### Ocupação por categorias
# Gerar gáfico
shiny::renderPlot({
categorias %>%
dplyr::group_by(variable) %>%
dplyr::filter(date >= Sys.Date() %m-% lubridate::years(5)) %>%
dplyr::ungroup() %>%
ggplot2::ggplot(ggplot2::aes(x = date, y = value, colour = variable)) +
ggplot2::geom_line(size = 2) +
ggplot2::facet_wrap(~variable, scales = "free_y") +
ggplot2::scale_x_date(
breaks = scales::date_breaks("15 months"),
labels = scales::date_format("%Y\n(%b)")
) +
ggplot2::scale_colour_manual(values = unname(colors)) +
ggplot2::theme(
legend.position = "none",
strip.text = ggplot2::element_text(size = 14, face = "bold"),
plot.title = ggplot2::element_text(size = 16, face = "bold"),
plot.subtitle = ggplot2::element_text(size = 14, face = "italic"),
axis.text = ggplot2::element_text(size = 12),
axis.text.x = ggplot2::element_text(hjust = 0.9),
axis.title.y = ggplot2::element_text(size = 12),
plot.caption = ggplot2::element_text(size = 12)
) +
ggplot2::labs(
x = NULL,
y = "Milhão de pessoas",
title = "Categorias do emprego de pessoas ocupadas",
subtitle = "Indicadores da PNADC-Mensal",
caption = foot_ibge
)
})
### Grupos de atividades
# Gerar gáfico
shiny::renderPlot({
grupos %>%
dplyr::group_by(variable) %>%
dplyr::filter(date >= Sys.Date() %m-% lubridate::years(5)) %>%
dplyr::ungroup() %>%
ggplot2::ggplot(ggplot2::aes(x = date, y = value, colour = variable)) +
ggplot2::geom_line(size = 2) +
ggplot2::facet_wrap(
~variable,
scales = "free_y",
ncol = 3,
labeller = ggplot2::label_wrap_gen(41)
) +
ggplot2::scale_x_date(
breaks = scales::date_breaks("15 months"),
labels = scales::date_format("%Y\n(%b)")
) +
ggplot2::scale_colour_manual(values = unname(colors)) +
ggplot2::theme(
legend.position = "none",
strip.text = ggplot2::element_text(size = 14, face = "bold"),
plot.title = ggplot2::element_text(size = 16, face = "bold"),
plot.subtitle = ggplot2::element_text(size = 14, face = "italic"),
axis.text = ggplot2::element_text(size = 12),
axis.text.x = ggplot2::element_text(hjust = 0.9),
axis.title.y = ggplot2::element_text(size = 12),
plot.caption = ggplot2::element_text(size = 12)
) +
ggplot2::labs(
x = NULL,
y = "Milhão de pessoas",
title = "Grupos de atividade",
subtitle = "Indicadores da PNADC-Mensal",
caption = foot_ibge
)
})
### Rendimentos
# Gerar gáfico
shiny::renderPlot({
rendimento %>%
dplyr::group_by(variable) %>%
dplyr::filter(date >= Sys.Date() %m-% lubridate::years(5)) %>%
dplyr::ungroup() %>%
ggplot2::ggplot(ggplot2::aes(x = date, y = value, colour = variable)) +
ggplot2::geom_line(size = 2) +
ggplot2::scale_y_continuous(labels = scales::label_number(accuracy = 1)) +
ggplot2::scale_x_date(
breaks = scales::date_breaks("15 months"),
labels = scales::date_format("%Y\n(%b)")
) +
ggplot2::scale_colour_manual(NULL, values = unname(colors)) +
ggplot2::theme(
legend.position = "bottom",
plot.title = ggplot2::element_text(size = 16, face = "bold"),
plot.subtitle = ggplot2::element_text(size = 14, face = "italic"),
axis.text = ggplot2::element_text(size = 12),
axis.text.x = ggplot2::element_text(hjust = 0.9),
axis.title.y = ggplot2::element_text(size = 12),
legend.text = ggplot2::element_text(size = 12),
plot.caption = ggplot2::element_text(size = 12)
) +
ggplot2::labs(
x = NULL,
y = "R$",
title = "Rendimento médio real e nominal",
subtitle = "Indicadores da PNADC-Mensal",
caption = foot_ibge
)
})
### Massa de rendimentos
# Gerar gáfico
shiny::renderPlot({
massa %>%
dplyr::group_by(variable) %>%
dplyr::filter(date >= Sys.Date() %m-% lubridate::years(5)) %>%
dplyr::ungroup() %>%
ggplot2::ggplot(ggplot2::aes(x = date, y = value, colour = variable)) +
ggplot2::geom_line(size = 2) +
ggplot2::scale_y_continuous(labels = scales::label_number(accuracy = 1)) +
ggplot2::scale_x_date(
breaks = scales::date_breaks("15 months"),
labels = scales::date_format("%Y\n(%b)")
) +
ggplot2::scale_colour_manual(NULL, values = unname(colors)) +
ggplot2::theme(
legend.position = "bottom",
plot.title = ggplot2::element_text(size = 16, face = "bold"),
plot.subtitle = ggplot2::element_text(size = 14, face = "italic"),
axis.text = ggplot2::element_text(size = 12),
axis.text.x = ggplot2::element_text(hjust = 0.9),
axis.title.y = ggplot2::element_text(size = 12),
legend.text = ggplot2::element_text(size = 12),
plot.caption = ggplot2::element_text(size = 12)
) +
ggplot2::labs(
x = NULL,
y = "R$ bilhões",
title = "Massa de rendimento real e nominal",
subtitle = "Indicadores da PNADC-Mensal",
caption = foot_ibge
)
})
Novo CAGED {data-icon="fa-users"}
=====================================
Row
-------------------------------------
### Saldo do Novo CAGED {.no-title}
# Gerar gáfico
shiny::renderPlot({
# Gerar gáfico
caged %>%
dplyr::filter(date >= Sys.Date() %m-% lubridate::years(5)) %>%
ggplot2::ggplot(ggplot2::aes(x = date, y = value)) +
ggplot2::geom_bar(
fill = ifelse(caged$value > 0, colors["blue"], colors["red"]),
stat = "identity"
) +
ggplot2::geom_text(
ggplot2::aes(y = value + sign(value), label = round(value, 0)),
position = ggplot2::position_dodge(width = 0.9),
vjust = ifelse(caged$value > 0, -0.5, 1.3),
size = 6,
colour = ifelse(caged$value > 0, colors["blue"], colors["red"]),
fontface = "bold"
) +
ggplot2::scale_y_continuous(
expand = ggplot2::expansion(mult = 0.1),
breaks = scales::breaks_extended(n = 6),
labels = scales::label_number(accuracy = 1)
) +
ggplot2::scale_x_date(
breaks = scales::date_breaks("2 months"),
labels = scales::date_format("%Y\n(%b)")
) +
ggplot2::theme(
plot.title = ggplot2::element_text(size = 16, face = "bold"),
plot.subtitle = ggplot2::element_text(size = 14, face = "italic"),
axis.text = ggplot2::element_text(size = 12),
axis.text.x = ggplot2::element_text(hjust = 0.9),
plot.caption = ggplot2::element_text(size = 12)
) +
ggplot2::labs(
x = NULL,
y = NULL,
title = "Saldo do Novo CAGED",
subtitle = "Diferença entre o total de admissões e demissões de empregados, em milhares",
caption = "Fonte: analisemacro.com.br com dados do Ministério da Economia."
)
})
Ao final, o resultado será um Dashboard semelhante ao da imagem.
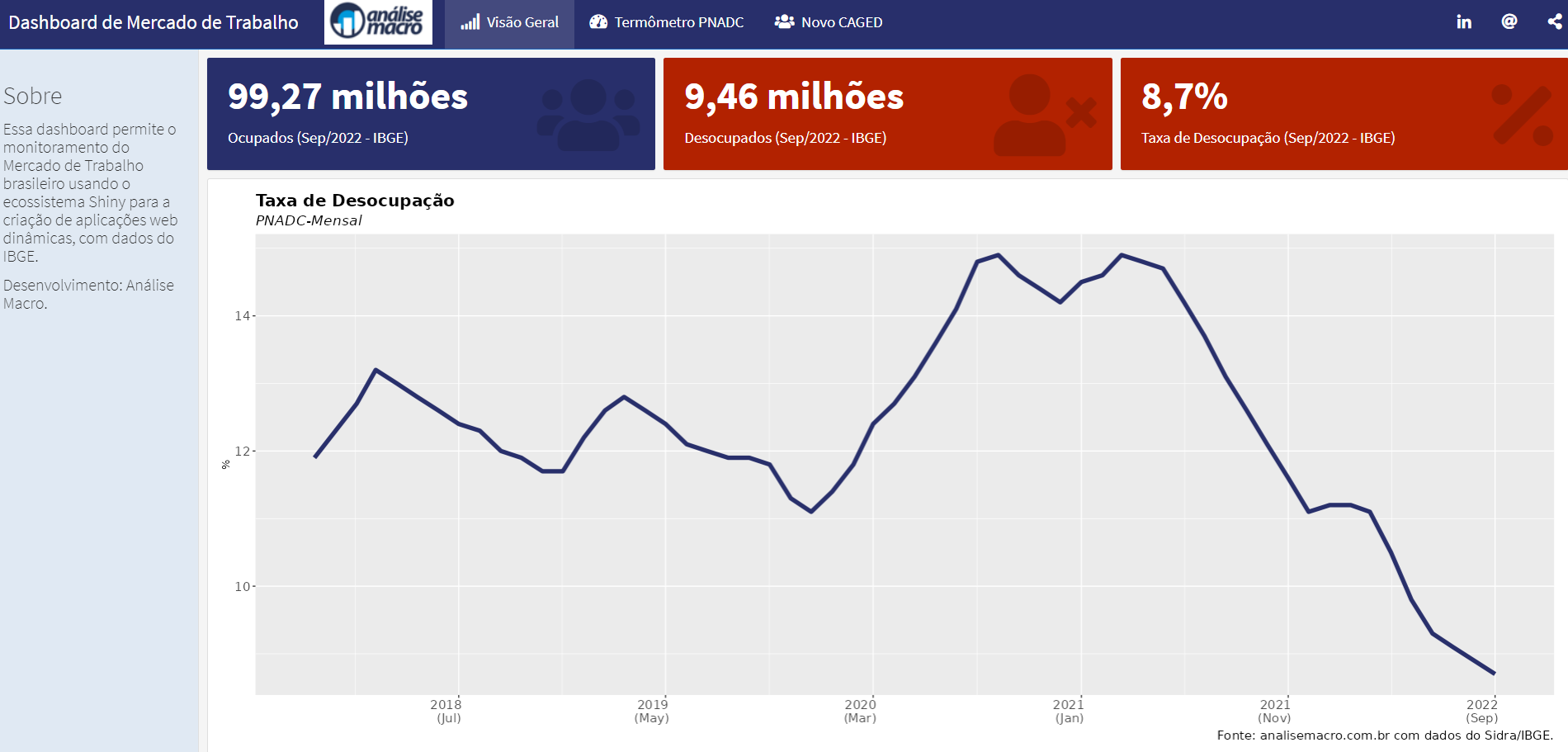
É possível acessar o Dashboard de Mercado de Trabalho da Análise Macro por meio do seguinte link.
Quer saber mais?
Veja a nossa trilha de Macroeconomia Aplicada.

